


Unlocking the Gates to Success: Dive into SQL Interview Questions from Leading MAANG Companies
Last Updated on February 12, 2024 by Editorial Team
Author(s): Kamireddy Mahendra
Originally published on Towards AI.
“Consistent practice is the key to unlocking success in clearing any coding interview.”
Concepts used: Window functions, CTE, Joins, Subqueries, and GROUP BY
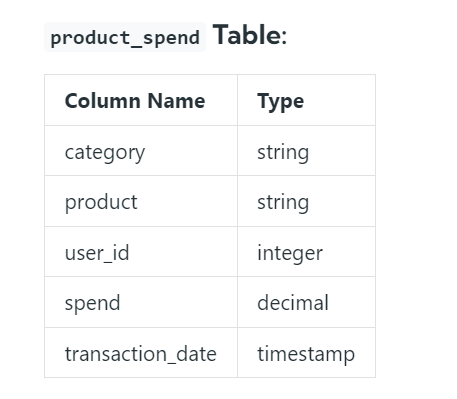
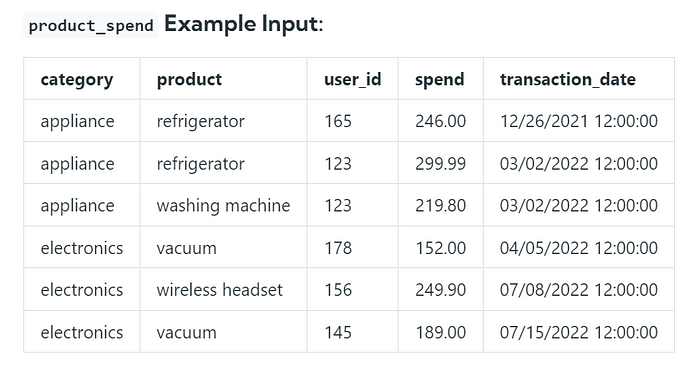
Q1. Assume you’re given a table containing data on Amazon customers and their spending on products in different categories, and write a query to identify the top two highest-grossing products within each category in the year 2022. The output should include the category, product, and total spend.
Solution Steps
Before solving any SQL Problem, it is important to understand the schema of a table, relationships, and data types used in the table. let’s get into the solution steps.
- It is given in date format in the table, and the solution is asked to be found based on the year. So, we need to extract the year from the table and filter the data as mentioned.
- Now we have the table with the year format of the date column as year as named. You can see in below code.
- Now we need to find the total spend as asked to find the top 2 highest total grossing by product and category. we
- We Can use window functions to prioritize the grossing, i.e., total spend amount by rank or dense rank. But we are not sure if is there any equal spending so it is better to use dense rank, I hope you know the advantage of using dense rank. It won’t skip any rank if there are any number of draws, right?
- Also, we should apply a filter to our required conditions here. It is the year, i.e., 2022, and we should also apply group since we have used an aggregation function like summing up the spend.
- Finally, we need to extract only the top two highest gross. We already ordered them in window functions in descending order. Therefore if we apply conditions like rank is less than or equal to 2 upon all we will get our required solution.
- You should understand that in each step, we are writing parts of queries by segregating the given problem and combining them using CTEs rather than subqueries here to make a fast execution of queries, and that is one of the optimizations in SQL. You can see the code in the below section.
with cte as (
select category,product,spend,
EXTRACT(year FROM transaction_date) yearr from product_spend
),
cte2 as (
select
category,product,SUM(spend) AS total_spend,
dense_rank() over (PARTITION BY category ORDER BY SUM(spend) DESC)
as rnk
FROM cte where
yearr = 2022
GROUP BY category, product
)
select
category, product,total_spend from cte2 where rnk<= 2;
Here is the expected sample output as I took the picture from my desktop. There are many ways to solve this problem. That is the best feature of SQL: there is no limit to solving a problem in a particular way. All the best.

Click Here to see the problem statement from Data Lemur.
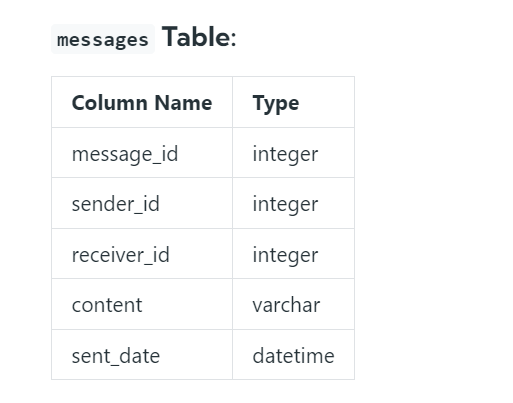
Q2. Write a query to identify the top 2 Power Users who sent the highest number of messages on Microsoft Teams in August 2022. Display the IDs of these 2 users along with the total number of messages they sent. Output the results in descending order based on the count of the messages.

Solution Steps
- It is an easy question asked in a Microsoft interview.
- we need to find the top 2 power users who sent more messages in August in 2022.
- We can easily solve this by using a simple aggregate function i.e. count function, we will count the message id and then we need to group by them with senders who have their sender IDs.
- Before doing the group we need to filter the data to the required month and year.
- As mentioned, to return the two users, we use the limit function as limit 2. We need to ensure that order by several messages is in descending order.
- Finally, return the columns we want by using a select statement.
select sender_id, count(message_id) as number_of_messages
from messages
where EXTRACT(month from sent_date)=8 and
EXTRACT(year from sent_date)=2022
GROUP BY sender_id order by number_of_messages desc limit 2

Click Here to see the problem statement from Data Lemur.
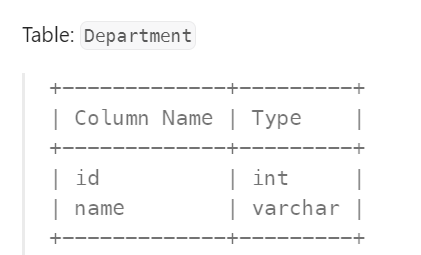
Q3. A company’s executives are interested in seeing who earns the most money in each of the company’s departments. A high earner in a department is an employee who has a salary in the top three unique salaries for that department.
Write a solution to find the employees who are high earners in each of the departments. Return the result table in any order.

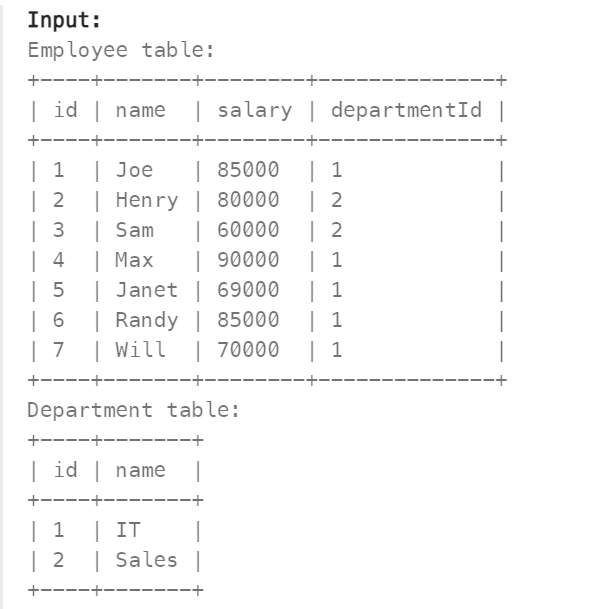
solution steps
- Initially, we need to understand the primary and foreign keys in a given table. when we have multiple tables.
- Join them based on their foreign key primary key relation. So that we will combine the features of both tables.
- Then it is asked to find the top three salaries earned by each department so we can use the window function especially dense rank to find their rankings with partition by each department.
- Finally, we will filter them with the top 3 that we can get by filtering the rank less than or equal to 3. SQL script and output result can be observed in the below section.
select department, employee, salary from (
select d.name as department,e.name as employee, e.salary as salary,
dense_rank() over( partition by d.name order by salary desc) as rnk
from employee e
join department d on e.departmentid=d.id)a
where rnk <=3

Click Here to see the problem statement from the Leet code.
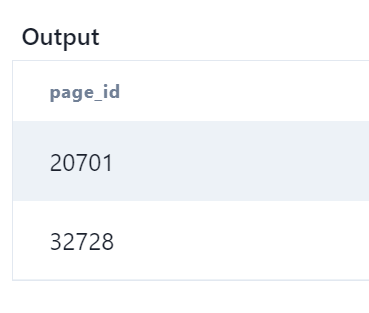
Q4. Assume you’re given two tables containing data about Facebook Pages and their respective likes (as in “Like a Facebook Page”).
Write a query to return the IDs of the Facebook pages that have zero likes. The output should be sorted in ascending order based on the page IDs.

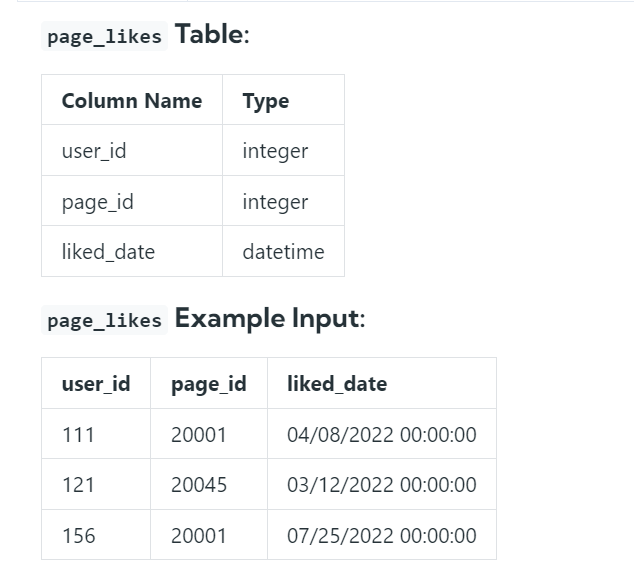
Solution Steps
- This is an easy problem that was asked on Facebook. we need to find the page ID that doesn’t have any likes.
- We can easily solve this by using not in statements.
- Initially, we will select the ID from the pages table and consider the page that is not in the page likes table.
- In two single steps, we can solve this problem. You can the code in below mentioned.
SELECT page_id from pages where page_id not IN(
select page_id from page_likes)
Click Here to see the problem statement from Data Lemur.
I hope this is helpful a bit in solving SQL problems based on those conditions as I have mentioned at the beginning.
Kindly support me by clapping or by giving feedback, which helps me to work on delivering quality content and gives me motivation to move forward to share more content.
Follow me to catch any updates from me.
Thank you:)
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

