


The Bumpy Road Ahead: AI and Copyright Law in Early 2024
Last Updated on January 12, 2024 by Editorial Team
Author(s): Tabrez Syed
Originally published on Towards AI.
The sweeping vistas of the Old West, rendered in vivid technicolor, first flickered across movie screens in 1939 with the release of Dodge City starring Errol Flynn. Eighty years later, cinematic frontiers are still being pushed, now with the rise of AI tools like DALL-E that can generate entire scenes with a few words. Both moments represent pivotal points where technology collides with creative possibility. As society grapples with this latest leap in synthetic media, we find ourselves at a similar inflection point with copyright law.
As copyright law races to catch up to rapidly evolving AI systems, things remain in flux. But at the outset of 2024, we can examine the landscape from two key perspectives:
- The copyright status of training data used to build models and
- Who owns the creative outputs these systems generate?
Scraping By: The Murky Copyright Status of Training Datasets
Developing powerful AI systems like large language models leans heavily on massive training datasets — often containing billions or trillions of words, images, or data points. For example, models such as GPT-3 were trained on scraped sources like Common Crawl and WebText2.
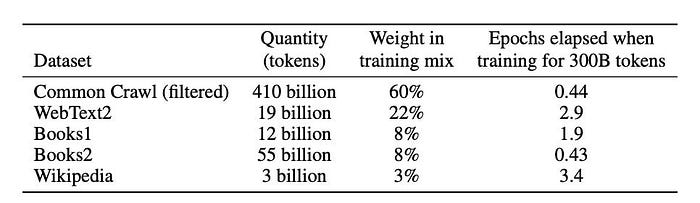
However, the legality of using such non-consensually compiled data remains questionable. The terms of service and copyright protections on many training data sources likely did not anticipate this type of bulk reproduction. Many sites have since updated their terms to bar unlicensed use for model training.
In response, some AI companies now pursue licensing deals with publishers to formally access content. OpenAI is reportedly paying publishers between one and five million dollars annually. Apple is also reportedly pursuing large ($50M) licensing deals for their LLM training data.
Given the surging investment and demand for AI, it seems inevitable that copyright issues around training data will ultimately be resolved. This trajectory mirrors past clashes where usability concerns eventually overcame initial legal objections. SCO’s Linux lawsuits and Oracle’s case against Google’s use of Java APIs set early precedents. Similarly, the booming appetite for AI capabilities will exert pressure to settle thorny training data copyright issues.
The Next Rembrandt or a Forger’s Fantasy? Untangling Copyright of AI Creations
While training data copyright remains murky, equally complex questions swirl around ownership of the artistic and literary works AI systems generate.
The first question, of course, is who owns the output of an LLM. Most providers like OpenAI function as modern computational engines, licensing their models to generate outputs under customer specifications. Their terms of service clearly permit users to retain rights to these AI-generated creations.
Ownership of Content. As between you and OpenAI, and to the extent permitted by applicable law, you (a) retain your ownership rights in Input and (b) own the Output. We hereby assign to you all our right, title, and interest, if any, in and to Output.
Source: OpenAI’s Terms of Use
Much as earlier computers enabled new applications while the users retained IP rights, language models grant licenses to generate custom content while creators retain control.
What happens if a model produces content that violates the copyright of the individuals whose data was used to train the model? In such cases, model providers offer to indemnify their customers against any such claims. For example, Microsoft’s Copilot Copyright Commitment promises to defend its customers against allegations of copyright infringement. Other companies like Adobe, Google, and OpenAI also provide similar assurances.
AI companies may give you ownership of the output, but can the output be copyrighted? This question was the subject of two interesting cases in 2022.
Human Minds Only: Copyright in the Age of Thinking Machines
In August 2023, a federal court ruling upheld a U.S. Copyright Office decision that an artwork created by an AI system is not eligible for copyright protection. Headlines proclaimed this a blow against using AI in creative pursuits. However, examining the details reveals a more nuanced reality.
This case centered on an application filed on behalf of “The Creativity Machine,” an AI program created by Stephen Thaler. The program was listed as the sole creator of a visual artwork titled “A Recent Entrance to Paradise.” By classifying the AI as the sole creator, the application challenged the notion that copyright requires human authorship.
The court ruled against this application, reiterating that copyright law only protects original works of human authorship. But this does not mean AI has no place in the creative process. Most artists use AI tools like Large Language Models as simply another medium, just as photographers use cameras.
The Camera Obscura: Parsing AI’s Role in Creative Works
The Creativity Machine case reiterated human authorship as a pillar of copyright. But questions linger around works blending AI and human ingenuity.
This issue took center stage in graphic novelist Kris Kashtanova’s attempt to copyright images created through Midjourney for the graphic novel, Zarya of the Dawn. The Copyright Office disputed Kashtanova’s claim, emphasizing Midjourney’s role in determining expressive elements of the AI-generated illustrations.

Yet past rulings like the 1884 Burrow-Giles v. Sarony case set a precedent affirming photographs could be copyrighted based on the photographer’s creative choices in composition, lighting, and scene arrangements. Could Kashtanova’s prompts and directions to Midjourney constitute enough creative input for copyright eligibility?
Early debates cast doubt on photographs as mere mechanical reproductions. However, photographic authorship gained recognition once the photographer’s creative decisions were better understood. AI-assisted works may follow a similar trajectory from skepticism to nuanced acceptance.
The path ahead remains complex as society grapples with AI’s impacts on copyright law and creative industries. But looking back at photography’s evolution shows how new technologies often traverse thorny early legal debates before being accepted into the creative fold. Just as photographers gained recognition as authors, artists working with AI may similarly demonstrate enough original human creativity to earn copyright protection. The destination is still uncertain, so stay tuned!
Read More:
Copyright, AI, and the Murky Present: From Mickey Mouse to Machine Minds
Tracing the journey of copyright law, from the rise of Mickey Mouse to the emergence of LLMs.
boxcarsai.substack.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





