



Metas New Text-to-Image Model — CM3leon Paper explained
Last Updated on August 19, 2023 by Editorial Team
Author(s): Boris Meinardus
Originally published on Towards AI.
The new SOTA and highly efficient Text-to-Image(-to-Text!) model.
Meta recently released its new state-of-the-art text-to-image model, called CM3Leon [1], that is NOT based on diffusion like Stable-Diffusion [2], Midjourney, or DALLE [3].
It is a retrieval-augmented, autoregressive, decoder-only model!
Quite a mouth full, but in this post, we’ll get to know what all that means. At this point, we already know that current image generation models can generate amazing images but still have certain limitations. E.g., the efficiency and cost of those models. Or generating hands! But not with CM3Leon, which the authors appear to be very proud of!
The generation itself is cool, but what this autoregressive, decoder-only approach also enables are image-to-text capabilities!
Results
But, okay, first, let’s have a closer look at the results and why CM3Leon is so special!
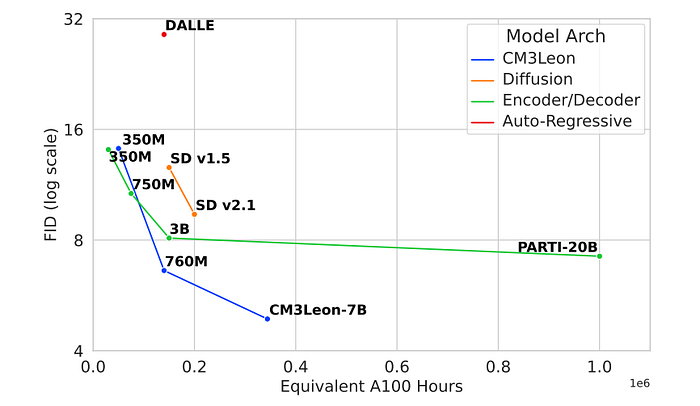
We already looked at nicely generated images, but when we look at the numbers in the figure above, we can really see how much better CM3leon is than other models, such as DALLE and Parti.
Now, one can argue how well the FID score actually captures the realism of the generated image, but nevertheless, CM3Leon sets a new state-of-the-art FID score on the MS COCO dataset. Where I do have to say, choosing the autoregressive version of the DALLE model is a bit unfair.
How does DALLE work?
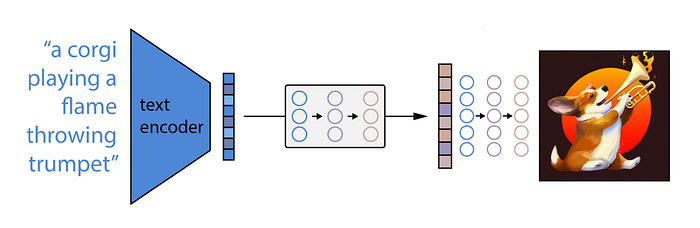
Just on a small tangent, DALLE has an intermediate model, called the prior, that maps the text embedding generated by CLIP to a corresponding image encoding, which is then used to generate the final image using diffusion. This prior can again be a diffusion process or an autoregressive one. Both appear to yield similar results, but the diffusion process is more efficient, so the authors of DALLE went with that one.
So yeah, choosing the less efficient version for the comparison here might be a bit unfair for DALLE.
Back to image generation results

Now, okay. The nice FID score alone is great, but even better is that CM3Leon achieves this performance while being a lot more efficient!! With its largest 7 billion parameter model, it is way smaller than the largest Parti model, and it uses a fraction of the training data and time!
Also, the authors introduce a new metric for “responsible” training. The images used for training CM3Leon are all licensed from Shutterstock, so (hopefully) no more fear of lawsuits!
Then there is the column “Nr. of retrieved documents” which is one of the main features of the CM3Leon model that makes it so great, and we’ll get to know more about it in a second. But in short, given a text prompt, the model can somehow retrieve relevant images or even text from a memory bank and use it as further context for the image generation process.
What is considered zero-shot generation?
Now, the thing that makes me wonder is that if the model retrieves further images for the generation process, is it really zero-shot generation? I guess the model itself retrieves the extra images and they are not provided by the person prompting the model, but yeah, not 100% sure here.
On that note, in the abstract, the authors mention their top-performing model that achieves a “zero-shot MS-COCO FID [score] of 4.88”
CM3Leon achieves state-of-the-art performance in text-to-image generation with 5× less training compute than comparable methods (zero-shot MS-COCO FID of 4.88). — Source: [1]
But this score is achieved with two retrieved images, i.e. they refer to the retrieval as zero-shot. But in their caption of Figure 1, they say the following:
Showcase of CM3Leon zero-shot generations (no-retrieval augmentation). — Source: [1]
So, what is a zero-shot generation? With retrieval or without?
Multimodal benchmarks
Okay, up until now, it was all about image generation, but since this model is an autoregressive, decoder-only model, pretty much like all big LLMs, it can also interpret images as normal tokens and use them as context for text generation! In other words, after applying Supervised Fine-tuning (or, for short SFT), our model can also do more complex multimodal tasks.
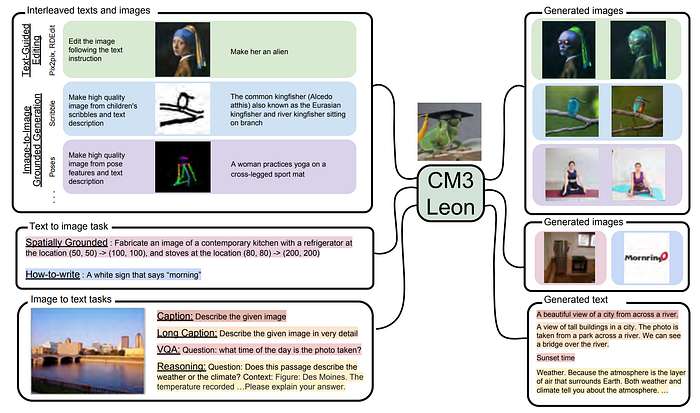
It is very good at interleaved text and image tasks such as “Text guided editing”, and “Image-to-Image Grounded Generation” where you can provide a segmentation map, sketch with only outlines, or even a depth map, and based on those and a text prompt the new image is generated. Or, with “Spatially Grounded Image Generation”, you can even provide the coordinates of an object in the text prompt, and the generated image will place that object at those coordinates. On top of that, the model is quite good at actually generating text in images, which was not the case for a while.
And by a while, I mean literally less than one or two years ago :))
Finally, with the correct Supervised Fine-tuning, CM3Leon can also take images as input and do tasks like Image captioning with short or long answers, Visual Question Answering, and Reasoning. It still is not as good as dedicated image captioning models like Flamingo [4], but since this is more or less just a side effect of the model design, the results are still very impressive!
How does CM3Leon work?
Okay, sick, but how does CM3Leon work, and what does retrieval-augmented, auto-regressive, decoder-only model mean!?
At this point, we all more or less know how diffusion works. A model is trained to predict noise in an image so that when we start off with completely random noise, we can apply this model and remove the noise step by step. This noise removal process can now also be conditioned on the text so that we can guide the generation process with our prompt.
Autoregressive models work a bit differently.
Let’s have a look at how Parti implements this idea of an autoregressive image generation model.
What is Autoregressive?
Remember how Autoencoders work? We have an Encoder network that maps an image to some embedding so that the decoder can then generate the same image only from a latent vector representation. In the image below, this idea is illustrated by the green module.
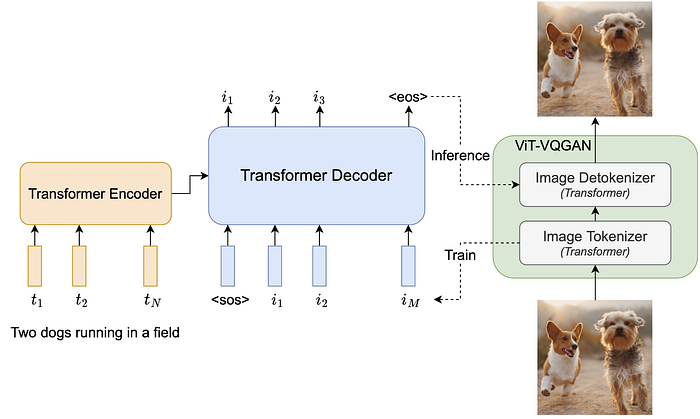
Now, what if those embeddings the decoder (in the case of Parti called detokenizer) uses for generating the image come in the form of tokens predicted by a Language Model? Think of how a GPT model starts with a simple Start-of-Sequence token and predicts the next token or rather token-embedding out of a given vocabulary in the know autoregressive fashion.
A vision transformer also generates embeddings for each patch token of the image and those can also be constrained to be from a certain vocabulary. That means that our autoregressive text-decoder (blue module) can also generate each image embedding token and then let the image generator (or again, here called detokenizer) generate the image.
Now, to condition the image token generation process, Parti decides to go with an encoder-decoder approach. It uses the full Transformer architecture for what it was originally designed, translating text. In this case simply translating the language of text into the language of images, or, text tokens into image tokens. In other words, they use Cross-attention where the text-encoder (yellow module) embeddings are used as conditioning for the text-decoder that predicts one image token after the other.
This autoregressive approach solves some issues that diffusion models had. E.g. autoregressive models can much better deal with long text prompts and can generate text in images very well!
But it can do so only with scale. The case of “simply go bigger and it will work” is quite extreme here. We can look at this example with the kangaroo and the text “Welcome Friends!”.

What is decoder-only?
Okay, we now know how autoregressive image generation works, but CM3Leon is an autoregressive decoder-only model and not an encoder-decoder model like Parti.
What that pretty much means, is that the text conditioning for the generation process happens not via an encoder and cross-attention, but as simple text tokens in the decoder context. That means that the vocabulary now has to include the image token vocabulary (where the authors use an already existing tokenizer) and the text token vocabulary (where the authors train a new tokenizer themselves). Additionally, the authors introduce a new <break> token that indicates a transition in modalities.

Now our decoder input and output can look something like this where we start with the prompt “A Photo of a cat shown on a dslr” followed by the <break> token and the decoder then predicts the next image tokens one by one. Once we reach another <break> or <EOS> token, the image decoder can take over and generate the image!
When it comes to training data, the model can handle multimodal cases such as “Image of a chameleon:” followed by the image tokens, where the model is simply trained on the standard next token prediction loss.
“Image of a chameleon: “ → “<Img233>”, “<Img44>”, …
But this also means that the model can handle image captioning tasks by simply reformatting the same example to mask a certain part of the sample and expect the model the predict the masked part after the <infill> request.
“Image of a <mask>: <Img233>, … <infill> → “chameleon”
In other words, the model sees the image and has to predict what this image contains.
Our model can now generate both text and images.
Autoregressive, check.
Decoder-only, check.
Finally, how does this “retrieval-augmentation” thing work?
What is retrieval-augmentation?
I already mentioned, that this pretty much means, that given the initial prompt, the model can retrieve either images or text, or both, and add it to its context. Since we now know how the input to the decoder-only model works, we can pretty easily understand how simple it is to just add more images and text to the context.

We can simply add as much text and images sitting in between <break> tokens as the maximum context length allows! And with a sequence length of 4096, we should be okay to add one or two retrieved documents.
Documents hereby refer to elements that can be single images or text, or an image and caption pair.
CM3Leon builds a lot on the RA-CM3 paper, [6], which proposed to add this retrieval augmentation feature to the method proposed in the CM3 paper, [7]. Now that’s research, one paper building on the other!
In the RA-CM3 paper, we can very nicely see the effects of retrieving an image for a given text prompt.

Here e.g. we can see some outputs to the prompt “French Flag waving on the moon’s surface” where the vanilla CM3 without retrieval and Stable Diffusion simply place the American flag on the moon, but if we now add a retrieved image of the French flag to the context, RA-CM3 generates a proper result. Similar effects are seen when retrieving two images, and so on.

This, of course, also allows you to specify an image manually to control the style of the generated image, as we can see here in this example. Providing an image of a person with a red jacket will also lead to the model inpainting a person with a red jacket.
Cool, so how does this retrieval work? The idea is actually really simple.
The authors use an off-the-shelf, frozen CLIP model to encode the input query, e.g., a simple text prompt, and sort similar candidates from a memory bank by a relevance score. The individual text and image examples in the memory bank simply pass through the CLIP model once, but for the image and caption documents, the authors split the text and image, encode them separately, and then average the two as a vector representation of the whole document.
The authors don’t simply select the most similar document but use different heuristics to make the retrieval more informative. E.g., a document consisting of an image and text is more informative than only text or only an image. Or they skip a candidate document if it is too similar to the query or if pretty much the same document has already been retrieved. And a few other tricks.
There are other minor (but important!) details, to make the model output itself work even better, but those are no fundamentally new ideas, just add-on tricks that generally appear to increase performance. E.g., randomly sampling different temperature values, or something called TopP sampling, applying classifier-free guidance during inference, or their own adaptation of Contrastive Decoding.
So, in the end, we now know how the retrieval-augmented, autoregressive, decoder-only CM3Leon model works, and what it can do. This retrieval idea is a key contributor to the fact that the model is so parameter and thus data efficient!

The model does not have to memorize the whole world’s information, like, what is a cherry blossom tree or Mount Rushmore and what they look like. And using a decoder-only architecture makes the training and fine-tuning to new tasks much easier!
After potentially thinking diffusion models are the best way to go for image generation, this paper just again shows how powerful autoregressive models such as the famous transformer models are for a broad range of text and image tasks.
And if you enjoyed reading this post, don’t forget to leave a clap and follow me for more exciting AI paper explanation posts!
P.S.: If you like this content and the visuals, you can also have a look at my YouTube channel, where I post similar content but with more neat animations!
References
[1] Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning, L. Yu, B Shi, R Pasunuru, et al., 2023, Link to paper
[2] High-Resolution Image Synthesis with Latent Diffusion Models, R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B., 2021, https://arxiv.org/abs/2112.10752
[3] Zero-Shot Text-to-Image Generation, Ramesh et al., 2021, https://arxiv.org/abs/2102.12092
[4] Flamingo: a Visual Language Model for Few-Shot Learning, B. Alayrac, J. Donahue, P. Luc, A. Miech et al., 2022, https://arxiv.org/abs/2204.14198
[5] Scaling Autoregressive Models for Content-Rich Text-to-Image Generation, Yu et al., 2022, https://arxiv.org/abs/2206.10789
[6] Retrieval-Augmented Multimodal Language Modeling, Yasunaga et al., 2022, https://arxiv.org/abs/2211.12561
[7] CM3: A Causal Masked Multimodal Model of the Internet, A. Aghajanyan et al., 2022, https://arxiv.org/abs/2201.07520
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


