



Six Amazing Unknown Python Libraries
Last Updated on July 25, 2023 by Editorial Team
Author(s): Dhilip Subramanian
Originally published on Towards AI.
Cool python libraries for Data Engineering and NLP
I’ve been using Python extensively for the last five years. As a result, I’m always looking for amazing libraries that can enhance my work in Data Engineering and Business Intelligence projects. In the past, I’ve shared two articles, Five Cool Python Libraries for Data Science and Six cool Python Libraries That I Came Across Recently.
In this article, I share another six amazing python libraries I’m using now at my work.
1. Humanize
Humanize” provides simple, easy-to-read string formatting for numbers, dates, and times. The library’s goal is to take data and make it more human-friendly, for example, by converting a number of seconds into a more readable string like “2 minutes ago”. The library can format data in various ways, including formatting numbers with commas, converting timestamps into relative times, and more.
I frequently use integers and date & time for my data engineering projects.
Installation
!pip install humanize
Example (Integers)
# Importing library
import humanize
import datetime as dt
# Formatting numbers with comma
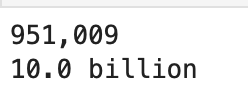
a = humanize.intcomma(951009)
# converting numbers into words
b = humanize.intword(10046328394)
#printing
print(a)
print(b)
Output
Example (Date & Time)
import humanize
import datetime as dt
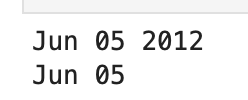
a = humanize.naturaldate(dt.date(2012, 6, 5))
b = humanize.naturalday(dt.date(2012, 6, 5))
print(a)
print(b)
Output
For more formatting options, please check here.
2. Pendulum
Although many libraries are available in Python for DateTime, I find Pendulum easy to use on any operation on the dates. A pendulum is my favorite library for my daily usage at my work. It extends the built-in Python datetime module, adding a more intuitive API for handling time zones and performing operations on dates and times like adding time intervals, subtracting dates, and converting between time zones. It provides a simple, human-friendly API for formatting dates and times.
Installation
!pip install pendulum
Example
# import library
import pendulum
dt = pendulum.datetime(2023, 1, 31)
print(dt)
#local() creates datetime instance with local timezone
local = pendulum.local(2023, 1, 31)
print("Local Time:", local)
print("Local Time Zone:", local.timezone.name)
# Printing UTC time
utc = pendulum.now('UTC')
print("Current UTC time:", utc)
# Converting UTC timezone into Europe/Paris time
europe = utc.in_timezone('Europe/Paris')
print("Current time in Paris:", europe)
Output

I need to write a separate blog for this library, showing a few examples here. For more formatting, please check here.
3. ftfy
Have you encountered when the foreign language present in the data does not appear correctly? This is called Mojibake. Mojibake is a term used to describe garbled or scrambled text that occurs as a result of encoding or decoding problems. It typically occurs when text that was written in one character encoding is incorrectly decoded using a different encoding. ftfy python library will help you fix the Mojibake, which is very useful in NLP use cases.
Installation
!pip install ftfy
Example
print(ftfy.fix_text('Correct the sentence using “ftfyâ€\x9d.'))
print(ftfy.fix_text('✔ No problems with text'))
print(ftfy.fix_text('à perturber la réflexion'))
Output

Apart from Mojibake, ftfy will fix incorrect encodings, incorrect line endings, and incorrect quotes. According to the documentation, ftfy can understand text that was decoded as any of the following encodings:
- Latin-1 (ISO-8859–1)
- Windows-1252 (cp1252 — used in Microsoft products)
- Windows-1251 (cp1251 — the Russian version of cp1252)
- Windows-1250 (cp1250 — the Eastern European version of cp1252)
- ISO-8859–2 (which is not quite the same as Windows-1250)
- MacRoman (used on Mac OS 9 and earlier)
- cp437 (used in MS-DOS and some versions of the Windows command prompt)
For more details, please check the documentation here.
4. Sketch
The sketch is a unique AI code-writing assistant specifically designed for users who work with the pandas library in Python. It utilizes machine learning algorithms to understand the context of the user’s data and provides relevant code suggestions to make data manipulation and analysis tasks easier and more efficient. Sketch does not require users to install any additional plugins in their IDE, making it quick and easy to start using. This can greatly reduce the time and effort required for data-related tasks and help users to write better and more efficient code.
Installation
!pip install sketch
Example
We need to add a .sketch extension to Pandas data frame to use this library.
.sketch.ask
ask is a feature of Sketch that allows users to ask questions about their data in a natural language format. It provides a text-based response to the user’s query.
# Importing libraries
import sketch
import pandas as pd
# Reading the data (using twitter data as an example)
df = pd.read_csv("tweets.csv")
print(df)

# Asking which columns are category type
df.sketch.ask("Which columns are category type?")
Output

# To find the shape of the dataframe
df.sketch.ask("What is the shape of the dataframe")

.sketch.howto
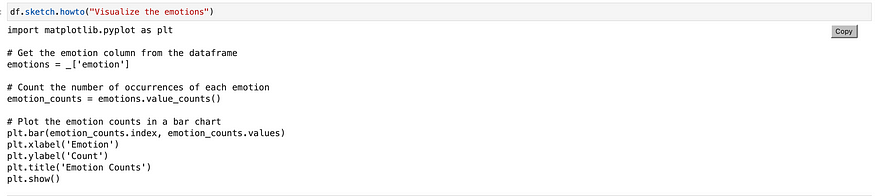
howto is a feature that provides a code block that can be used as a starting point or conclusion for various data-related tasks. We can ask for code snippets to normalize their data, create new features, plot data, and even build models. This will save time and easily copy and paste the code; you don’t need to write the code manually from scratch.
# Asking to provide code snipped for visualising the emotions
df.sketch.howto("Visualize the emotions")
Output
.sketch.apply
.apply function helps to generate new features, parse fields, and perform other data manipulations. To use this function, we need to have an OpenAI account and use the API Key to perform the tasks. I haven’t tried this function.
I enjoyed using this library, especially howto function, and I find it useful.
Please check this Github for more about Sketch.
5. pgeocode
“pgeocode” is an excellent library I recently came across, which has been incredibly useful for my spatial analysis projects. For example, it allows you to find the distance between two postcodes and provides geo-information by taking a country and a postcode as inputs.
Installation
!pip install pgeocode
Example
Getting geoinformation for specific postcodes
# Checking for country "India"
nomi = pgeocode.Nominatim('In')
# Getting geo information by passing the postcodes
nomi.query_postal_code(["620018", "620017", "620012"])
output

“pgeocode” calculates the distance between two postcodes by taking the country and postcodes as inputs. The result is given in kilometers.
# Finding a distance between two postcodes
distance = pgeocode.GeoDistance('In')
distance.query_postal_code("620018", "620012")Output

For more information, please check here.
6. rembg
rembg is another useful library that removes the background from the images easily.
Installation
!pip install rembg
Example
# Importing libraries
from rembg import remove
import cv2 # path of input image (my file: image.jpeg)
input_path = 'image.jpeg'# path for saving output image and saving as a output.jpeg
output_path = 'output.jpeg'# Reading the input image
input = cv2.imread(input_path)# Removing background
output = remove(input)# Saving file
cv2.imwrite(output_path, output)
Output

You may already be familiar with some of these libraries, but for me, Sketch, Pendulum, pgeocode, and ftfy are indispensable for my data engineering work. I rely on them heavily for my projects.
Thank you for taking the time to read this. I’d love to hear your thoughts and insights, so don’t hesitate to leave a comment. If you have anything to add, please feel free to comment!
Feel free to connect with me on LinkedIn!
You might also like my previous article Five Cool Python Libraries for Data Science and Six cool Python Libraries That I Came Across Recently
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

