



Understanding LangChain 🦜️🔗: Part:2
Last Updated on July 17, 2023 by Editorial Team
Author(s): Chinmay Bhalerao
Originally published on Towards AI.
Understanding LangChain U+1F99C️U+1F517: Part:2
Implementing LangChain practically for building custom data bots involves incorporating memory, prompt templates, and Chains, and creating web-based applications
WE CAN CONNECT ON :U+007C LINKEDIN U+007C TWITTER U+007C MEDIUM U+007C SUBSTACK U+007C
The creation of LLM applications with the help of LangChain helps us to Chain everything easily.LangChain is an innovative framework that is revolutionizing the way we develop applications powered by language models. By incorporating advanced principles, LangChain is redefining the limits of what can be achieved through traditional APIs.
In the last blog, we discussed modules present in LangChain in detail, revising it,
Understanding LangChain U+1F99C️U+1F517: PART 1
Theoretical understanding of chains, prompts, and other important modules in Langchain
pub.towardsai.net
Langchain constist of few modules. As its name suggests, CHAINING different modules together are the main purpose of Langchain. We discussed this module.
- Model
- Prompt
- Memory
- Chain
- Agents
In this blog, we will see the actual applications of LangChain and its different use cases.
Let's build simple applications with LangChain without any further due. The most interesting application is creating a question-answering bot over your own custom data.
Code
Disclaimer/Warning: This code is just to show how applications are built. I didn't claim any optimization in the code and further improvements are needed according to the specific problem statement.
Let's start with imports
Importing LangChain and OpenAI for LLM part. If you do not have any of this then please install it.
# IMPORTS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import ConversationalRetrievalChain
from langchain.vectorstores import ElasticVectorSearch, Pinecone, Weaviate, FAISS
from PyPDF2 import PdfReader
from langchain import OpenAI, VectorDBQA
from langchain.vectorstores import Chroma
from langchain.prompts import PromptTemplate
from langchain.chains import ConversationChain
from langchain.document_loaders import TextLoader
# from langchain import ConversationalRetrievalChain
from langchain.chains.question_answering import load_qa_chain
from langchain import LLMChain
# from langchain import retrievers
import langchain
from langchain.chains.conversation.memory import ConversationBufferMemory
py2PDF is used to read and process pdf. Also, there are different types of memories like ConversationBufferMemory, ConversationBufferWindowMemorythat have specific functions to perform. I am writing the next blog of this series dedicated to memories so I will elaborate everything over there.
Let's set the environment.
I guess you know how you can get the OpenAI API key. but just in case,
- Go to the OpenAI API page,
- Click on Create new secrete key
- That will be your API key. Paste it below
import os
os.environ["OPENAI_API_KEY"] = "sk-YOUR API KEY"
Which model to use? Davinci, Babbage, Curie, or Ada? GPT 3 based? GPT 3.5-based or GPT 4-based? There are lots of questions about models and all models are good for different tasks. few are cheap and few are more accurate. We also going to see all models in detail in 4th blog of this series.
For simplicity, we will use most cheaper model “gpt-3.5-turbo”. The temperature is a parameter that gives us an idea about the randomness of the answer. More the value of temperature, the more random answers we will get.
llm = ChatOpenAI(temperature=0,model_name="gpt-3.5-turbo")
Here you can add your own data. You can add in any format like PDF, Text, Doc, CSV. According to your data format, you can comment/uncomment the following code.
# Custom data
from langchain.document_loaders import DirectoryLoader
pdf_loader = PdfReader(r'Your PDF location')
# excel_loader = DirectoryLoader('./Reports/', glob="**/*.txt")
# word_loader = DirectoryLoader('./Reports/', glob="**/*.docx")
We cant add all data at once. We split data into chunks and send it to create embeddings for data. If you don't know what embeddings are then
Embeddings, in the form of numerical vectors or arrays, capture the essence and contextual information of the tokens manipulated and produced by the model. These embeddings are derived from the model’s parameters or weights and serve the purpose of encoding and decoding the input and output texts.


In simple,
Embedding in LLM is a way of representing text as a vector of numbers. This allows the language model to understand the meaning of words and phrases, and to perform tasks such as text classification, summarization, and translation. In layman’s terms, an embedding is a way of turning a word into a number. This is done by training a machine learning model on a large corpus of text. The model learns to associate each word with a unique vector of numbers. This vector represents the meaning of the word, as well as its relationship to other words.
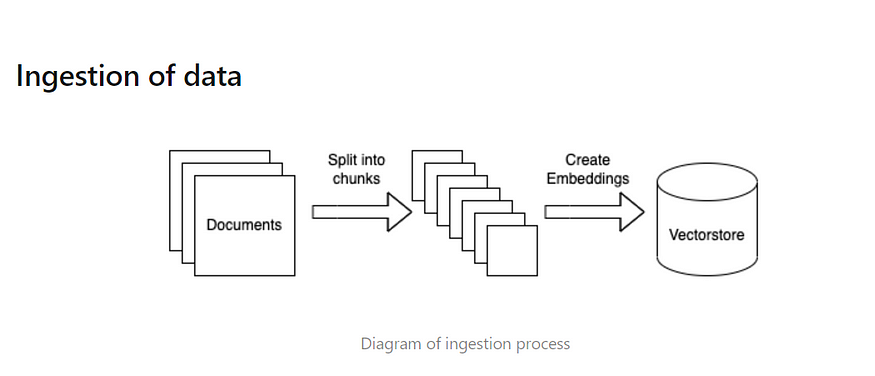
Let's do exactly the same thing as represented in the above image.
#Preprocessing of file
raw_text = ''
for i, page in enumerate(pdf_loader.pages):
text = page.extract_text()
if text:
raw_text += text
# print(raw_text[:100])
text_splitter = CharacterTextSplitter(
separator = "\n",
chunk_size = 1000,
chunk_overlap = 200,
length_function = len,
)
texts = text_splitter.split_text(raw_text)
In practical terms, when a user initiates a query, a search is conducted in the vector store, and the most suitable index(es) are retrieved and passed on to the LLM. The LLM then reformulates the content found within the index to deliver a formatted response to the user.
I suggest delving further into the concepts of vector store and embeddings to enhance your understanding.
embeddings = OpenAIEmbeddings()
# vectorstore = Chroma.from_documents(documents, embeddings)
vectorstore = FAISS.from_texts(texts, embeddings)
The embeddings are directly stored in a vector database. There are many vector databases that work for us like Pinecone, FAISS, etc. Let's use FAISS here.
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say GTGTGTGTGTGTGTGTGTG, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:"""
QA_PROMPT = PromptTemplate(
template=prompt_template, input_variables=['context',"question"]
)
You can use your own prompt to refine the query and answer. After writing the prompt, let's chain it to the final chain.
Let's call the last chain which will include everything that we chained earlier. We are using ConversationalRetrievalChain here. This helps us to do conversations with Bot like a human does. and it remembers previous chat conversations.
qa = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.8), vectorstore.as_retriever(),qa_prompt=QA_PROMPT)
We will use simple Gradio to create a web app. You can use streamlit or any front-end technology. Also, there are many free deployment options available like deployment on hugging face or local host that we can do later.
# Front end web app
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("## Grounding DINO ChatBot")
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.Button("Clear")
chat_history = []
def user(user_message, history)
print("Type of use msg:",type(user_message))
# Get response from QA chain
response = qa({"question": user_message, "chat_history": history})
# Append user message and response to chat history
history.append((user_message, response["answer"]))
print(history)
return gr.update(value=""), history
msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False)
clear.click(lambda: None, None, chatbot, queue=False)
############################################
if __name__ == "__main__":
demo.launch(debug=True)
This code will initiate a local link to your web app and you directly ask questions and see the responses. Also at your IDE, you will see what chat history is getting maintained.

That's enough for today. This is a simple introduction for chaining the different modules and using them to initiate the final chain. You do many things by twisting different modules and code. PLAYING IS THE HIGHEST FORM OF RESEARCH, I would say!!!
In the next blog, I will be covering memories and models in LangChain. How to choose a model, how memories can contribute, and many more… So stay tuned and reach me in case of any suggestions, or problems.
If you have found this article insightful
It is a proven fact that “Generosity makes you a happier person”; therefore, Give claps to the article if you liked it. If you found this article insightful, follow me on Linkedin and medium. You can also subscribe to get notified when I publish articles. Let’s create a community! Thanks for your support!
Also, medium doesn’t give me anything for writing, if you want to support me then you can click here to buy me coffee.
You can read my blogs related to,
Understanding LangChain U+1F99C️U+1F517: PART 1
Theoretical understanding of chains, prompts, and other important modules in Langchain
pub.towardsai.net
Mastering Large Language Models: PART 1
A basic introduction to large language models and their emergence
medium.com
Converting data into SQuAD format for fine-tuning LLM models
Introduction to the Haystack annotation tool and its implementation
medium.com
Traditional object detection will take over by zero-shot learning?
Comparison of zero-shot learning and traditional object detection models
medium.com
Signing off,
Chinmay
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

