


An Overview of Extreme Multilabel Classification (XML/XMLC)
Last Updated on April 17, 2023 by Editorial Team
Author(s): Kevin Berlemont, PhD
Originally published on Towards AI.
Who hasn’t been on Stack Overflow to find the answer to a question? Correctly predicting the tags of the questions is a very challenging problem as it involves the prediction of a large number of labels among several hundred thousand possible labels.
Traditional classification methods such as Support Vector Machines or Decision Tree are not designed to handle such a large number of labels due to three main challenges:
- a bottleneck due to memory constraints
- the presence of some labels with very few examples (tail labels)
- labels are usually correlated, which can make it difficult to distinguish between the different labels
In this article, I am going to provide a short overview of extreme multilabel classification with some important definitions. In the second part, I will present and explain the four main categories of XML algorithms along with some of their limitations.
XMLC overview
The goal of an XMLC model is to predict a set of labels for a specific test input. However, typical algorithms do not produce a binary result but instead, provide a relevancy score for which labels are the most appropriate. This point is important as it shifts the problem from a classification problem to a ranking problem. Therefore, the evaluation metrics for these algorithms need to reflect the ranking aspect rather than just the classification. Labels can be selected by applying a simple threshold on the ranked list provided by the model.
As mentioned previously, samples and labels are not uniformly distributed in extreme multilabel classification problems. For example, in the Wiki10–30K dataset [1], only 1% of the labels have more than 100 training samples. A model trained without the specificity of this tail distribution will be biased toward the most present labels.
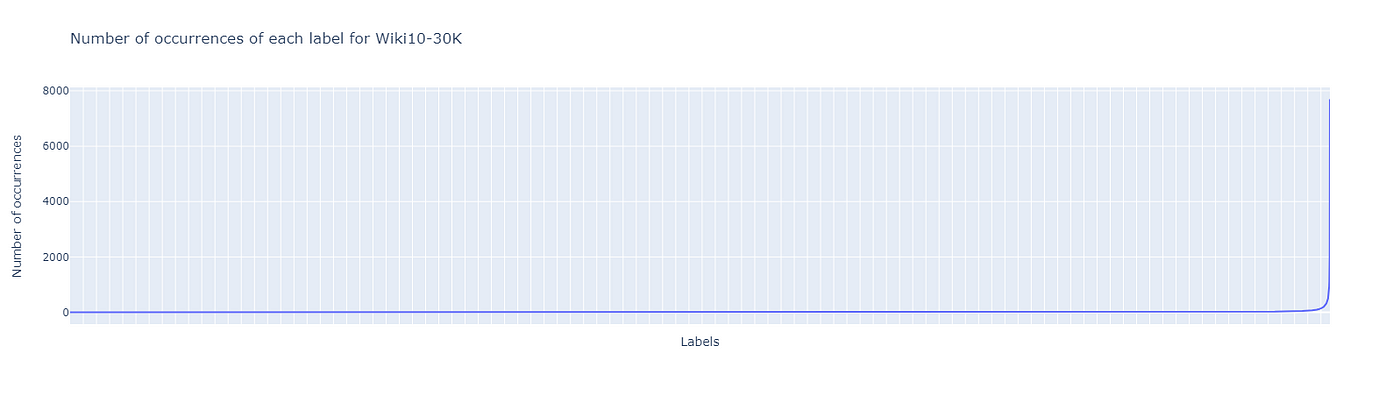
To take into account the tail distribution in the metric, one should use propensity-based metrics. These metrics are similar to typical ranking metrics, but they also take into account how well a model performs on tail labels. This prevents a model from achieving a high score by only predicting frequent labels. For example, the propensity-based version of the Precision@k metric is:
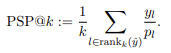
where p_l represents the propensity of a label. Thus tail labels have an inflated score in the metric.
Compressed sensing XMLC algorithms
The idea behind this type of algorithm is to compress the label space into a smaller embedding space. Due to the sparsity of the original label space, it is possible to recover the original labels from the predictions in the embedded label space. Typical compressed sensing algorithms can be decomposed in three steps:
- Compression: The label space is embedded into a smaller space.
- Learning: Learning to predict compressed labels. As the embedded space is small enough, typical label classification methods can be used, such as binary relevance, which predicts each element using a binary classifier.
- Reconstruction: Converting back the embedded space to the original space
Although this method allows the use of typical label classification algorithms due to the small compressed space, solving the reconstruction step can be computationally expensive. Therefore, efficient space-reduction techniques are necessary. One solution [2] is to use an SVD approach (Linear Label Space Transformation) to embed the label space as it will take into account the labels correlations but provide a formal framework to compress and reconstruct the original label space.
More advanced compressed sensing algorithms have been developed by taking into account more and more correlations during the compression. For instance, it is possible to take into account not just the label-label correlations but the labels and features correlations too. Adding such extra information should improve the classification compared to the previous method (Principle Label Space Transformation).
Linear Algebra based XMLC algorithms
The linear algebra-based methods are similar to the compressed sensing ones but aim to improve small improvements over them. In this section, I will give an overview of the most known algorithms based on linear algebra to perform extreme multilabel classification.
Subset Selection: Subset selection is the most common method used to keep the XMLC problem tractable. The idea is to find a good subset of labels and then apply a classifier to this subset to finally scale back the predictions to the full dataset. To select the subset of labels, one can use a sampling procedure where the probability of a label is proportional to the score of the label on the best possible subset.
Low-rank Decomposition: This method assumes a low-rank decomposition of the label matrix, and then it uses a risk minimization method framework to solve it. One caveat to the low-rank assumption is that due to the presence of outliers, this assumption is not always verified, as the outliers might not be spanned in the embedding space.
Distance preserving embeddings: The name of this method is straightforward. The embedding space is generated by preserving the distances between the labels. The prediction is then done using a k-nearest neighbor method within the embedding space.
Feature Agglomeration Supplement: This method is original as it aims to reduce the dimensionality of the feature space directly. In the case of a sparse feature sparse, this method provides a high speed up with a minimal loss of accuracy. The feature space reduction is performed by aggregating clusters of features of balanced size. This clustering is usually performed using hierarchical clustering.
Tree-based algorithms
The tree-based methods aim at repeatedly dividing the label space in order to reduce the search space during the prediction. The idea is to sort the labels into clusters to create a meta-label space. Each of the meta-label is then linked to a multi-label classifier to determine the meta-label a label belongs to. Within a meta-label, due to the smaller number of labels, it is possible to use a classic classifier to predict the label.
These methods are usually a lot faster than the embedding method, as the tree structure reduces training and search time. They usually do not perform better than baseline methods but do such a lot faster. In addition, these algorithms are very scalable as meta-labels allow for a constant classification cost (balanced meta-labels).
Deep-learning methods
As in most of machine learning problems, deep learning methods have started to be used in extreme label classification. However, the use of such methods has only been recent due to the fact that the heavy tail of the labels implies a small amount of training data available for such labels. This is in contrast to what deep learning methods require. The space is large, and the model has to be large too.
However, deep learning is extremely efficient at content extraction and gives very representative embeddings. Initially, convolutional neural networks were used to extract the embeddings, but this approach has been eliminated as it has been proven to not be the most efficient for text embeddings. The general framework for deep learning methods applied to XML is called DeepXML and has been defined by [3].
This framework has four modules:
- The first module has for the goal of obtaining an intermediate embedding of the features that will be used later on. This could mean a label clustering or a label projection in order to keep the problem tractable.
- The second module uses what is called negative sampling. Negative sampling selects the most confusing labels from a sample that are supposed to be predicted positively. This has for the effect of reducing the training time per label, as we will train on hard samples only.
- The third module gives the final features representation making use of transfer learning.
- Finally, the final module corresponds to the classifier. Due to the negative sampling, the amount of training is limited, and it is tractable by a deep learning method.
Deep learning methods have outperformed all other XML methods, such as tree-based ones. However, this does come at the cost of training time and memory space.
From document tagging to product recommendation and advertising, XML has used a very diverse set of problems. Recently, work has been done [4] in multimodal extreme multi-label classification. Such broad use of XML methods in products of every day is what calls for further exploration of XML methods such as deep learning ones.
References
[1] The extreme classification repository: Multi-label datasets and code, Bhatia, K. and Dahiya, K. and Jain, H. and Kar, P. and Mittal, A. and Prabhu, Y. and Varma, M., 2016.
[2] Multilabel classification with principal label space transformation. Farbound Tai and Hsuan-Tien Lin. 2012
[3] Deepxml: A deep extreme multi-label learning framework applied to short text documents. Kunal Dahiya, Deepak Saini, Anshul Mittal, Ankush Shaw, Kushal Dave, Akshay Soni, Himanshu Jain, Sumeet Agarwal, and Manik Varma. 2021
[4] Review of Extreme Multilabel Classification, Dasgupta, A., Katyan, S., Das, S. and Kumar, P. 2023
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts



")


