



Maximizing Pandas Performance: 6 Best Practices for Efficient Data Processing
Last Updated on February 15, 2023 by Editorial Team
Author(s): Fares Sayah
Originally published on Towards AI.
Optimizing Pandas: Understanding Data Types and Memory Usage for Efficient Data Processing
Pandas is a popular library in the world of Data Science that makes it easy to work with data using efficient and high-performance tools. But when dealing with huge amounts of data, Pandas can become limited and cause memory problems. To overcome these issues, you can use other tools like Dask or Polar. This article will give you some tips to try before switching to another tool.
Pandas data types can be confusing, so it’s important to check them when you first begin exploring your data. Having the correct data types will make your analysis more accurate and efficient. Sometimes, Pandas might read an integer column as a floating point or object type, which can lead to errors and use up extra memory. This article will explain Pandas data types and show you how to save memory by using the right data types.
This article is inspired by Matt Harrison’s talk: Effective Pandas I Matt Harrison I PyData Salt Lake City Meetup.
We are going to use vehicle data in this article: vehicles data. The data is a little bit big, so we are going to choose a few columns to experiment with.
Table Of Content
· 1. Reading the Data
· 2. Memory Usage
· 3. Pandas Data Types
· 4. Integers
· 5. Float
· 6. Objects and Category
· 8. Datetimes
· 9. NumPy vs Pandas operations
1. Reading the Data
If the data does not fit into your memory in the first place, you can read data in chunks and explore it. The parameter essentially means the number of rows to read into memory.
After exploring a small portion of the data, you now know what the important columns and unimportant columns are. To save extra memory, you can only read important columns.
2. Memory Usage
The Pandas info() function provides valuable information about a DataFrame, including the data type of each column, the number of non-null values, and memory usage. This function is useful for understanding the structure of your data and optimizing memory usage. The memory usage report is displayed at the end of the info() function's output.
To get full memory usage, we provide memory_usage=”deep” argument to info().
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 41144 entries, 0 to 41143
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 city08 41144 non-null int64
1 comb08 41144 non-null int64
2 highway08 41144 non-null int64
3 cylinders 40938 non-null float64
4 displ 40940 non-null float64
5 drive 39955 non-null object
6 eng_dscr 24991 non-null object
7 fuelCost08 41144 non-null int64
8 make 41144 non-null object
9 model 41144 non-null object
10 trany 41133 non-null object
11 range 41144 non-null int64
12 createdOn 41144 non-null object
13 year 41144 non-null int64
dtypes: float64(2), int64(6), object(6)
memory usage: 18.7 MB
3. Pandas Data Types
When importing data into a Pandas DataFrame, the entire dataset is read into memory to determine the data types of each column. This process can sometimes result in incorrect data type assignments, such as assuming a column with integer values and missing data is a floating-point data type rather than an integer. To avoid this, it’s important to carefully review and adjust the data types as needed.
To check the types of your data, you can use .dtypes and it will return a pandas series of columns associated with there dtype :
city08 int64
comb08 int64
highway08 int64
cylinders float64
displ float64
drive object
eng_dscr object
fuelCost08 int64
make object
model object
trany object
range int64
createdOn object
year int64
dtype: object
Only three types appear in our dataset, but Pandas has 7 types in general:
- object, int64, float64, category, and datetime64 are going to be covered in this article.
- bool: True/False values. Can be a NumPy datetime64[ns].
- timedelta[ns]: Differences between two datetimes.
4. Integers
Integer numbers. Can be a NumPy int_, int8, int16, int32, int64, uint8, uint16, uint32, or uint64.
You can use numpy.iinfo() to check the machine limit for the integer types and choose one that allows you to save memory without losing precision.
Machine parameters for int8
---------------------------------------------------------------
min = -128
max = 127
---------------------------------------------------------------
Machine parameters for int16
---------------------------------------------------------------
min = -32768
max = 32767
---------------------------------------------------------------
Use pandas.select_dtypes() to select columns based on specific dtype.
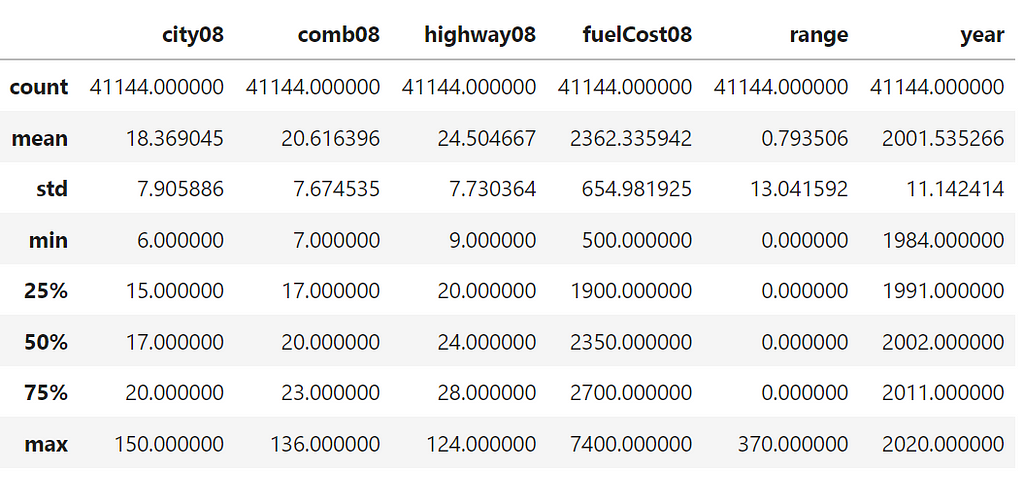
The simplest way to convert a pandas column of data to a different type is to use astype().
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 41144 entries, 0 to 41143
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 city08 41144 non-null int16
1 comb08 41144 non-null int16
2 highway08 41144 non-null int8
3 cylinders 40938 non-null float64
4 displ 40940 non-null float64
5 drive 39955 non-null object
6 eng_dscr 24991 non-null object
7 fuelCost08 41144 non-null int16
8 make 41144 non-null object
9 model 41144 non-null object
10 trany 41133 non-null object
11 range 41144 non-null int16
12 createdOn 41144 non-null object
13 year 41144 non-null int16
dtypes: float64(2), int16(5), int8(1), object(6)
memory usage: 17.3 MB
5. Float
Floating-point numbers. Can be a NumPy float_, float16, float32, float64
You can use numpy.finfo() to check the machine limit for the float types and choose one that allows you to save memory without losing precision.
Machine parameters for float16
---------------------------------------------------------------
precision = 3 resolution = 1.00040e-03
machep = -10 eps = 9.76562e-04
negep = -11 epsneg = 4.88281e-04
minexp = -14 tiny = 6.10352e-05
maxexp = 16 max = 6.55040e+04
nexp = 5 min = -max
---------------------------------------------------------------
Machine parameters for float32
---------------------------------------------------------------
precision = 6 resolution = 1.0000000e-06
machep = -23 eps = 1.1920929e-07
negep = -24 epsneg = 5.9604645e-08
minexp = -126 tiny = 1.1754944e-38
maxexp = 128 max = 3.4028235e+38
nexp = 8 min = -max
---------------------------------------------------------------
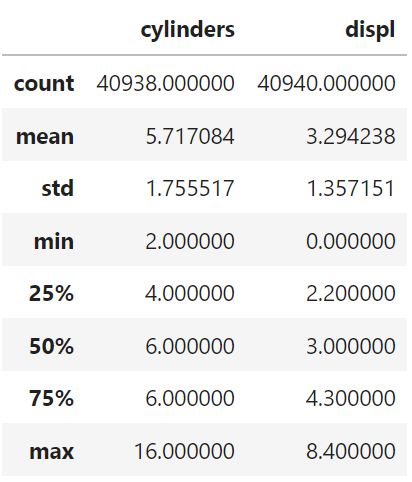
The cylinders column should be an integer dtype but because it has missing value, pandas read it as float dtype.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 41144 entries, 0 to 41143
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 city08 41144 non-null int16
1 comb08 41144 non-null int16
2 highway08 41144 non-null int8
3 cylinders 41144 non-null int8
4 displ 41144 non-null float16
5 drive 39955 non-null object
6 eng_dscr 24991 non-null object
7 fuelCost08 41144 non-null int16
8 make 41144 non-null object
9 model 41144 non-null object
10 trany 41133 non-null object
11 range 41144 non-null int16
12 createdOn 41144 non-null object
13 year 41144 non-null int16
dtypes: float16(1), int16(5), int8(2), object(6)
memory usage: 16.8 MB
6. Objects and Category
Object: Text or mixed numeric and non-numeric values. Can be a NumPy string_, unicode_, or mixed types.
Category: The category data type in pandas is a hybrid data type. It looks and behaves like a string in many instances but internally is represented by an array of integers. This allows the data to be sorted in a custom order and more efficiently store the data.
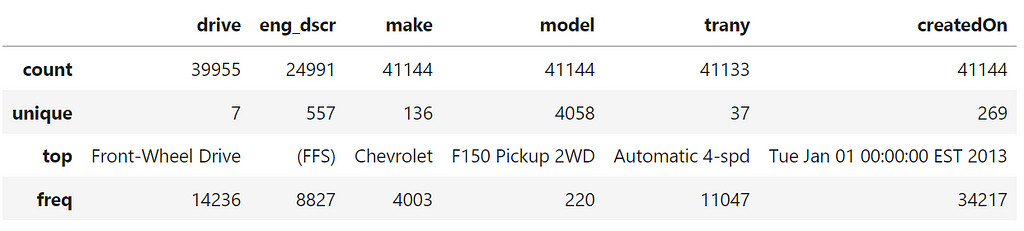
drive and trany have a small number of unique values, so we can convert them to category dtype
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 41144 entries, 0 to 41143
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 city08 41144 non-null int16
1 comb08 41144 non-null int16
2 highway08 41144 non-null int8
3 cylinders 41144 non-null int8
4 displ 41144 non-null float16
5 drive 41144 non-null category
6 eng_dscr 24991 non-null object
7 fuelCost08 41144 non-null int16
8 make 41144 non-null category
9 model 41144 non-null object
10 trany 41144 non-null category
11 range 41144 non-null int16
12 createdOn 41144 non-null object
13 year 41144 non-null int16
dtypes: category(3), float16(1), int16(5), int8(2), object(3)
memory usage: 8.8 MB
8. Datetimes
Date and time values. Having our dates as datetime64 object will allow us to access a lot of date and time information through the .dt API.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 41144 entries, 0 to 41143
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 city08 41144 non-null int16
1 comb08 41144 non-null int16
2 highway08 41144 non-null int8
3 cylinders 41144 non-null int8
4 displ 41144 non-null float16
5 drive 41144 non-null category
6 eng_dscr 24991 non-null object
7 fuelCost08 41144 non-null int16
8 make 41144 non-null category
9 model 41144 non-null object
10 trany 41144 non-null category
11 range 41144 non-null int16
12 createdOn 41144 non-null datetime64[ns]
13 year 41144 non-null int16
dtypes: category(3), datetime64[ns](1), float16(1), int16(5), int8(2), object(2)
memory usage: 5.8 MB
9. NumPy vs. Pandas operations
Sometimes, just converting data to NumPy arrays will speed up calculations like in the example (.values will convert the series to a NumPy array):
78.1 µs ± 1.29 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
36.9 µs ± 579 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Summary
- Proper data type assignment is an important step in exploring a new dataset.
- Pandas generally make accurate data type inferences, but it’s important to be familiar with the conversion options available to ensure the data is properly formatted.
- Correctly assigning data types can result in significant memory savings, potentially reducing memory usage by over 30%.
Maximizing Pandas Performance: 6 Best Practices for Efficient Data Processing was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")