



How to Identify Objects at Pixel Level using Deep Learning in Java
Last Updated on December 25, 2022 by Editorial Team
Author(s): Xin Yang
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
with Deep Java Library
Semantic segmentation is a powerful technique in deep learning that allows for the identification of objects in images at the pixel level. The goal of semantic segmentation is to label each pixel of an image with a corresponding class. In this blog post, we will explore how to use semantic segmentation to identify objects in images in Java.
Note that semantic segmentation is different from instance segmentation, which is able to distinguish several instances belonging to the same class. Therefore, if we have two objects of the same category in the input image, the segmentation map will give the same label for the two objects. To distinguish separate instances of the same class, please refer to instance segmentation.
Semantic segmentation can be applied to a wide range of use cases like self-driving cars, visual image search, medical imaging, and so on. For example, semantic segmentation can be used to accurately identify and classify different objects in the environment, such as pedestrians, vehicles, traffic signs, and buildings.
Deep Java Library (DJL) is a Java-based Deep Learning (DL) Framework. It can be used to create and train models, as well as run inference. DJL provides enriched functionalities to apply Semantic Segmentation to use cases. In this post, we are going to demo how to employ these functionalities to achieve some common use cases.
Prerequisites
To get started, we first need to declare the DJL dependencies in the module’s build.gradle file:
dependencies {
implementation "ai.djl:api:0.20.0"
runtimeOnly "ai.djl.pytorch:pytorch-engine:0.20.0"
runtimeOnly "ai.djl.android:pytorch-native:0.20.0"
}
Run Inference
Once we have dependencies set up, we can start writing code to run inference. In this example, we will use the DeepLabV3 model, which is a state-of-art model for semantic segmentation.
To run inference for Semantic Segmentation, first load the Semantic Segmentation model. Then create a predictor with the given Model and Translator. In this case, SemanticSegmentationTranslator will be used.
After loading the model, feed the model an image and receive a "segmentation map" as output. This can be done by calling Predictor.predict(). The predictor takes an Image as input, and returns a CategoryMask as output. The CategoryMask contains a 2D array representing the class of each pixel in the original image. We can use the following code to do this:
String url = "https://mlrepo.djl.ai/model/cv/semantic_segmentation/ai/djl/pytorch/deeplabv3/0.0.1/deeplabv3.zip";
Criteria<Image, CategoryMask> criteria =
Criteria.builder()
.setTypes(Image.class, CategoryMask.class)
.optModelUrls(url)
.optTranslatorFactory(new SemanticSegmentationTranslatorFactory())
.optEngine("PyTorch")
.optProgress(new ProgressBar())
.build();
try (ZooModel<Image, CategoryMask> model = criteria.loadModel();
Predictor<Image, CategoryMask> predictor = model.newPredictor()) {
CategoryMask mask = predictor.predict(img);
// Do something with `mask`
}
For example, suppose we have a 600x800x3 RGB color image:

The output CategoryMask contains a 600×800×1 mask array representing the class labels as integers. Below is the downsampled mask array:

DJL also provides utilities for visualizing the results of semantic segmentation, such as the ability to overlay the segmentation map on top of the original image to highlight the areas that the model has classified as belonging to a specific class. These can be useful for a variety of use cases.
Use Cases
Use Case 1: Self-Driving Cars
One use case for semantic segmentation is to enable self-driving cars to perceive and understand their surroundings. For example, by accurately identifying the positions of other vehicles on the road, the self-driving car can make informed decisions about how to navigate through traffic. Similarly, by accurately identifying pedestrians and other obstacles, the self-driving car can take appropriate actions to avoid collisions.
To identify the objects in an image, call Predictor.predict() to feed the model with the image below:
CategoryMask mask = predictor.predict(img);

Then, to visualize the result, call CategoryMask.drawMask() to highlight the detected objects on the image.
mask.drawMask(img, 180, 0);

Use Case 2: Extract object from photo
Another use case for semantic segmentation is in the process of extracting objects from photos for passport applications. For example, consider a scenario where an individual is required to submit a passport-style photo as part of their application. In this case, the goal might be to use semantic segmentation to extract the individual’s face from the photo and use it to generate a passport-style photo that meets the required specifications.
To extract the face in an image, call Predictor.predict() to feed the model with the image below:
CategoryMask mask = predictor.predict(img);

Then call the CategoryMask.getMaskImage() method. Note that 15 is the ID of the person's class.
Image person = mask.getMaskImage(img, 15);
person = person.resize(img.getWidth(), img.getHeight(), true);

Use Case 3: Replace background for video conferences
The third use case for semantic segmentation is in the process of replacing the background in an image for video conferences. For example, consider a scenario where an individual is participating in a video conference and wants to replace the background behind them with a more professional or appealing image. In this case, we could use semantic segmentation to automatically extract their foreground (e.g., their body and any objects they are holding) from the background of the image.
To achieve this, we can extract the individual’s foreground from the background of the image. The extracted foreground can then be composited onto a new background image. This allows the individual to replace the background in the image with a more professional or appealing image, which can be useful for video conferences where the individual wants to present a more polished appearance.
To extract the foreground in an image, call Predictor.predict() to feed the model with the image below:
CategoryMask mask = predictor.predict(img);
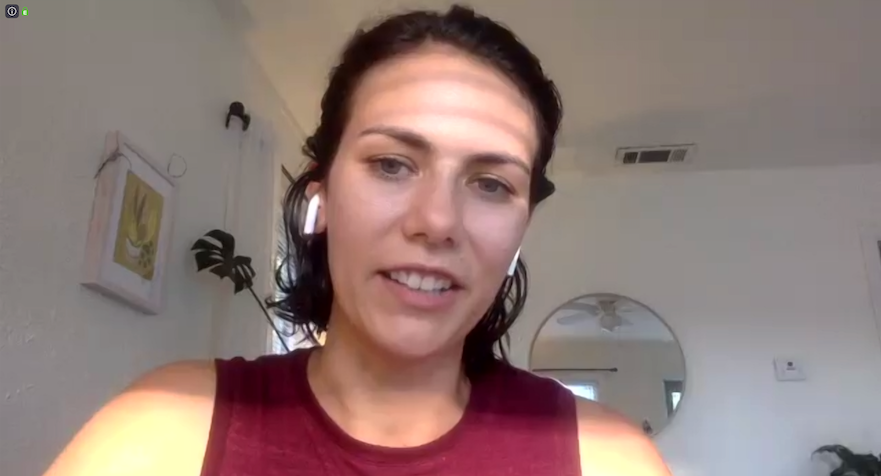
Then replace the background with another image:
Image background = ImageFactory.getInstance().fromFile(Paths.get("image_path"));
Image person = mask.getMaskImage(img, 15);
person = person.resize(img.getWidth(), img.getHeight(), true);
background.drawImage(person, true);

You can find more DJL example code here.
DJL also provided an Android app with semantic_segmentation which can take a picture and run semantic segmentation with a variety of options.
Conclusion
In summary, using the Deep Java Library, it is easy to load a deep learning model for semantic segmentation and use it to identify objects in images at the pixel level. This can be useful for applications such as self-driving cars, where it is important to accurately detect and identify objects in the environment. With the Deep Java Library, you can quickly and easily run deep learning models in Java, making it a valuable tool for any Java developer working in the field of computer vision.
How to Identify Objects at Pixel Level using Deep Learning in Java was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

