



LogBERT Explained In Depth: Part II
Last Updated on October 9, 2022 by Editorial Team
Author(s): David Schiff
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
In the previous article, I covered the basics of the Attention mechanism, and in general, I covered the transformer block. In this part of the series, I would like to cover how LogBERT trains and how we can use it to detect anomalies in log sequences.
Let’s get into the nitty gritty little details of LogBERT.
In the paper (link: https://arxiv.org/pdf/2103.04475.pdf) a log sequence is defined as:

Where S is a sequence of keys (words) in the log sequence. Notice how our log keys are marked with a superscript j to indicate the sequence they belong to and a subscript over k to indicate the index in the series of words.
As usual, when training a transformer, we want to add a token to mark the beginning of the sequence, and the token will be “DIST” as mentioned in the paper. Another special token we will be adding is the “MASK” token. The mask token will be used to cover up words in the sentence.
If you take a look at the last part, you will remember our running example:

As you can see, our log sequence is preprocessed to contain the different special tokens.
DIST — Start of sentence
MASK — Covers up a key in the sequence
EOS — End of a sentence (Although not mentioned in the paper, it is used in the code on GitHub.)
Before I clear everything up about the special tokens, I want to review the training phase of LogBERT.
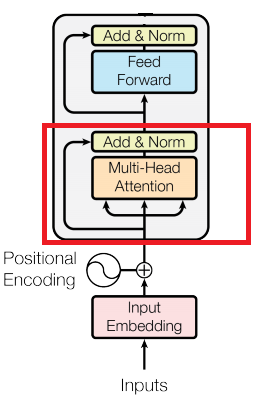
Recall the different parts of the LogBERT architecture:
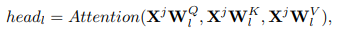

The functions above are just the mathematical descriptions of MultiHead Attention:
And finally, it all comes down to the transformer block’s mathematical description:
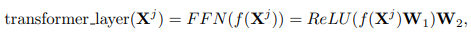
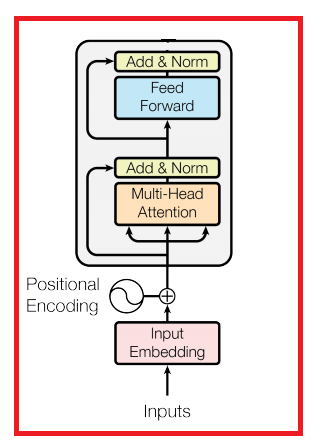
Which is just this whole transformer block:
Beautiful, now we have it all tied together. Usually, transformers have multiple transformer layers, which means we can assign a general transformer function which would be just a sequence of transformer blocks. This is described in the paper as:
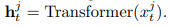
Where h is the output of the Transformer function, this output should be essentially just a vector that encodes all the information about the log sequence defined as X.
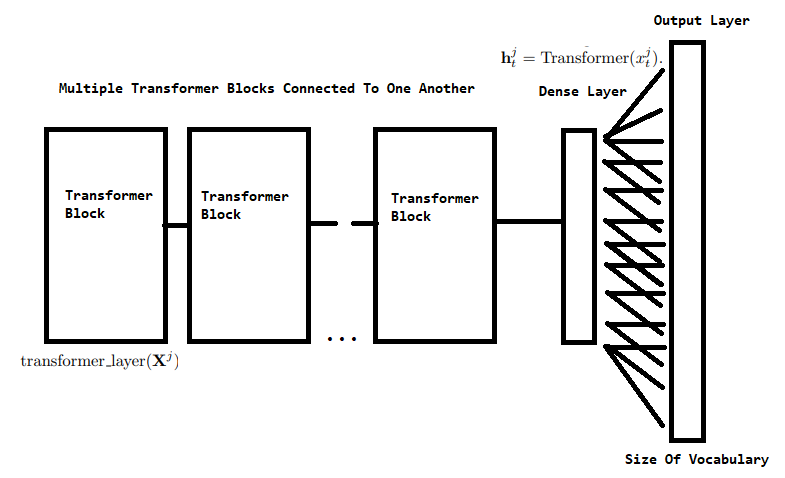
I think the image above sums it all up. Just the general LogBERT architecture. Notice how the output layer is the size of the vocabulary. As usual in classification cases, specifically in our case, we need to classify the word covered under the MASK token. This leads me to the loss function of the final LogBERT model.
As mentioned earlier, all log sequences are preprocessed to contain a masked word. The model will try to predict the word being masked. This is a self-supervised task that the model will have to complete. The loss function for this task is:
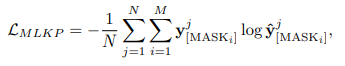
Where y is the real word under the mask and y hat is the probability assigned for the real word under the mask. We can see that the loss is essentially a categorical cross-entropy loss function where the categories are actually words. Notice how the summation is over N and M. N being the number of log sequences and M being the total number of masks chosen in the sentence.
For each log sequence, we choose a random word to mask with a probability of 0.15. We actually choose multiple words to mask, and for each log, we calculate the total loss over the mask prediction in the sentence. The final loss is summed over each sequence and divided by the number of log sequences.
The other task (loss function) that LogBERT needs to minimize is the Volume Of The HyperSphere loss function.
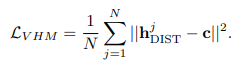
This loss function uses h — as mentioned above. h is the representation of the log sequence (specifically h-dist), and the goal of this loss function is to minimize the distance between the representations of each log and their center. The center is updated with each epoch and is calculated as the average overall log representation.
Finally, both loss functions are used to update the model weights. The final loss function is comprised of a weighted sum of both loss functions.

Now, how do we use LogBERT to find anomalous logs? As proposed in the paper, we go over a log sequence and calculate the predictions for each masked word. We define a hyperparameter g which is the top g most probable words that lie beyond the mask. If the actual word is not in the top g words, we count that word as an anomaly. Now, we define r, another hyperparameter, as our threshold for counting a log as anomalous or not. If there are more than r word anomalies, the log sequence is defined as an anomalous log.
I would like to propose another method to locate anomalous logs. Simply use the final loss function and define a threshold z for which if a log scores higher than z it is an anomalous log.
That’s it, I hope you enjoyed your read. I highly recommend reading up on the original paper and hopping over to GitHub to look at the code itself.
LogBERT Explained In Depth: Part II was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

