



All About Random Forest
Last Updated on April 25, 2022 by Editorial Team
Author(s): Akash Dawari
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
In this article, we will understand Random Forest by answering the following questions:
- What is Random Forest?
- Why we are using Random Forest?
- How does Random Forest work?
- What are the advantages and disadvantages of Random Forest?
- How we can implement Random Forest using python?
What is Random Forest?
Random Forest is a supervised machine learning algorithm. This algorithm is very popular as it can work both on classification problems as well as regression problems. The main idea of this algorithm is to train multiple decision trees, collect their prediction, and according to predict the final output by using the majority count in case of classification or taking the mean in case of regression.

Random Forest may seem very similar to Bagging Ensemble Technique, but there are two main differences present in random forest. The first difference is that, unlike the bagging technique, random forest only uses a decision tree as its base algorithm. The second difference is random forest adds more randomness to the data before it is fed to the base model.
Why we are using Random Forest?
To answer the above question, first, we have to understand the drawbacks of decision trees. As we know decision tree is a very powerful supervised machine learning algorithm on its own. But it has the tendency of getting overfitted on the training data set which causes poor prediction of new data points. In short, a fully grown decision tree mostly provides a model which has low bias and high variance. Here random forest comes into the picture. Random forest converts the low bias, high variance model, into a low bias low variance model by training multiple decision trees at the same time. Each decision tree in the random forest gets a subset of the training dataset and predicts the outcome accordingly. After that random forest collects those outcomes and performs different operations to finally come up with the final prediction.
To know about Decision Tree click on the below link
But this process can also be done by the bagging ensemble technique. So, again the question comes around, why random forest?
The main reason for using random forest over bagging is that random forest adds more randomness to the training data. In a random forest, sampling of the training data is done every time whenever a node in a decision tree splits but in bagging sampling happens at the starting of the tree formation.
How does Random Forest work?
The working of random forest can be broken down into three main steps. The first step will be sampling the data set for each decision tree present in the random forest. Sampling can be done broadly in three way that is:
- Bootstrapping
- Pasting
- Random Subspace
Bootstrapping: In this, subsets of the training dataset are created by picking random rows/tuples with a replacement which means rows of the datasets can be repeated.
Pasting: In this, subsets of the training dataset are created by picking random rows/tuples without replacement which means rows of the datasets cannot be repeated.
Random Subspace: In this, a subset of the training dataset is created by picking random features/columns.
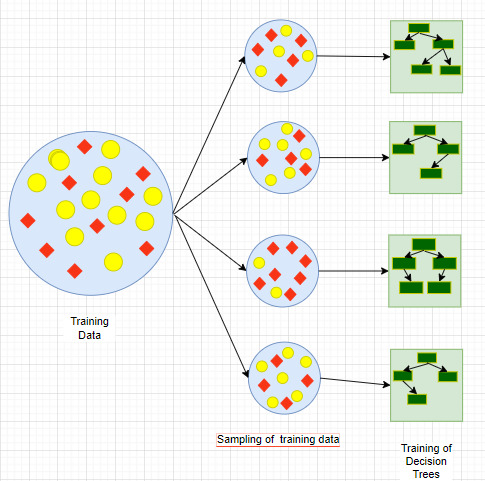
After sampling the second step is to train individual decision tree models parallelly without depending on one another. Now, that the random forest is trained we can feed the data. Each tree will come up with its own prediction according to the sample data provided.
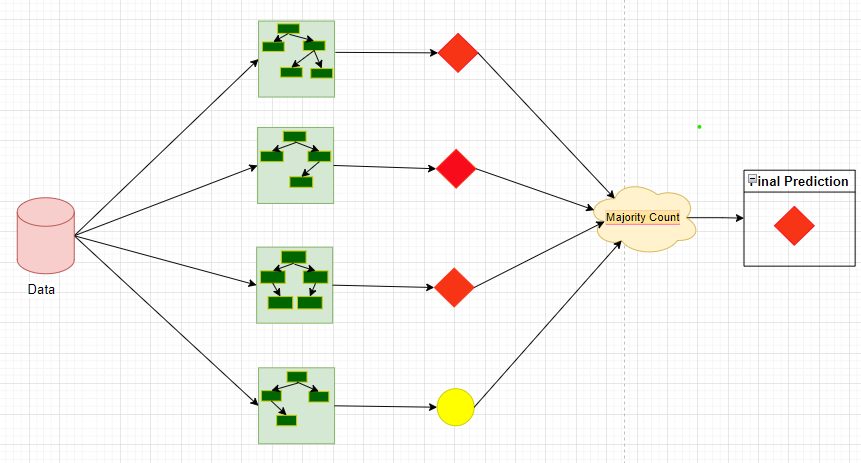
Now, the third and the last step is the aggregate the predictions of each decision tree model and perform a mathematical operation that depends on the problem statement. For the regression problem statement, we usually take the mean of the prediction and give the final output. For classification problem statements we usually take the majority count and give the final output.
To know about Ensemble Technique click on the below link
What are the advantages and disadvantages of Random Forest?
Advantages:
- The main advantage of using random forest is that it reduces the variance of the model without compromising with bias. In short, it converts a low bias high variance model into a low bias low variance model.
- Random Forest can be used for both classification and regression problems.
- Random Forest is more stable as compared to a single decision tree.
- Random Forest can handle missing values and also it is robust to outliers.
Disadvantages:
- Random forest needs more computational power as compared to decision tree as in random forest 100 to 500 trees are training parallelly.
- We can visualize a single decision tree but we cannot monitor the random forest as the number of trees are too many.
How we can implement Random Forest using python?
The implementation of Random Forest in python is very simple we just have to import the scikit learn module. So let’s see how can we implement it.
First, we will import important libraries from python.
Now, we will create a dummy dataset to see how the algorithm works.

Let's visualize the dataset using seaborn library.
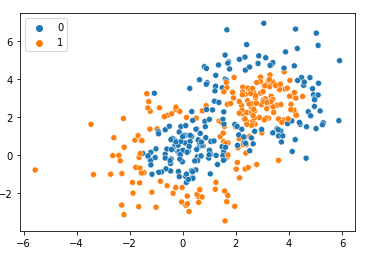
we can observe that there are two classes “orange” and “blue”. we have to classify this. Now the next step is to split the data into training and testing sets.

First, we will try to classify with decision tree to compare how random forest works better than decision tree.
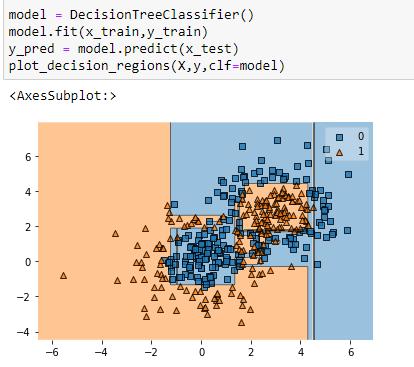
we can observe that decision tree is overfitting the data which causes high variance and reduce the accuracy. Let’s calculate the accuracy of decision tree.

The accuracy is 80%. Now, we will train random forest algorithm.
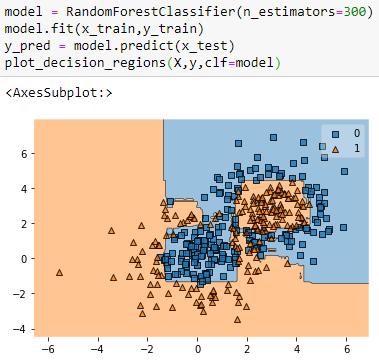
If we compare the decision boundary of the two algorithms we will observe that random forest’s decision boundary has smooth carves and it reduces the overfitting problem.

Also, the accuracy increases by 4% which is 84% in total.
If you want to explore more in the coding part or want to visualize how random forest algorithms fit the dataset. Then, please click the below Github repository link.
Articles_Blogs_Content/All About Random Forest.ipynb at main · Akashdawari/Articles_Blogs_Content
Like and Share if you find this article helpful. Also, follow me on medium for more content related to Machine Learning and Deep Learning.
All About Random Forest was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")