



The NLP Cypher | 01.03.21
Last Updated on July 24, 2023 by Editorial Team
Author(s): Quantum Stat
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
A New Era
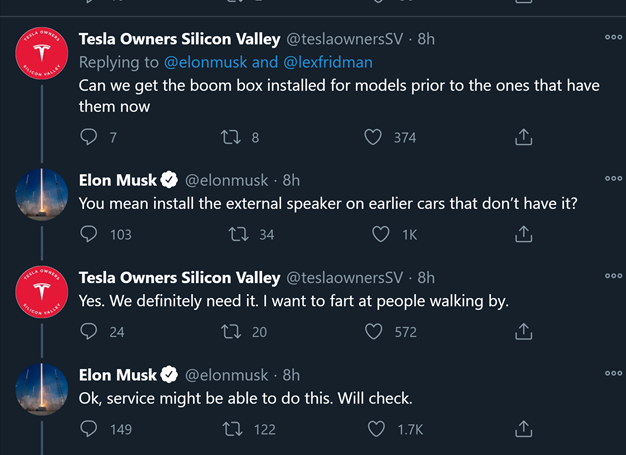
Hey Welcome back, you made it! Now, let us begin 2021 on the right path with an impromptu moment of customer service by Elon Musk:
FYI
If you haven’t read our Mini Year Review, we released it last week while everyone was on holiday ?. Per usual, if you enjoy the read please give our article a ?? and share it with your friends and enemies!
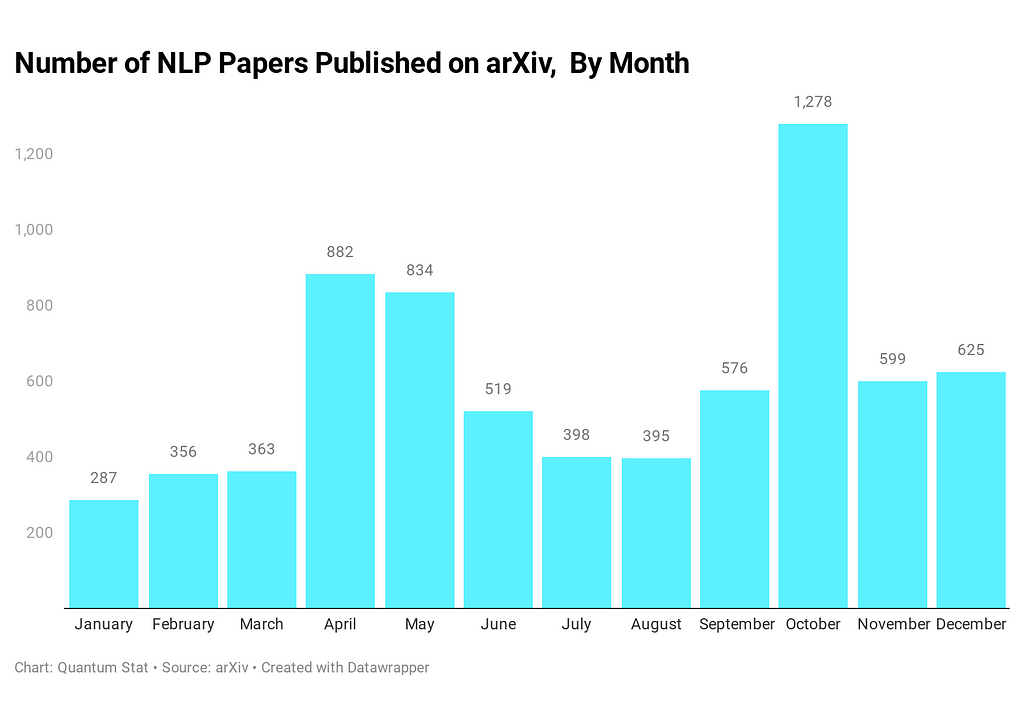
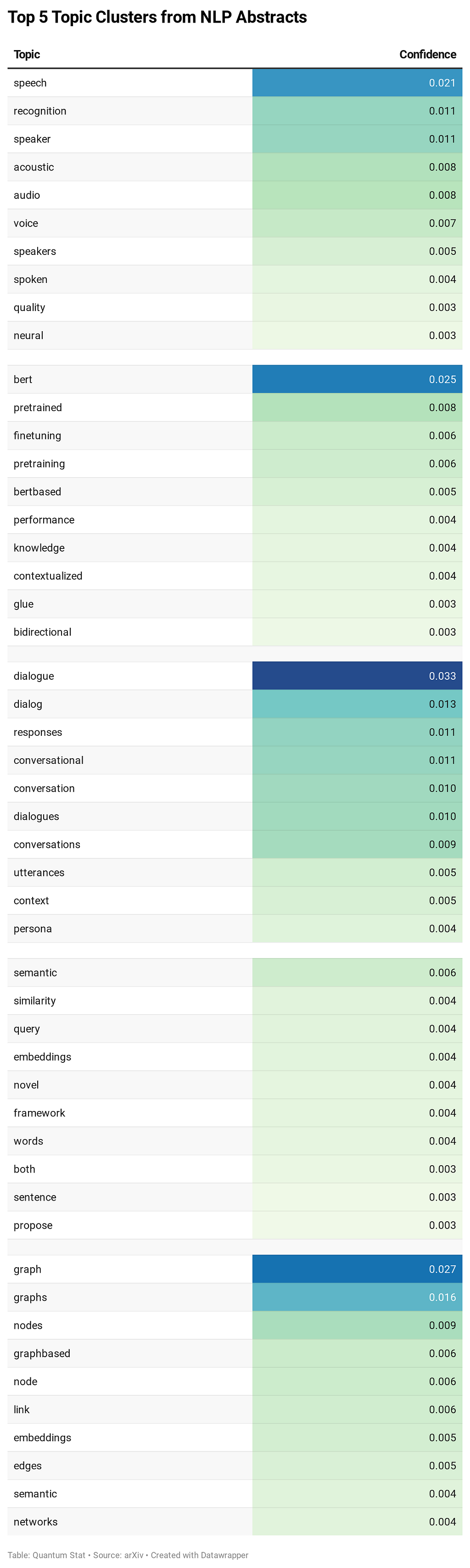
Now, let’s play a game. Let’s say we have all 7,129 NLP paper abstracts for the entire year of 2020. And now we run BERTopic ? on top of those abstracts for some topic modeling to find the most frequent topics discussed.
What do we get?
- speech-related
- bert-related
- dialogue-related
- embeddings-related
- graphs-related
For a more detailed readout of the topics ?
A Pile of 825GBs
The Pile dataset, an 800GB monster of English text for language modeling. ?
The Pile is composed of 22 large and diverse datasets:
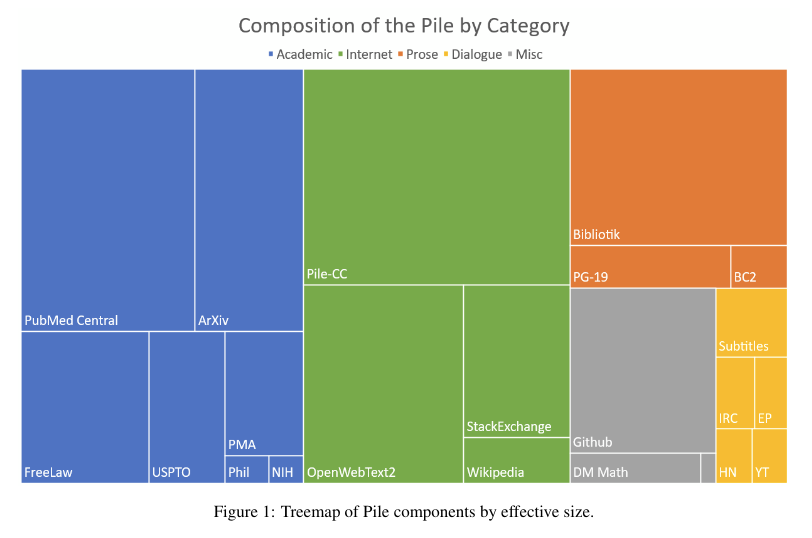
The diversity of the dataset is what makes it unique and powerful for holding cross-domain knowledge.
As a result, to score well on the Pile BTB (Bits per Byte) benchmark a model should
…“be able to understand many disparate domains including books, github repositories, webpages, chat logs, and medical, physics, math, computer science, and philosophy papers.”
The dataset is formatted in jsonlines in zstandard compression. You can also view more datasets on The Eye ? here:
The Pile
The ?
Index of /public/AI/pile_preliminary_components/
Domain Shifting Sentiment on Corporate Filings
Corporations are adapting to NLP models that listen in on filings and other financial-related disclosures. According to a new study, corporations are choosing their words wisely in order to fool machines so they are able to reduce the negative sentiment in their statements.
Paper:
How to Talk When a Machine is Listening: Corporate Disclosure in the Age of AI
ML Book Drops ?
This week, a couple of ML book prints dropped from well known authors in machine learning. The first is from Jurafsky and Martin’s Speech and Language Processing’s book with new chapters/updates:
Highlights:
-new version of Chapter 8 (bringing together POS and NER in one chapter),
-new version of Chapter 9 (with Transformers)
-Chapter 11 (MT)
neural span parsing and CCG parsing moved into Chapter 13 (Constituency Parsing) and Statistical Constituency Parsing moved to Appendix C
new version of Chapter 23 (QA modernized)
Chapter 26 (ASR + TTS)
Speech and Language Processing
Also Murphy’s Probabilistic Machine Learning draft made the rounds this week. And there’s code along with it! Enjoy.
https://probml.github.io/pml-book/book1.html
code:
Open Library Explorer
There’s a new way to explore the Internet Archive for awesome content.
The Open Library Explorer! A new way to browse the Internet Archive
Quantum Ad-List
Someone built ? as a way to block ads ?.
“Made an AI to track and analyze every websites, a bit like a web crawler, to find and identify ads. It is a list containing over 1,300,000 domains used by ads, trackers, miners, malwares.”
The Quantum Alpha . / The Quantum Ad-List
Repo Cypher ??
A collection of recent released repos that caught our ?
LayoutLM V2
Microsoft released the 2nd version of their document understanding language model LayoutLM. If you are interested in SOTA w/r/t document AI tasks. Follow this repo!
WikiTableT
A large-scale dataset, WikiTableT, that pairs Wikipedia sections with their corresponding tabular data and various metadata.
ShortFormer
Shortformer model shows that by *shortening* inputs, performance improves while speed and memory efficiency go up. It uses two new techniques: staged training and position-infused attention/caching.
ExtendedSumm
An extractive summarization technique that observes the hierarchical structure of long documents by using a multi-task learning approach.
Georgetown-IR-Lab/ExtendedSumm
NeurST
NeurST aims at building and training end-to-end speech translation.
From the TikTok folks at Bytedance:
TabularSemanticParsing
Model used in cross-domain tabular semantic parsing (X-TSP). This is the task of predicting the executable structured query language given a natural language question issued to some database.
salesforce/TabularSemanticParsing
AraBERTv2 / AraGPT2 / AraELECTRA
AraBERT now comes in 4 new variants to replace the old v1 versions.
Reasoning over Chains of Facts with Transformers
Model retrieves relevant factual evidence in the form of text snippets, given a natural language question and its answer.
Dataset of the Week: DECODE Dataset
What is it?
A conversational dataset containing contradictory dialogues to study how well NLU models can capture consistency in dialogues. It contains 27,184 instances from 4 subsets from Facebook’s ParlAI framework.
Sample

Where is it?
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
For complete coverage, follow our Twitter: @Quantum_Stat

The NLP Cypher | 01.03.21 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts

Recent Posts




")

