


The Art Of Data Cleaning Using Pandas
Last Updated on July 25, 2023 by Editorial Team
Author(s): Ann Mary Shaju
Originally published on Towards AI.
Mastering essential techniques for optimal data quality
Data is collected from multiple sources and there can be incorrect, outdated, duplicate or inconsistent data. If our data is messy, we get poor prediction results after training the model. Hence Data cleaning is an important task in the lifecycle of a data science project. In this article, I will be using the Pandas library to clean the dataset.
The dataset used in the article is available on GitHub. The original source of the dataset is Kaggle. However, in order to explain a few functionalities have modified the dataset and saved it on GitHub.
The first step in data cleaning is to load the data in a data frame
import pandas as pd
data = pd.read_csv('/content/data.csv')
To see the rows of the data frame, we can use head() or tail()
data.head()

To get information on the dataset we can use info(). info() gives us information about the dataset, like the number of entries and columns, column names, count of non-null values in each column, and the data type of each column.
data.info()

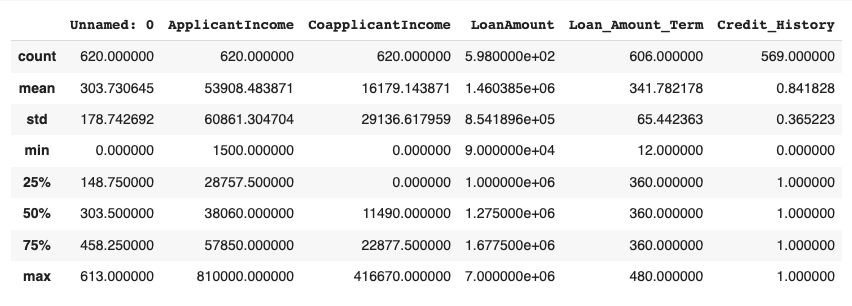
We can use describe() to get some statistical information about the data like mean, standard deviation, percentile, etc.
data.describe()
Now that we have got some information about our data, let's dig into the data-cleaning process.
Handling Duplicate Values
Check if the data has any duplicate values using duplicated(). The sum() gives you the number of duplicate rows in the data frame
data.duplicated().sum()

In order to see the duplicate rows, we can store the duplicated values inside a data frame.
duplicate_rows = data[data.duplicated()]
duplicate_rows

Duplicate values can be removed using drop_duplicates().
data = data.drop_duplicates(ignore_index=True)
# ignore_index=True so that the index is relabeled

After removing the duplicate rows, we have 614 rows in our dataset.
Handling Missing Values
In order to find the missing values in a dataset we can use isnull().
data.isnull().sum().sort_values(ascending=False)
# isnull() - To find the null values
# sum() - To find the sum of null values for each attribute
# sort_values() - To sort the values

We can find the percentage of values missing using the below code
(data.isnull().sum().sum()/data.size)*100

Only 1.7% of the data is missing in our dataset. The data can be missing either because it was not recorded or because the data doesn’t exist. The credit history in our dataset might be missing because the applicant might not have a credit history and left it blank. But the applicant hasn't recorded the information in case of missing values for the loan amount. Analyzing each feature and checking why the values are missing is important in order to handle the missing values of the dataset.
There are multiple ways to handle missing values,
Dropping rows with null values
- We can drop rows with null values using dropna().
data.dropna()

- The resultant data frame contains only 480 rows instead of the 614 rows we had initially.
Dropping columns with null values
- We can drop columns with null values using dropna() by passing the parameter axis with value 1
data.dropna(axis=1)

- The resultant data frame consists of only 7 columns instead of the 14 columns
Dropping rows and columns with null values is not generally advisable unless there are a lot of null values in a particular row or column.
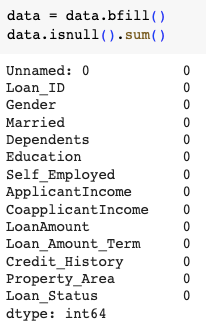
Using bfill method
- bfill can be used to fill the null values with values present in the next row of the data frame
data = data.bfill()
- bfill method can also be used to fill the null values of a column too.
print("Missing values in married column before using bfill: ", data['Married'].isnull().sum())
data['Married'] = data['Married'].bfill()
print("Missing values in married column after using bfill: ", data['Married'].isnull().sum())

Using ffill method
- ffill can be used to fill the null values with values present in the previous row of the data frame
data = data.ffill()

- After using ffill we have 1 missing value since the first row of the dataframe has a null value
- ffill method can also be used to fill the null values of a column too.
print("Missing values in data frame before using ffill: ", data.isnull().sum().sum())
data = data.ffill()
print("Missing values in data frame after using ffill: ", data.isnull().sum().sum())
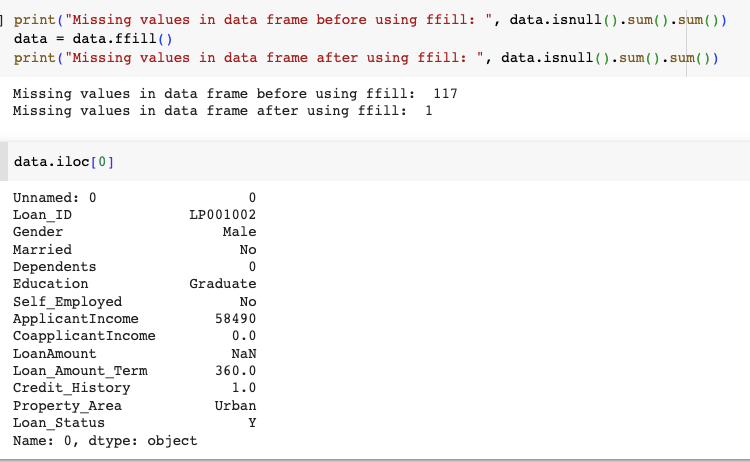
- The missing value in the data frame is because the LoanAmount has the value Nan in the first row of the dataframe.
Using fillna method
- We can use fillna method to fill the Na or Nan values of a data frame.
- We can fill all the missing values of the data frame with any value (zero, constant, mean, median, mode, etc.).
- In the below code, the missing values of the data frame are filled with value 0.
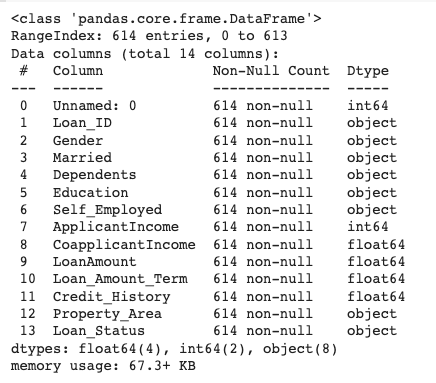
data = data.fillna(0)
data.info()
- Using the fillna method, we can also fill in the missing values of a single column.
- The below code fills the value of column Self_Employed with the mode
print("Missing values in self employed column before using fillna: ", data['Self_Employed'].isnull().sum())
data['Self_Employed'] = data['Self_Employed'].fillna(data['Self_Employed'].mode()[0])
print("Missing values in self employed column after using fillna: ", data['Self_Employed'].isnull().sum())

- In order to handle missing values of numerical variables, we use mean and median. The mean is used when the data is normally distributed, and the median is used when the data is skewed.
- In order to handle categorical variables, we use mode or any constant
Inconsistent Data Entry
So far, we have discussed handling duplicate values and missing values. It is also important to check the values in each column to ensure the data entered in each column is valid. While checking each column, we need to ensure the following things,
- The data type is the same for the entire column.
- The values entered are valid. For example, the applicant's income should always be a positive value, the age of the applicant should match the difference between the current date and the date of birth, the total digits of a phone number should be the same for a country, etc.
- The units of measurement should be the same throughout the column. For example, the weight of one person cannot be measured in pounds and another in kilograms.
- It is important to remove whitespaces and spelling errors. It is also important to ensure that the data is either in upper case or lower case. If we have a column of countries and we have values like
Ger many&Germanyit is important to remove the whitespaces fromGer many
Whenever we find an inconsistent data entry, we can remove, correct, or impute the data. As the data frame can have many values, it is not possible to go and check manually each entry; however we can use unique() to get the unique entries of each column.
data['Education'].unique()

After using the unique function, we understood that there is a Graduate and graduate present in the Education column; hence it is necessary to normalize the entire column in either lowercase or uppercase.
data['Education'] = data['Education'].str.lower()
data['Education'].unique()

In the above code, we have converted all the values of the Education column to lowercase. In case there are multiple values in a column, we can use the sort function so that similar values occur together.
Conclusion
Data cleaning is an important task in the lifecycle of a data science project. Data cleaning enhances the data quality, accuracy, and reliability of data for making decisions and deriving insights. In this article, we talked about some techniques for effective data cleaning and preparation. We learned how to handle duplicates and missing values. We also discussed how to handle inconsistent data entry with some examples.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

