



Tackle Imbalanced Learning
Last Updated on July 24, 2023 by Editorial Team
Author(s): Satsawat Natakarnkitkul
Originally published on Towards AI.
Imbalanced learning U+007C TOWARDS AI
All you need to know on how to tackle imbalanced learning issues
Introduction
If you have been in the field of data science and have been working as part of the team or lead the team, you will probably come across the issue of data imbalance. Those who have been working in Financial, you may need to build a fraud detection model (identify the fraudulent transactions rather than the legit, very common, transactions). In industrial, you may want to identify which equipment about to fail then the one which will continue to operate.
Actually, most of the problems we are trying to solve have to do with data imbalance. There are really no 50–50 distribution (or every hard to encounter) of positive and negative classes for classification problems.
The issues
The problem with imbalanced learning can be categorized into three main issues.
- A problem-definition level issue occurred when we do not have enough information to define the learning problem. This also includes the understanding of how to properly judge/measure the classifier.
- The data-level issue happened when we do not have enough training data. An example is “absolute rarity”, where we do not have sufficient numbers of minority class examples to learn.
- The algorithm-level issue is the inability of the algorithms to optimize learning for the target evaluation criteria. Any algorithms which used greedy search methods are having issues in finding rare patterns.
Evaluation Metrics for Imbalanced problem
In this first section, it is important to understand how we will use meaningful and appropriate evaluation metrics for imbalanced data, and this will ultimately translate into providing accurate cost information to the learning algorithms. Choosing the right evaluation metric is one way to solve the problem-definition level issue.
Confusion matrix, Precision, Recall, and F-measure
Let’s recap the confusion matrix; normally, the class whom we want to predict/classify will be ‘positive’. And precision and recall, when we mentioned, will be based on the positive class.

The precision of classification is essentially the accuracy associated with those rules, while recall is the percentage of examples of a designated class that are correctly predicted. Another meaning for the recall is the measurement of coverage of the minority class.
Another popular measurement is F-measure, it is parameterized and can be adjusted to specify the relative importance of precision vs. recall, F1-measure is the most often used when learning from imbalanced data (which weights both precision and recall equally). Let’s observe its formula below.

For F2-measure, this will set β equals to 2. The intuition behind the F2 measure is that it weights recall higher than precision. Hence, making F2 measures more suitable in certain applications where we want to emphasize the importance of classifying correctly as many positive samples as possible.
ROC and AUROC
ROC analysis can sometimes identify optimal models and ignore suboptimal ones independent of the cost context or the class distribution. To put in a more simple context, ROC analysis does not have any bias toward models that perform well on the majority class at the expense of the majority class. AUROC summarizes this information into a single number, which facilitates model comparison when there is no dominating ROC curve.
ROC analysis is a plot of the TPR (true positive rate) against FPR (false positive rate) for a number of different candidate threshold values between 0 and 1. It is a plot of the false positive rate (x-axis) versus the true positive rate (y-axis) for a number of different candidate threshold values between 0.0 and 1.0. Put another way, and it plots the false alarm rate versus the hit rate.

Precision-Recall Curve and AUCPR
As previously discussed in the previous section, precision and recall are good metrics to evaluate the binary classification, especially imbalanced classes.
The key to calculate both metrics are heavily concerned with the correct prediction of the positive class, hence the minority class for this problem.

A precision-recall curve is a plot of the precision (y-axis) and the recall (x-axis) for different thresholds, much like the ROC curve.
There is one difference from the ROC curve that the baseline is no longer fixed (in ROC, this is a diagonal line). But the baseline for the precision-recall curve is determined by the ratio of positive and negative class and is a horizontal line.
So when to choose between ROC and precision-recall curves?
In most cases:
- ROC curves should be used when there are roughly equal numbers of observations for each class.
- Precision-Recall curves should be used when there is a moderate to large class imbalance.
ROC can present the optimistic picture of the model on imbalanced class data sets. And it might be deceptive and lead to incorrect interpretations of the model ability.
Fixing the data
In this section, we will focus on how we can solve the issue which happened on the data-level.
Actually, one of the best (or better way) to tackle this is to enrich the data by either getting more positive samples or adding more features to the existing data.
However, getting more positive samples may be difficult; otherwise it should be an imbalanced data problem. There are several methods to mitigate the effect of imbalanced data.
Oversampling, undersampling and augmenting the data
There are 2 methods that deal directly with the dataset, and another method which uses the synthetic (or augment) technique on the minority class.
1) Oversampling — this is the method of replicating some observations of the minority class to increase its cardinality. The main advantage is no information loss as all data from the majority and minority classes are being kept. However, this process is prone to over-fitting.
2) Undersampling — this is the method of sampling the majority-class data to balance with minority-class data. Given it involves removing the observations, we may lose the useful information from the training data set.

- generating synthetic data consists of creating new synthetic points from the minority class (see SMOTE method for example) to increase its cardinality
3) Augment / synthetic data — this is the method where we are creating new synthetic (another method of augmenting) points from the minority class.
The popular methods are SMOTE (Synthetic Minority Oversampling Technique) and ADASYN (Adaptive Synthetic).
SMOTE works by looking at the existing minority data and synthesizing the new data points at a random location in the line between the current observation and its K-nearest neighbors (this k is required for the function).
ADASYN builds on the SMOTE methodology by using the weighted distribution for different minority instances based on their level of learning difficulty. Hence, more synthetic data will be generated for minority instances that are harder to learn (help to shift the classification boundary).
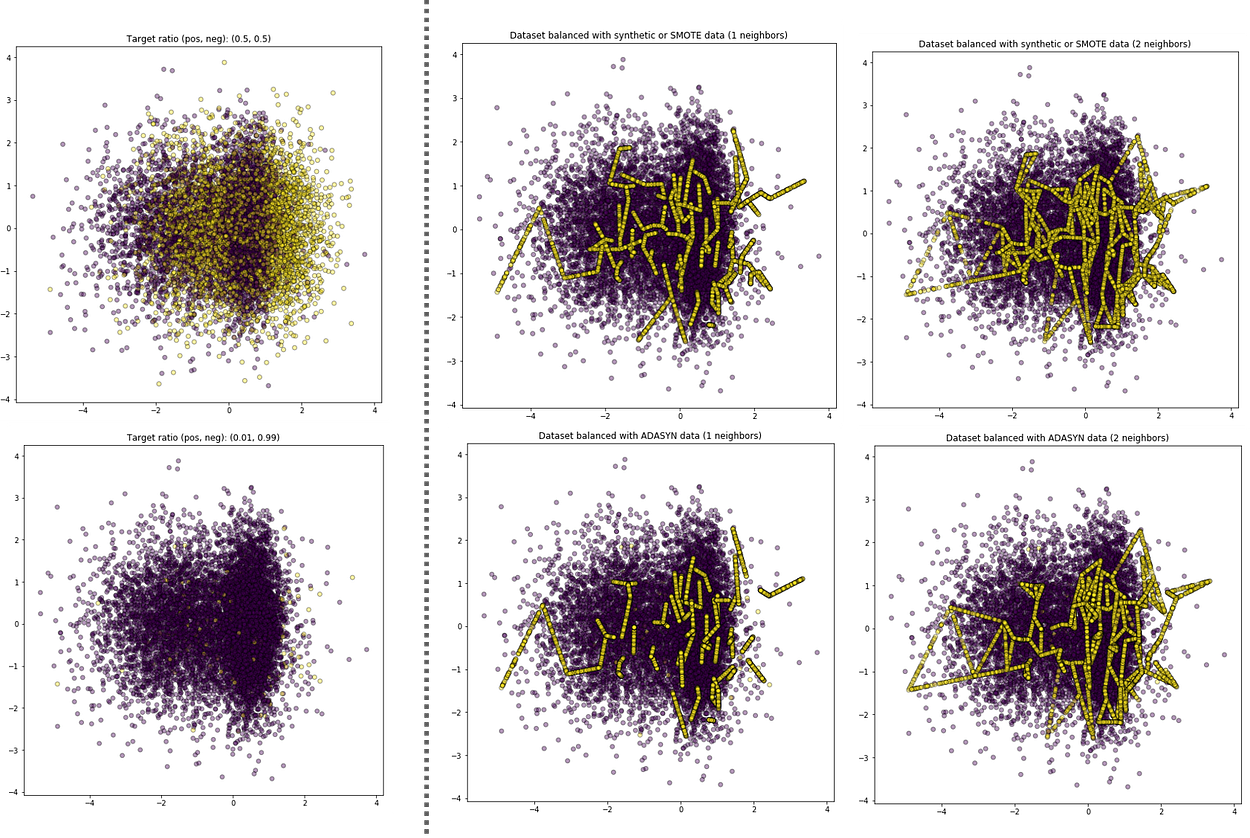
To end this section, all of the sampling methods should be used with cautions; here are two points to take into account.
- The sampling method should only be done only on training data.
- Any sampling methods could be viewed as we are attempting to change the reality of how the data is representing, so it requires to be careful and to have in mind what it means for the outputted results of our classifier.
Optimize the learning algorithm
When all the methods have failed, sometimes we need to step back and look at the problem again. Maybe we need to rethink and optimize how we use and tune the classifier algorithm to deal with minority class, specifically.
Avoid Divide-and-Conquer search approach
The algorithms utilize the search method of the divide-and-conquer approach to recursively partition the search space can have difficulty in finding rare patterns, as it is leaning toward the separation of the majority class. It is suggested that learning methods that avoid or minimize these 2 approaches will tend to perform better when there is imbalanced data. An example is genetic algorithms, which are global search techniques that work with populations of candidate solutions rather than a single solution and employ stochastic operators to guide the search method.
Optimize the Search Method by using the Metrics designed to handle the Imbalanced Data
We have explored several evaluation metrics in the early section to help with the problem-level issue. However, they can also play a role here in the algorithm level to guide the search process.
It is using genetic algorithm-based classification system with F-measure that controls the relative importance of precision and recall in the fitness function, so a diverse set of classification rules are evolved, with some having high precision and others high recall. The expectation is that this will eventually lead to rules with both high precision and recall.
Another method is to separate into two phases; first, optimizes by the recall to maximize the coverage and, secondly, optimizes by precision to remove the false positives.
Algorithms that Implicitly Favor Minority Class
Cost-sensitive learning algorithms are one of the most popular for handling imbalanced data. To better understand what it is, let us think about how important we are to detect the fraud transaction and legit transaction. We can see that fraud transactions will cost more to the company (both financial and reputation) than incorrectly flagging legit transaction as fraud (delay to customers’ end due to payment). Based on this example, the errors between misclassification are no longer equal.
There are several methods for implementation, including weighting the training observations in a cost-proportionate manner and building the cost sensitivity into the learning algorithm.
Learn only the Minority Class
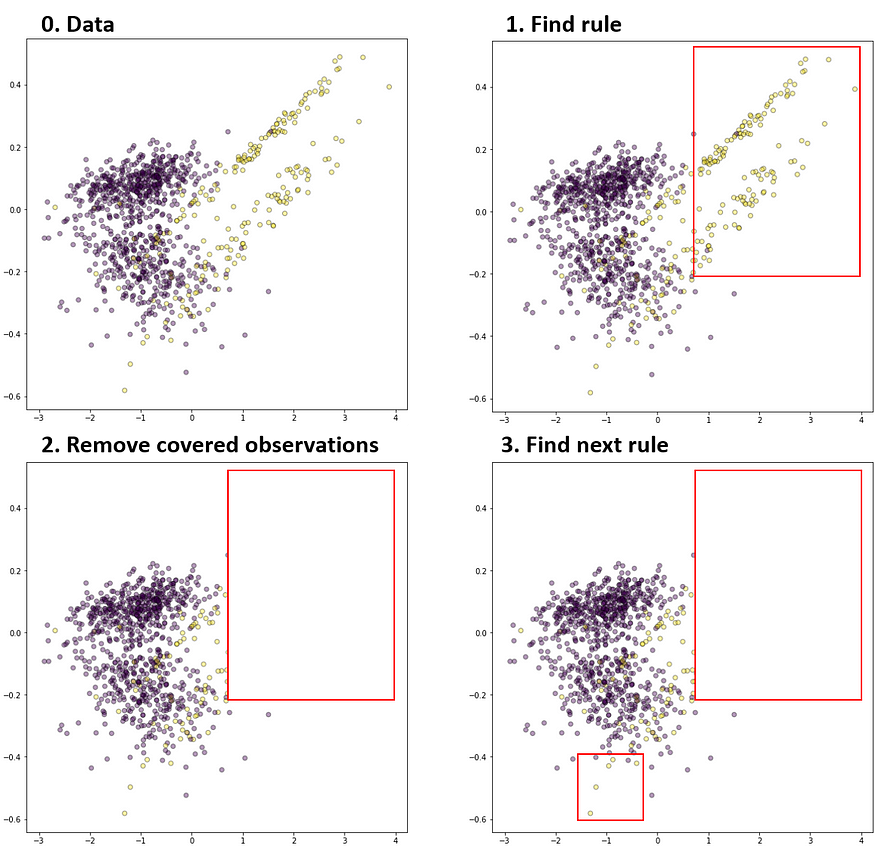
There are several approaches to only learn classification rules for the minority class. One is a recognition-based approach; it learns only from training observations associated with the minority class to identify the hidden patterns shared among the training observations.
Other, which is more common, approach learns from the training observations which belong to all classes but learns the rules to cover the minority class first. The most popular algorithm is the Ripper algorithm, which builds rules using a separate-and-conquer approach. Ripper generates the rules for each class from the rarest to the most common class. At each stage, it grows the rules for one targeted class by adding conditions until no observations are covered, which belong to the other class (see illustration below).
Probability cut-off
This approach does not try to solve any issues state above, but rather deal on how we can use the classifier result. Here, we will use the prediction outputs as the probability of each class for the observation. We can then put the prediction and produce the gain/lift table to evaluate the cut-off point.
Using the below sample gain table as an example, we can then use this information (number of observations, hit rate, % of default, cumulative and lift information) combined with the business/problem objective to select which score / predicted probability to use.

End Notes / Takeaways
If you have read up to this point, congratulation!! Hopefully, you have learned and brought some of the concepts and used them in a real problem.
- Sometimes, it is better to think and rethink the problem. Have a clear goal and, if possible, break down them down to achievable sizes.
- Use appropriate evaluation metrics when dealing with imbalanced learning; these metrics should be based on the goal you want to reach.
- Optimize the machine learning algorithm to handle the imbalanced learning. Cost-sensitive learning, one class learning, class re-weight are some of the examples.
- Re-sampling techniques (oversampling, undersampling) can be used, but with caution. Because doing this, we are changing the reality of the data to the learning algorithm.
Thanks for reading and happy learning!!!
Satsawat Natakarnkitkul — AVP, Senior Data Scientist — SCB — Siam Commercial Bank U+007C LinkedIn
I’m data enthusiast and utilize both technical and business understanding to drive and deliver the insight of the…
www.linkedin.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

