


Sentiment Prediction of Google Play Store Reviews with Tensorflow 2.0
Last Updated on July 20, 2023 by Editorial Team
Author(s): Juan Manuel Ciro Torres
Originally published on Towards AI.
How to train your own algorithm to classify the sentiment of the reviews of your app from scratch
You spend hours and hours creating your app, and finally, you decide to publish your app in order to the world enjoy your incredible application, but how do you know if your customers are really enjoying your app? Well, this is your lucky day, you have the solution in your hands.
Create a sentiment prediction of your customers' reviews for your app.
Steps:
- Get the data
- Preprocess the data
- Preprocess the text
- Vectorize the data
- Create the model
- Train the model
Get the data:
For this analysis, we are going to use a dataset that contains different reviews for different applications ( 1074 different applications) of the play store and the sentiment for differents reviews classified by humans. The classification is categorized into three kinds: positive, neutral, and negatives.
The dataset contains in total of five columns, and you can get it from here.
Preprocess the data:
The first step is to look at how our data looks after being loaded as a data frame:
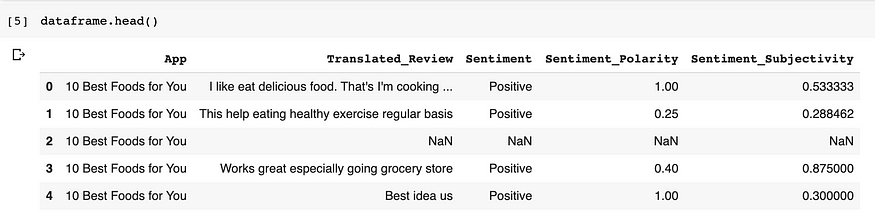
When we look at the data, we can see that there are NaN values, so we need to delete such data. And for the principal objective of our project, we only need two columns, the column “Translated_Review” and the column “Sentiment.”
Preprocess the text
We need to do some transformation to make our data understandable to our neural network; we must apply three principal transformations to get this. The first is put all the text in lower case, the second is to remove all the punctuation marks and convert all the words that were together into separate words, and the final step is to delete all the stop words; these are words that don’t have meaning by themselves, such as conjunctions or prepositions; we are going to use the library link for this purpose.
For this transformation, we create a function call preprocess_text:
And finally, we create a lambda method with this function to apply in the “Translated_Review” column with the function apply.
Note: Understanding and being able to use regular expressions is a prerequisite for doing any Natural Language Processing task. If you’re unfamiliar with them perhaps start here: Regex Tutorial
Vectorize the data:
This section will aim to convert a text string into a vector so that it can be treated by the neural network. First, in order to generate the training and validation sets, we will separate the data frame into two independent variables so that we can treat them separately, in this function we could define if we want to work with the three classes (multiclass classification problem) or only with the two main class (binary classification task):
Create the model:
Finally, the funny part, the model. First, to be able to evaluate our model, we need to split our data into a train and validation set. We are going to use the function of sklearn “train_test_split” to do that. We define a validation size of 20% of the data.
Finally, before creating our network, we need to tokenize the data, remember that the models in general only receive numbers, so we first need to convert our text in numbers. To do this, we are going the use the function “Tokenizer” from Keras. In this part, we need to define the max length of the review that we are going to analyze, and the number of words that we are going to tokenize. The last preprocessing step is to fill in the uncommon words with zero; this technique is called “padding.”
We need to define our model, and we know that for this kind of problem, the most common algorithms are the recurrent neural network, in special a type of RNN call LSTM. This kind of layer is used because of their power to identify long patters in the data, and the text problem needs to analyze all the relationships between each word. We need to compile our model, so we define three things:
- The loss function: We are going to use the “sparse categorical cross-entropy” because we have various classes.
- The optimizer: In this case, we use rmsprop because it has a good performance in this type of problem.
- The metric: We are going to evaluate our model by accuracy.
And finally, we only need to train our model, putting our training data as an input, run the model by three times (3 epochs) and select and batch size of 128 examples per epoch.
Final notes:
- Thanks to Marc Munar for the example of how to apply an LSTM in a real case and Juan Gabriel Gomila Salas because of his amazing course
- All of the code used in this tutorial, along with supplemental code, can be found in this Google Colab.
- If you have any questions or comments, please send me an email to jmcirot@unal.edu.co
Thanks for reading
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

