



Querying Synapse Analytics Delta Lake from Databricks
Last Updated on July 17, 2023 by Editorial Team
Author(s): Guilherme Banhudo
Originally published on Towards AI.
A step-by-step guide on how to connect (query) Azure Synapse Analytics Delta Lake data from Databricks for both dedicated and serverless pools.
Problem Statement
In recent years, especially with the advent of Delta lake, it became ever more common to use Databricks as a main source of processing and use internal services, like Azure Synapse Analytics, to manage access to said resources.
It then becomes increasingly common to require reading the data stored in Synapse Analytics via Databricks, especially when you are interested in conducting complex analysis or Machine Learning via Databricks. However, the process is not straightforward, and the documentation — at the time of this article — is severely lacking.
This requirement can be particularly important if you abstract your stored objects — for instance, Delta files — via External Tables or External Views.
Solution
The solution consists of three straightforward — albeit, long — steps:
- Selecting and configuring the appropriate Databricks connector
- Configuring Azure Synapse Analytics
- Connect Databricks to Azure Synapse Analytics
1. Selecting and configuring the appropriate Databricks connector
Databricks offers an out-of-the-box connector for Azure Synapse Analytics as indicated in this guide. However, this connector only works for Dedicated SQL Pools. If you want to connect to a Serverless SQL Pool, you will have to use Microsoft’s Apache Spark connector: SQL Server & Azure SQL.
To install and make the connector available for your Cluster instance, you can install the connector directly via the Install wizard within your Databricks cluster or use, for instance, a Maven coordinate.
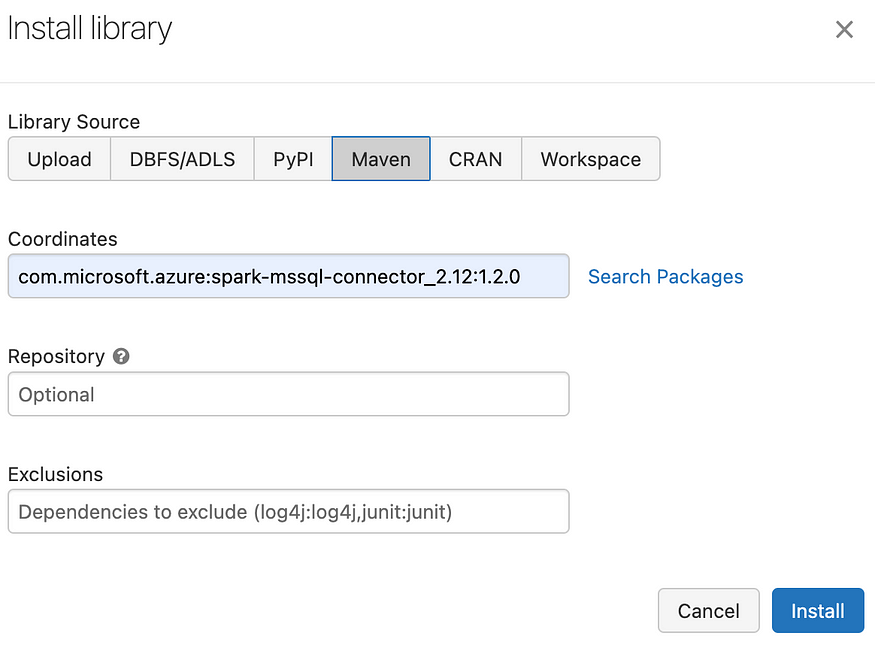
However, this is not an easily maintainable process, especially if you want to use dbx to deploy your instances. The process can be streamlined by using dbx to manage your deployments — CI/CD. To incorporate it in dbx, add the following line to your deployment.json (see the official documentation for details on how to add maven dependencies here):
libraries:
- maven:
coordinates:"com.microsoft.azure:spark-mssql-connector_2.12:1.2.0"
2. Configuring Azure Synapse Analytics
The hardest — and arguably the most confusing — part of the process consists of configuring Azure Synapse Analytics to allow external entities to query your objects.
2.1- (Optional) Create a Database level Master Key
The first step is to make sure your Database has a master key used to protect the credentials.
Note: You may skip this step if you have already set up your database.
USE database_name;
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'strong_password';
2.2- Create a Database Scoped Credential
The second step requires us to set up a scoped credential that manages access to the storage files used in the Data Lake containers.
This step requires a Shared Access Signature SAS Token.
To retrieve it, open your Azure Portal, navigate to Storage Accounts, select your Storage Account and open the Shared access signature menu:
Azure Portal > Storage Accounts > Storage Account > Container > Shared access signature

We then need to generate a SAS Token. Make sure to select only the required permissions and hit the Generate SAS button:

At the bottom, you will find a series of generated blocks that contain our SAS token.
Note: The token has the format “?sv=202******”, when pasting to the SQL script you must ignore the question mark prefix, ?. Meaning, the secret “?sv=202******” becomes “sv=202******”
CREATE DATABASE SCOPED CREDENTIAL ProdReadAccess
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET='sv=your_secret'
GO
2.3- Create the External Data Source
Since our Data exists in an Azure Blob Storage container, we have to make it available to Azure Synapse Analytics via the concept of the External Data Source.
In this case, we will create an External Data Source named prod_lake, assign the ProdReadAccess credential, and lastly, specify the Delta Lake Storage location:
Note: If you do not know your storage location address, proceed to step 2.3.1.
IF NOT EXISTS (SELECT * FROM sys.external_data_sources WHERE name = 'prod_lake')
CREATE EXTERNAL DATA SOURCE [prod_lake]
WITH (
LOCATION = 'https://yourstorage.dfs.core.windows.net/your_container',
CREDENTIAL = ProdReadAccess
)
2.3.1- (Optional) Retrieve the Data Lake Storage endpoint
In the previous step, the LOCATION parameter was inserted under the assumption that it was known beforehand. If you do not know the parameter’s value, open your Storage Account, go to the Endpoints section and retrieve the Data Lake Storage link.
Azure Portal > Storage Accounts > Storage Account > Container > Endpoints

2.4- Create the authentication credentials
2.4.1- Create a Login
Start by creating a LOGIN named databricks_synapse:
CREATE LOGIN databricks_synapse WITH PASSWORD = 'your_strong_password';
2.4.2- Create a User from the Login
CREATE USER databricks_synapse FROM LOGIN databricks_synapse;
2.4.3- Grant the User Permission to Read the Container items
GRANT REFERENCES ON DATABASE SCOPED CREDENTIAL::[ProdReadAccess] TO [databricks_synapse];
2.4.3- Change the User’s role to allow reading from the SQL instance
ALTER ROLE db_datareader ADD MEMBER [databricks_synapse];
2.4.4- (Optional) Create a View or External Table on the Delta resource
Create a View (or External Table) on the external Delta resource using the created Data Source, prod_lake:
CREATE VIEW dw.test_view AS
SELECT *
FROM OPENROWSET(
BULK 'test_delta/',
DATA_SOURCE = 'prod_lake',
FORMAT = 'DELTA'
)
AS [r];
3. Connect Databricks to Azure Synapse Analytics
Finally, we need to instruct Databricks to connect to Azure Synapse Analytics and query a specific table — or execute a query.
3.1. Retrieve the (Dedicated or Serverless) Pool Hostname
In order to connect to the Dedicated or Serverless Pool, we need its specific SQL endpoint address. This allows us to select the Pool instance based on the required workload.
The easiest way to retrieve it is via the Synapse Analytics workspace. Open the SQL pools separator and access the desired SQL pool — built-in by default or, serverless.
Azure Portal > Azure Synapse Analytics> *select your instance*> Open Synapse Studio > Manage > SQL Pools

By selecting the desired SQL Pool, a Properties window pops up containing the required information:

3.2. Query the Azure Synapse Analytics Endpoint
This section and its details are extensively covered in this Microsoft guide.
spark.conf.set("fs.azure.account.key.<your-storage-account-name>.dfs.core.windows.net",
"<your-storage-account-access-key>")
hostname: str = "prodsynapse-data-ondemand.sql.azuresynapse.net"
database: str = "your_database_name"
port: int = 1433
user: str = "databricks_synapse"
password:str = "your_strong_password"
table_name: str = "dw.test_view"
display(spark.read
.format("jdbc")
.option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver")
.option("url", f"jdbc:sqlserver://{hostname}:{port};database={database}")
.option("user", user)
.option("password", password)
.option("dbtable", table_name)
.load().limit(10))
If you want to execute a query instead, replace the dbtable option with the query and the corresponding argument:
spark.conf.set("fs.azure.account.key.<your-storage-account-name>.dfs.core.windows.net",
"<your-storage-account-access-key>")
hostname: str = "prodsynapse-data-ondemand.sql.azuresynapse.net"
database: str = "your_database_name"
port: int = 1433
user: str = "databricks_synapse"
password:str = "your_strong_password"
query: str = "select top(10) * from dw.test_view"
display(spark.read
.format("jdbc")
.option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver")
.option("url", f"jdbc:sqlserver://{hostname}:{port};database={database}")
.option("user", user)
.option("password", password)
.option("query", query)
.load().limit(10))
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

