



Paper Review Monolith: Towards Better Recommendation Systems
Last Updated on December 6, 2022 by Editorial Team
Author(s): Building Blocks
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Collisionless Embedding Tables, Online Training, and Fault Tolerance
Recommendation Systems are the most prevalent application of machine learning. We see them in action on every social media platform, streaming website, online marketplace, and almost any website that has ads being displayed.
Despite their prevalence, there’s plenty of room for improvement in how Recommendation Systems are designed. In today's article, we’ll review a recent paper published by a team at Bytedance, the parent company of TikTok. Real-Time Recommendation System With Collisionless Embedding Table
The authors highlight three major contributions of their work:
- Collisionless and Expiring embedding tables to handle categorical data.
- An Online Training Platform to ensure that models are updated as user preferences change.
- Periodic Snapshots (copies) to make the system fault tolerant.
Problem 1: An Exploding Feature Space
At its core, a recommendation engine is trained to predict if something displayed to you will be clicked on or not. Recommendation engines try to make this prediction using two types of data:
- Data about the user could be features like age, login times, previous purchases/clicks/views, etc.
- Data about the item being displayed. For example, if you were on a food delivery app, the features being used could be the type of cuisine, ingredients, restaurant rating, etc.

In a lot of cases, the features used to train a model can be categorical variables i.e., non-numerical values that can be categorized e.g. fusion, burger, pizza, etc. in the case of types of cuisine. It should also be noted that users/items themselves are categorical variables because they are usually represented in the form of a unique identifier (ID).
In deep learning, a common method of handling categorical variables is to use embeddings. Where each category is mapped to an n-dimensional vector. An embedding layer is usually just a look-up table where a unique ID gets mapped to its corresponding vector representation.
Categorical variables pose a problem because there can be new categories that pop up at any time. There might be new food items that start popping up on any given day, or an app might have new users signing up. Theoretically, there is no limit to the number of categories one could have for any given feature.
However, we cannot have an embedding layer with infinite memory. The implication of this is that it is possible for multiple IDs to be mapped to the same n-dimensional vector. Assume that we are tasked with fitting 11 balls into 10 boxes, no matter what we do at least one of the boxes will contain more than one ball. This scenario is what we call a collision. Collisions could hinder the Machine Learning model’s ability to distinguish between different categories.
Solution
The authors solve this problem by using:
- Cuckoo Hashing
- Filtering and Evicting Categories
Hashing is the concept of taking an input of any size and mapping it to an output of a fixed size. An ideal hash function can ensure no collisions i.e., no two inputs can ever be mapped to the same output. Data structures such as dictionaries and hash map leverage hashing functions.
The authors state that a lot of recommendation systems try to mitigate collisions in embedding tables by choosing hash functions that ensure low collisions. They argue that this is still detrimental to the machine learning model.
Ideally, if we use an embedding table, we’d like to use a hash function that ensures that no two inputs get mapped to the same position in the embedding table. The authors use the Cuckoo HashMap for this purpose.
Cuckoo HashMap
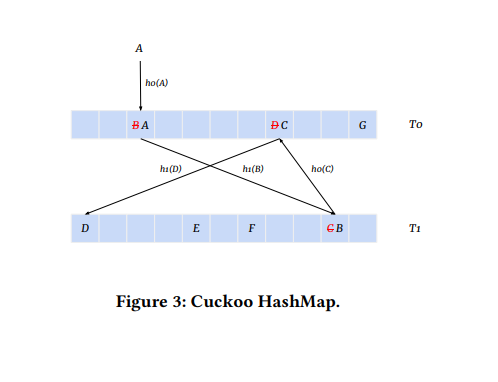
As shown in the figure a Cuckoo HashMap has two Hash Tables T0 and T1. Each Hash Table has its unique hash function, T0 uses h0 and T1 uses h1. The hash functions decide where a given input is stored in the embedding table.
An illustration of the working of the Cuckoo HashMap and how it handles collisions is shown in the figure above.
- As item A comes in, it is hashed by h0 (written as h0(A)) to a position in T0, but that location already has item B in it (this is a collision). What happens in this scenario is A is moved to the location, and B is evicted.
- On being evicted B is moved to T1 by computing h1(B) however, there’s another collision.
- Now C is evicted, and h0(C) is computed, collides with D.
- h1(D) is computed. Finally, h1(D) corresponds to a location in T1 that is empty.
Observe how the algorithm ensured that no two items occupy the same location in the hash table by relocating all items that have a collision with the incoming item.
Filtering and Evicting Categories
To limit the size of the embedding layers/tables, the authors recognize that certain categories/IDs occur very rarely. Having a unique embedding for such items isn’t very useful because the model would be underfitted on that category because of how infrequently it is observed in training.
Another astute observation the authors point out is that certain IDs/categories may become inactive after a certain period and having parameters for them no longer makes any sense. This could be a user not logging in for a year, a product on amazon not being bought in the past 3 months, etc.
Based on these observations, the authors filter out categories/IDs based on how frequently they occur and if they are inactive for longer than a certain period. This ensures that only the most relevant categories/IDs are present in the embedding tables.
Problem 2: Concept Drift
A machine learning model is trained on data collected from the past. However, there is no guarantee that the past can accurately represent the future. We’ve all witnessed trends rise to prominence and fade away with time. Our preferences change over time too.
In the world of data science, this phenomenon is referred to as Concept Drift. Where the data distribution that the model learns about is no longer accurate, and the interactions between features aren’t the same. Concept Drift is the main reason why machine learning models need to be periodically retrained to ensure that their performance doesn’t take a nosedive and that they learn about emerging concepts.
Solution
Online training is the process of training a model as soon as a new data point comes into existence. For example, if you’ve decided to start watching a new show on Netflix, the moment you’ve hit that play button a new training point with a positive label (since you clicked) has been created. The model can now run a forward pass to compute a loss and update its weights accordingly.
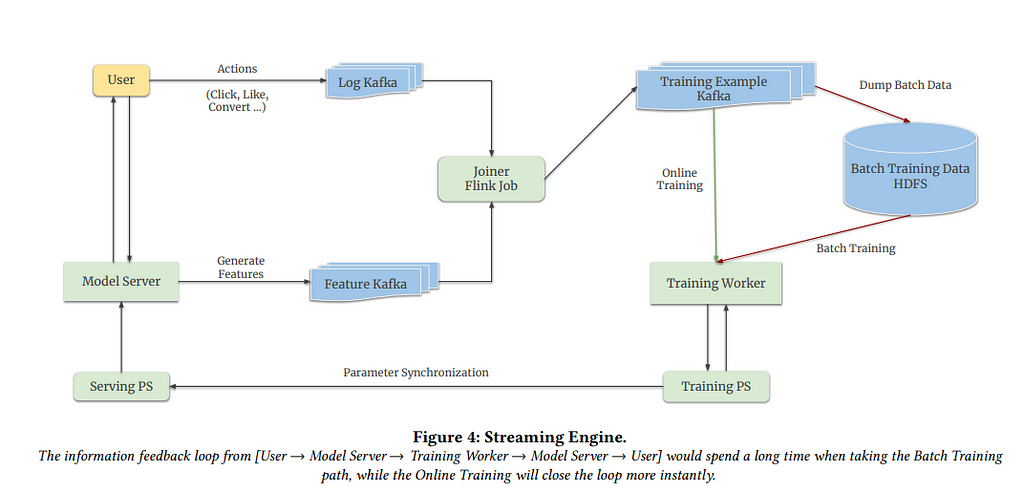
In the paper, the authors create a framework that can run batch (offline training) in tandem with online training. However, the concern here is that the model being trained (Training Worker and Training Parameter Server (PS) as seen in the figure) and the model actively being used (Serving Parameter Server (PS)) to provide recommendations are different and could be running in different clusters.
This is because running a model in train mode is slower than running it in inference mode because gradients don’t need to be computed in the latter. This leads us to the question of how the weights of the Training and Serving PS can be synchronized (made to be the same).
Per our understanding, the authors provide the following key insights that offer a solution to the problem:
- Most of the parameters of recommendation models are largely sparse features, i.e., categorical features and their corresponding embeddings.
- Only a few sparse features tend to get updated in a given window of time. Imagine a social media platform such as Tiktok at any given small window of time, only a fraction of the users might be logged in to the app despite the total number of daily active users being a few million.
- Models that use momentum-based optimizers to update their weights tend to take a long time for their weights to change significantly. The weights that belong to the Deep Neural Network exclusive from the embeddings are referred to as dense parameters.
Based on the first two observations, the authors develop a methodology to keep track of which sparse features have been updated during training (online and offline). Only the parameters of the IDs/features that have been updated during training are sent to the Serving PS to update its parameters. This is indicated via the arrow from the Training PS to the Serving PS in the image.
The authors update the sparse parameters every minute. This is feasible owing to the small fraction of IDs that are updated during online training. On the other hand, the dense parameters are updated at a much lower frequency. Despite the differing versions of the embeddings and dense parameters in the Serving PS, the authors highlight that there isn’t any significant drop in performance.
A combination of online and batch training with a clever plan for updating model weights allows the recommendation engine to learn about the changing preferences of users.
Problem 3: Fault Tolerance
For a system to be fault tolerant, it needs to be able to function as desired even in the event of a failure. Notice how rare it is for popular software applications to stop working completely this is because engineers make it a point to add in as much resistance to failure as possible.
A common method of achieving fault tolerance is by creating copies of servers, databases, etc. Remember that at the end of the day, a server is just a computer. It can get damaged, corrupted, and malfunction at any point, just as your own devices do. Having multiple machines running and storing the same set of information and data ensures that as soon as a machine fails, the copy can take over and serve any requests directed to it.
The authors follow the same approach to make their recommendation engine robust to failure. They create copies of the model’s weights (referred to as snapshots). However, there are a few intricacies that need to be highlighted.
- Models can be extremely large, and creating too many copies of them can be expensive since you need to pay for all the memory being consumed.
- Need to find the right balance between creating a copy and having up-to-date weights. If a copy is old, it means that it is unaware of all the ways the preferences of users have changed since the copy was created.
In their experiments, the authors find that making daily copies of their model worked well without any significant drop in model performance despite any failures of the servers or data centers that store the model.
Conclusion
Monolith teaches us how to achieve collisionless embeddings and the advantages of purging unused features/IDs. It shows us how models can deal better with concept drift by leveraging online training and clever parameter synchronization techniques. It also shows us the importance of finding the right balance in creating copies of model parameters to ensure fault tolerance.
Thanks for reading this article we hope that you’ve learned something new! If you have any questions or thoughts, please share them in the comments section below.
References
Paper Review Monolith: Towards Better Recommendation Systems was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")