



Overcoming Catastrophic Forgetting: A Simple Guide to Elastic Weight Consolidation
Last Updated on May 29, 2023 by Editorial Team
Author(s): Yunzhe Wang
Originally published on Towards AI.
The Problem of Catastrophic Forgetting
In the field of artificial intelligence, deep learning models, especially neural networks, have shown great success in a wide range of applications. However, one major challenge these models face is the phenomenon of Catastrophic Forgetting. Catastrophic forgetting occurs when a neural network learns new tasks and, in the process, forgets previously learned tasks. This limitation hinders the development of lifelong learning systems or networks that require constant adaptation to new environments and tasks.
To counter Catastrophic forgetting, several methods have been proposed:
- Elastic Weight Consolidation (EWC): A regularization technique that adds a penalty term to the loss function based on the Fisher information matrix, constraining the learning process to retain the knowledge of previous tasks.
- Progressive Neural Networks (PNN): An architecture that trains separate columns of neural networks for each task, with lateral connections to transfer previously learned knowledge to the new task without altering the previous networks.
- Learning without Forgetting (LwF): A method that incorporates knowledge distillation to train the network on new tasks while preserving the output probabilities of the previous tasks, thus maintaining old knowledge.
- Continual Learning with Memory Replay (CLMR): A technique that maintains a memory buffer of previously learned examples, which are periodically replayed along with new data to prevent forgetting.
- Sparse Coding: A representation learning method that enforces sparsity in the activations of the network, leading to more distinct and non-overlapping representations for different tasks, thereby reducing interference.
- Meta-Continual Learning: An approach that leverages meta-learning algorithms, such as MAML, to learn a model-agnostic initialization that can quickly adapt to new tasks with minimal interference to previously learned tasks.
- Synaptic Intelligence (SI): A regularization method that accumulates the importance of each weight over time during learning and uses this information to constrain weight updates, preserving the knowledge of previous tasks.
This tutorial explains Elastic Weight Consolidation, including its fundamental principles and how to apply it in PyTorch, a widely used deep learning framework. We'll also cover optimization techniques and examine several scenarios where EWC can be advantageous. With the knowledge gained from this tutorial, you'll be able to integrate EWC into your own projects and address the issue of catastrophic forgetting.
Elastic Weight Consolidation
Elastic Weight Consolidation (EWC) is a regularization technique that mitigates catastrophic forgetting by constraining the learning process in neural networks. The key idea behind EWC is to add a quadratic penalty term to the standard loss function. This penalty term considers the distance between the current weight values and the optimal weights obtained during the previous task learning. By doing this, EWC reduces the interference between tasks and helps maintain a balance between learning new tasks and retaining old ones.
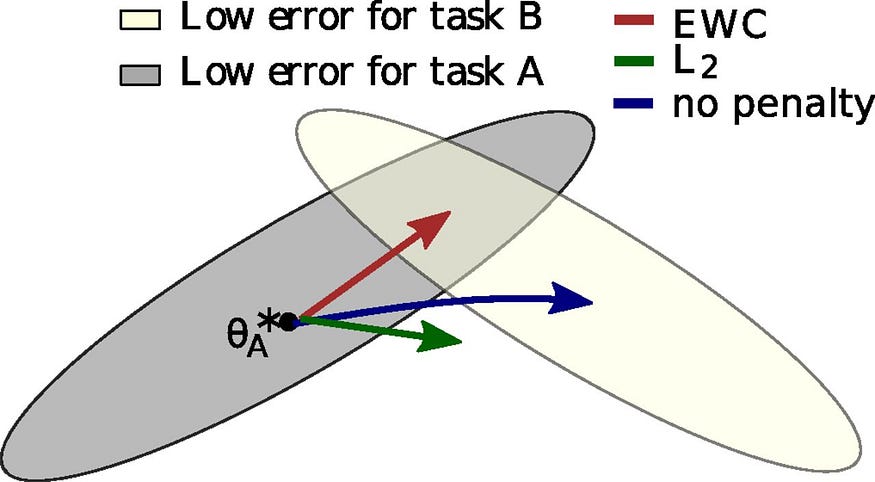
EWC facilitates retaining knowledge of task A while training on task B. The training process is depicted in a conceptual parameter space, where parameter regions resulting in a good performance on task A are represented in gray, and those for task B in cream color. After learning task A, the parameters are located at θ∗A.
If we only consider task B’s gradient steps (blue arrow), we minimize task B’s loss but compromise the knowledge acquired from task A. This corresponds to “no penalty” in the figure.
Conversely, if we constrain all weights uniformly (green arrow), the learning process corresponds to “l2” in the figure.
It turns out that the l2 constraint is so strong that it could hamper the learning process of task B. In neural networks, we often over-parametrize the models. There might be some parameters that are less useful and others are more valuable.
EWC discovers a solution for task B without significantly impairing task A’s performance (red arrow) by explicitly calculating the importance of each weight for task A. This importance value, called the Fisher information matrix, quantifies the weight’s contribution to the performance on previously learned tasks. The Fisher information matrix provides an approximation of the curvature of the loss function, giving us insight into how sensitive the network is to changes in the weights. Weights with higher importance values have a greater impact on the performance of the previous tasks, and thus, their updates should be constrained more during the learning of new tasks.
The EWC learning process can be formulated as follows:
Where:
- I_i is the Fisher information matrix diagonal, representing the importance of each weight i
- λ is a scalar hyperparameter that controls the strength of the EWC penalty
When training the network on a new task, the EWC loss function combines the loss for the new task with the penalty term that restricts the updates on weights according to their importance values. This ensures that the learning process remains biased towards retaining previously learned knowledge while still adapting to the new task.
Fisher Information Matrix (FIM)
The Fisher information matrix is calculated based on the second-order derivatives of the log-likelihood of the data given the model parameters.
EWC calculates the diagonal elements of the approximate Fisher Information Matrix. This series of approximations results in the diagonal being estimated as the squared gradients averaged across mini-batches during a single pass through the training dataset.
To calculate the Fisher diagonal I for each weight i, follow these steps:
- Train the model on the current task and obtain the optimal weights (θ^*_i) for that task.
- Compute the gradients of the loss function with respect to each weight: ∇_θ_i L(θ)
- Estimate the Fisher diagonal I_i for each weight as the squared expectation of the gradients: I_i = E[(∇_θ_i L(θ))²]
PyTorch Implementation of EWC Loss
Assuming we have a neural network model trained on task A using dataset A, we now train it on task B. Below is a code snippet to obtain the EWC loss with empirical fisher.
def get_fisher_diag(model, dataset, params, empirical=True):
fisher = {}
for n, p in deepcopy(params).items():
p.data.zero_()
fisher[n] = Variable(p.data)
model.eval()
for input, gt_label in dataset:
model.zero_grad()
output = model(input).view(1, -1)
if empirical:
label = gt_label
else:
label = output.max(1)[1].view(-1)
negloglikelihood = F.nll_loss(F.log_softmax(output, dim=1), label)
negloglikelihood.backward()
for n, p in model.named_parameters():
fisher[n].data += p.grad.data ** 2 / len(dataset)
fisher = {n: p for n, p in fisher.items()}
return fisher
def get_ewc_loss(model, fisher, p_old):
loss = 0
for n, p in model.named_parameters():
_loss = fisher[n] * (p - p_old[n]) ** 2
loss += _loss.sum()
return loss
model = model_trained_on_task_A
dataset = a_small_sample_from_dataset_A
params = {n: p for n, p in model.named_parameters() if p.requires_grad}
p_old = {}
for n, p in deepcopy(params).items():
p_old[n] = Variable(p.data)
fisher_matrix = get_fisher_diag(model, dataset, params)
ewc_loss = get_ewc_loss(model, fisher_matrix, p_old)Some Comments:
- The dataset used for computing FIM can be a small sample from task1
- When computing the NLL loss, we can either use the ground truth label or the predicted label. Both give the fisher information. When using the ground truth, we are computing the empirical Fisher.
- In the training loop for task B, one simply uses:
loss = task2_loss + lambda * ewc_loss_task_A
Applications and Use Cases
Elastic Weight Consolidation (EWC) has a wide range of applications across various domains, particularly in scenarios where neural networks need to learn and adapt to new tasks or environments without forgetting previously acquired knowledge.
- Embodied Intelligence: In the field of Embodied Intelligence, such as Robotics, autonomous vehicles, and video game AI, EWC can be employed to make EI learn and adapt to new tasks in real-time.
- Personalized recommendation systems: In the context of recommendation systems, EWC can help create models that continually learn and adapt to users’ preferences and behaviors over time.
- Healthcare and medical diagnosis: EWC can be utilized in healthcare applications, such as medical image analysis or patient monitoring, where models need to continually adapt to new patient data without losing knowledge from previous cases.
- Natural language processing: In natural language processing tasks, such as sentiment analysis or machine translation, EWC can be employed to develop models that continually learn and adapt to new domains or languages without forgetting the knowledge acquired from previous tasks.
These are just a few examples of the numerous applications and use cases where EWC can be beneficial. By incorporating EWC into your projects, you can create neural networks that effectively learn and adapt to new tasks or environments while retaining knowledge from previous experiences, ultimately leading to more versatile and robust AI systems.
Suggested Materials
- A continual learning survey: Defying forgetting in classification tasks (Matthias Lange)
- Overcoming catastrophic forgetting in neural networks (James Kirkpatrick)
- Fisher Information Matrix (Yuan-Hong Liao)
- EWC PyTorch Implementation by moskomule
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")