



Neural Entity Linking in JPMorgan Chase
Last Updated on August 2, 2022 by Editorial Team
Author(s): Harshit Sharma
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Neural Entity Linking at JPMorgan Chase
JPMC published a paper in 2021 highlighting their approach to Entity Linking. This article summarizes the problem statement, solution, and other key technical components of the paper
What is Entity Linking?
It's the task of assigning a unique identity to ambiguous mentions of named entities in a text.
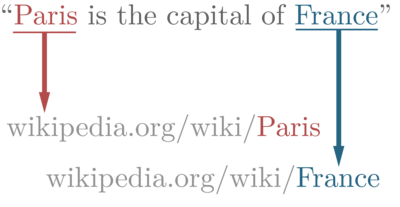
Here, “Paris” from the text is given a unique identity via a URL (the most common type of URI) “wikipedia.org/wiki/Paris”. Note that the type of URI used to identify the mentioned entity depends on the domain uniquely. For eg, Instead of a web address, we could have used ISBNs if we were to identify books from a text.

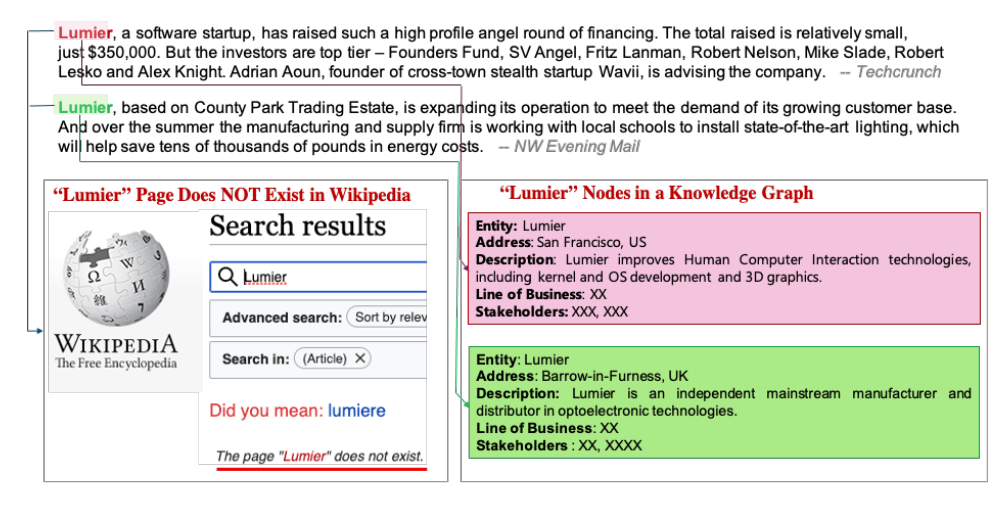
JPMC was interested in :
Mapping mentions of financial institutions from news articles to the entities stored in their internal knowledge base (stored as a Knowledge Graph)
An example is shown below:
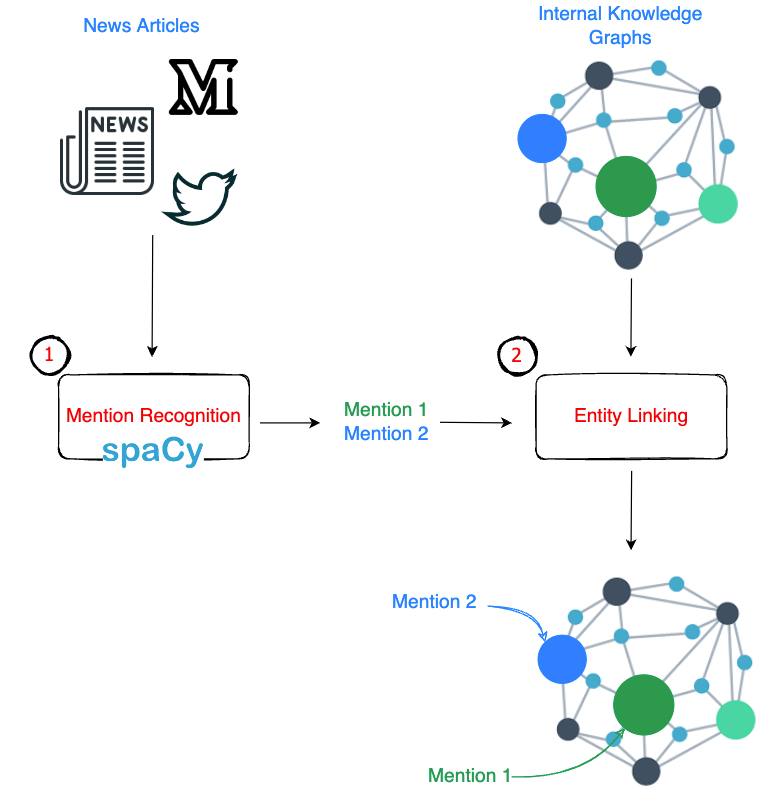
There are two sub-problems that must be defined:
- Recognition:
Extraction of mentions from financial news articles. JPMC has used Spacy for this. - Linking:
Choosing the correct entity from the internal Knowledge Graph to be linked to the extracted mentions in the previous step. The paper discusses this step.
A pictorial representation of this is shown below:

- String Matching
These approaches capture the “morphological” structure of the entity names. The team experimented with
(a) Jaccard
(b) Levenshtein
(c) Ratcliff-Obershelp (also known as Gestalt-Pattern-Matching)
(d) Jaro Winkler
(e) N-Gram Cosine Similarity
The con of these approaches is that they focus just on the “syntactics” of the names and not the semantics. An example of a failure case would be the matching of “Lumier” and “Lumier”. Even though they are exactly the same, they refer to two different entities.
2. Context Similarity Methods
These methods take the contexts around mentions and entities to give a similarity score.
The Context for “mention” is text to the left and right of the mention, whereas
the Context for “entity” is all the data that's stored in the KG for this entity.
Finally, Cosine similarity / Jaccard similarity can be used on top of the context vectors.
3. ML Classification
Naive Bayes, Logistic Regression, and SVM are trained on (mention, entity) pairs to find the ones that should be linked
4. Learn to Rank Methods (LTR)
These models work in tandem with ML approaches, which might give us multiple (mention, entity) pairs as the solutions. LTR approaches just narrow down to the most probable solution.

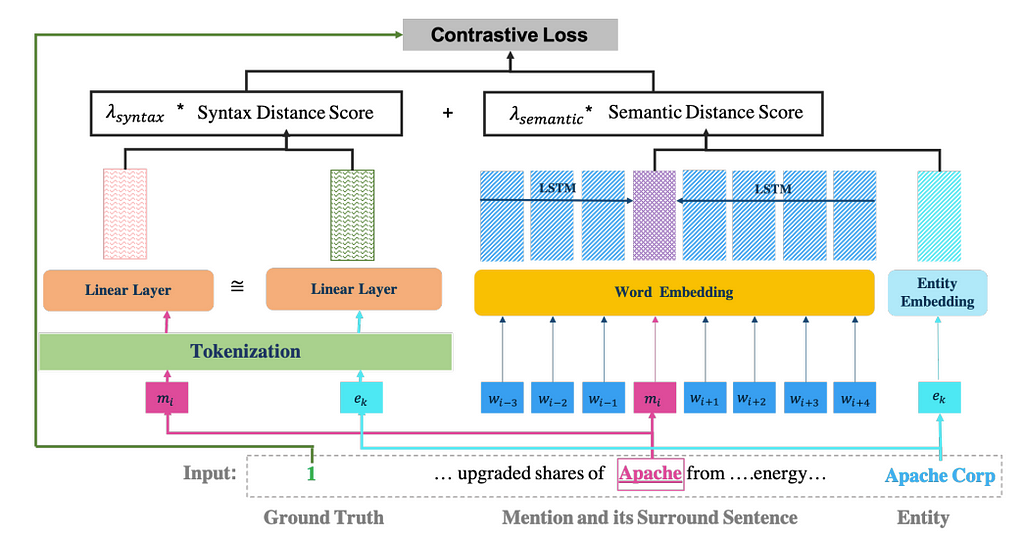
The idea is to capture both Semantic distance(the meaning that the mention or entity stands for) and Syntactic distance (character composition of the name) between the names and use a contrastive loss function to train a model.

We will see below how both of these distances are calculated step by step.
Step 1: Obtain embeddings for Entities and Mentions
To come up with both of the distances, the authors have proposed to use embeddings for mentions as well as entities in the KG.
To obtain Entity embeddings, the authors have used a Triplet Loss function (shown below)
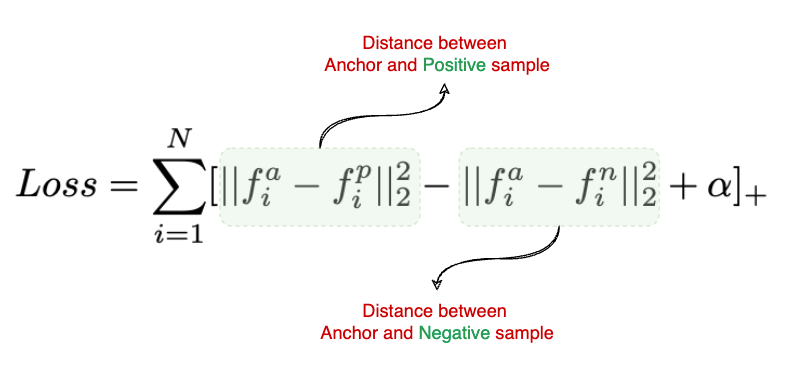
For each entity, they used 10 positive and 10 negative samples, making 10 <entity, positive word, negative word> triplets.
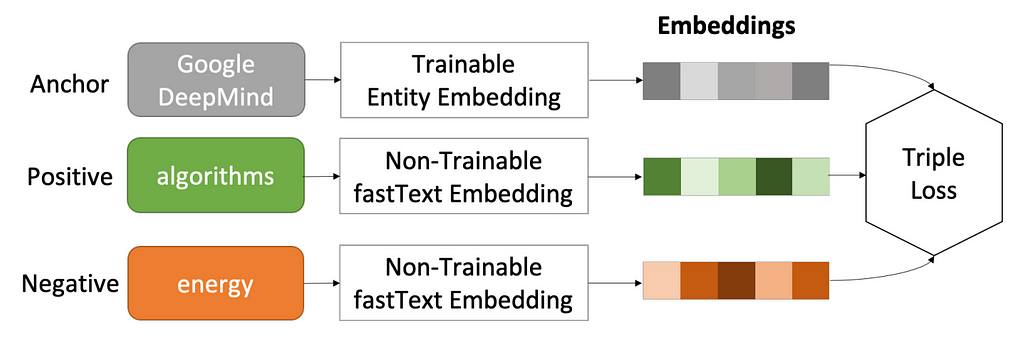
Unlike Entity embeddings, which they had precomputed, the mention embeddings were trained using the on-the-go embeddings approach, where the embedding matrix is learned during the training itself.
Step 2: Calculate Syntactic Distance score
Before going further, it's worth mentioning “Wide & Deep” architecture which was introduced by Google in 2016. You can find their official blog here. We won’t go into the details, but to give a summary, it's an architecture that has two components — The Wide component and the Deep component.
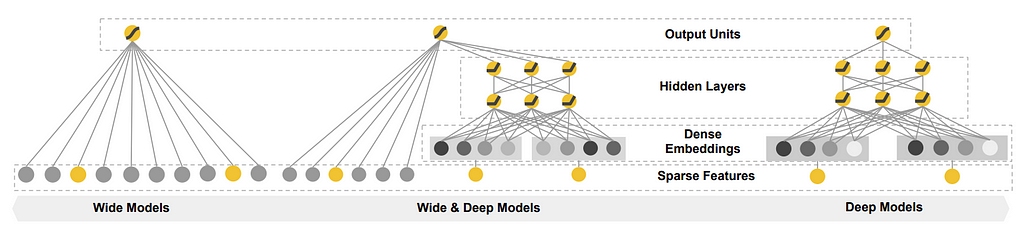
Syntactic Distance score calculation is done using the WIDE part, which consists of a Linear Siamese Network.
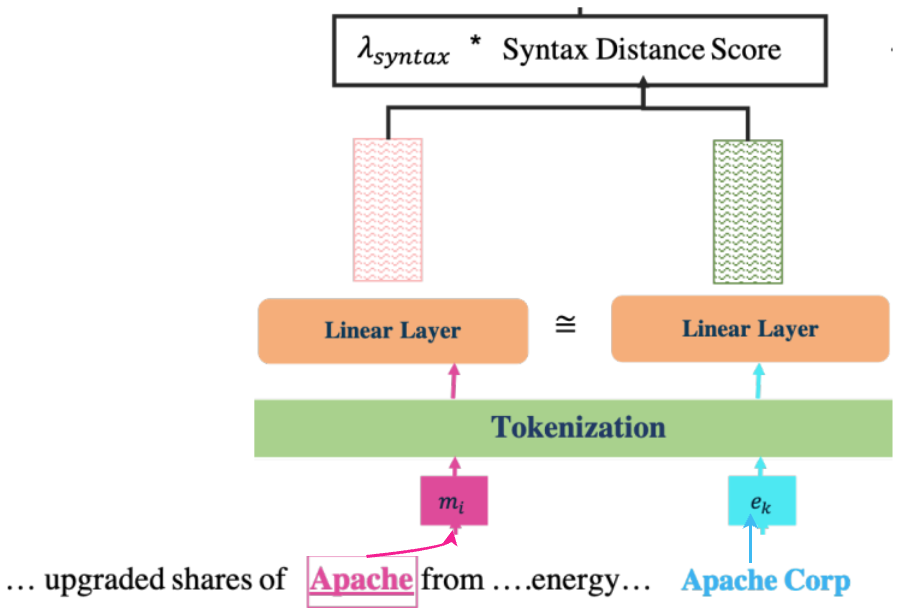
The output of the siamese network is the vectors for both the entity and the mention, which are then compared to find the Euclidean distance.
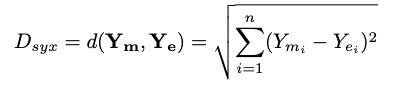
Step 3: Calculate Semantic Distance score
Semantic Distance score calculation is done using the DEEP part
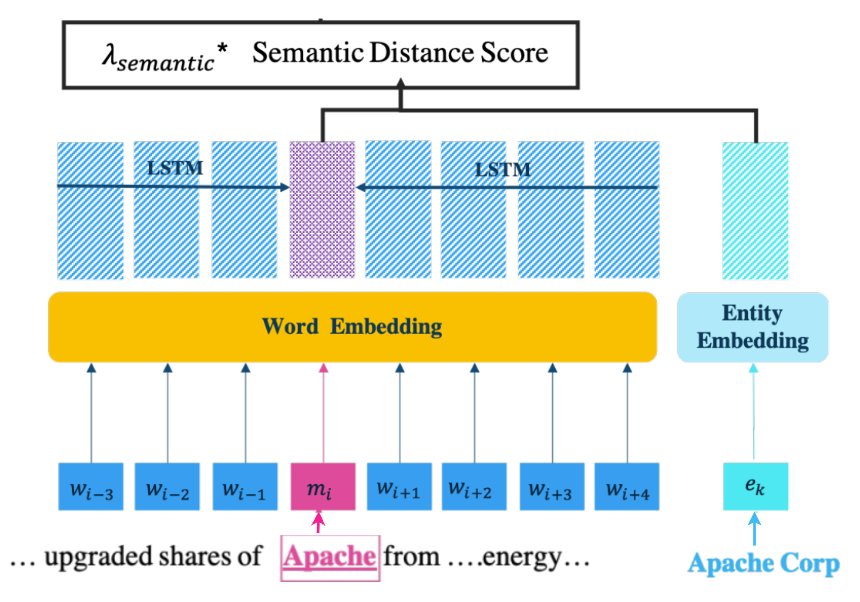
eₖ is the pre-trained embedding for the “Apache Corp” that was calculated in Step 1. To obtain the embedding for the mention, its left and right context words are fed into a Bi-LSTM network that trains the embeddings. The embedding vectors of mention (Vₘ) and the entity (Vₑ) are then used to find the Euclidean distance:
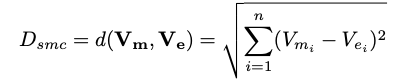
Step 4: Compute Contrastive Loss
Both Syntactic and Semantic distances are combined in a weighted fashion as follows:
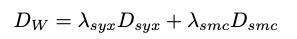
The contrastive loss function is then combined as follows:
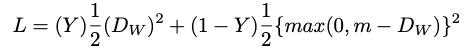
where Y is the ground truth value, where a value of 1 indicates that mention m and entity e are matched, 0 otherwise.
Combining all the pieces, the final model framework is shown below:

At the time of writing this paper, JPMC was still in the process of deploying the model, which, once done, will help support users across JPMC in discovering relevant and curated news that matters to their business.
From the cost perspective, not all the mentions are fed through the JEL framework as that would be computationally expensive. JPMC has put another blocking layer to funnel out the mentions that share less than 2 bigrams with the entities from their internal KGs.
Once again, here is the paper link if you would like to read the full paper.
Follow Intuitive Shorts (my Substack newsletter), to read quick and intuitive summaries of ML/NLP/DS concepts.
Neural Entity Linking in JPMorgan Chase was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

