


Let’s Do: Time Series Decomposition
Last Updated on June 28, 2023 by Editorial Team
Author(s): Bradley Stephen Shaw
Originally published on Towards AI.
What makes your time series tick? There’s only one way to find out — by taking it apart.
Time series are quite possibly the most ubiquitous collections of data available today. In fact, you’ve probably observed many yourself without even knowing — doing your grocery shopping, watching a sports match, and even just walking around.
Put simply, a time series is a series of data points that are indexed, listed, or graphed in time order¹.
Time series approaches generally fall into two buckets: extracting meaningful information from past data (time series analysis) and modeling past data in order to predict future values (time series forecasting). In this article, we’ll be focussing on the former, exploring:
- Model form
- Location and trend
- Seasonality
- Residual and noise
- A useful example
First up, some theory.
The building blocks of a time series
It’s useful to consider a generic time series as some combination of underlying drivers: location and trend, seasonality, and residual.
Location and trend
Often bundled together into a single “trend” term, location specifies the starting point of the series, and trend relates to long-term changes over time.
Usually, we think of trends as being movements in time series unrelated to regular seasonal effects and random shocks.
Seasonality
Seasonal effects are regular, systematic variations in the time series.
The drivers of these effects vary depending on the context of the analysis but are commonly related to calendar dates or physical conditions — e.g., summer holidays or the frequency at which a traffic light turns red.
Residual
Sometimes called noise, the residual is the catch-all bucket containing variation which is unrelated to long-term and/or predictable changes — i.e., this component is whatever remains after trend and seasonality have been removed from the time series.
As an example, a volcano eruption or a large sports event could cause shocks in a time series of airline passengers; all of this would get bundled into the residual.
Now that we’ve got a basic understanding of the elements of a time series let’s put them together in a model.
Model form
We can combine trend, seasonality, and residual into a decomposition model. These models are usually additive or multiplicative depending on the characteristics of the time series in question. Mathematically, this becomes:
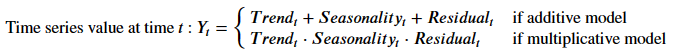
The determining factor of the decomposition model type is whether the amplitude of the seasonal and residual elements change as the trend changes²: if the size of the seasonal and residual elements are consistent regardless of the trend, then an additive model is most appropriate.
Enough theory for now — let’s see a practical example of decomposition!
The classic example
This set of airline data³ is commonly used in demonstrations of time series analysis, and for a good reason: it demonstrates the key components of a time series extremely well.
After some manipulation, we have monthly counts of airline passengers dating back to 1949:

Plotting this data, we see the following:

- A clear and consistent upward trend over time.
- Strong seasonality, becoming more evident over time. The seasonality element becomes more pronounced as the trend increases.
- Some evidence of a residual, as we can see what looks like random variation in the series.
As we’ve seen the magnitude of the seasonality element move in line with the magnitude of the trend element, we can be fairly certain that a multiplicative model is appropriate here.
Let’s go ahead and decompose the time series using the seasonal_decompose function in Python’s statsmodels ⁴. This decomposition first determines trend, and then calculates seasonality. The difference between the time series and the derived trend and seasonality falls into the residual.
This is a “naive” decomposition approach as it relies on the use of moving averages to calculate trend — more on that below.
Code-wise, the decomposition is quite simple:
# decompose
result = seasonal_decompose(
df['passengers'].values,
model = 'multiplicative',
period = 12,
extrapolate_trend = 6
)
# get each element
trend = pd.Series(result.trend)
season = pd.Series(result.seasonal)
res = pd.Series(result.resid)
Let’s take a look at the parameters used:
modelspecifies the decomposition model type. In this case, we’ve explicitly stated that we’re using the multiplicative model.periodspecifies the period after which the seasonal behavior of the time series can be expected to repeat. Since we’re using monthly data, we would expect the seasonal element to repeat itself every 1 year, or 12 months. If we were using daily data, we would setperiodto be 7, reflecting the number of days in a week.extrapolate_trendrelates to the moving average used to derive the trend. The default approach is to calculate a “two-sided” moving average which reflects theperiodprovided, and returnNanfor points for which the moving average cannot be calculated.seasonal_decomposeprovides the option to replace theNanwith extrapolated values using the nearestextrapolate_trendpoints. So in our case, the two-sided moving average returnsNanfor the first and last 6 points (sinceperiod = 12); we use the nearest 6 points to create an extrapolation to replace these missing values.
Let’s plot each component of the decomposition and remove each from the series in turn:

The trend component is clearly upward and consistent over time. No surprises here, as we saw in the Raw series. Note how regular the start and finish of the trend are — this is caused by the extrapolation we covered above.
Once we remove the trend from the series — or “detrend” it — we see a mostly-regular pattern (top right above). Note how the de-trended series appears most consistent from about 1954 to 1958, with data points on either side of that interval appearing fairly noisy.
Seasonality is shown in the middle left chart above. Since seasonality is calculated such that it is a consistent pattern across the entire time series, we show only one period of the seasonal effects. Notice how seasonality peaks around the July and August summer holidays and drops around the start of the academic year in September and October — fairly sensible and in line with expectations.
Removing both trend and seasonality from the series leaves just the residual — we see this as the middle right and bottom left charts are the same. We can see how there is a noticeable change in the amplitude if the residual from 1954 to 1958, coinciding with changes in the raw series.
Finally, removing the residual from the de-trended, de-seasonalised series delivers a constant series of value 1.
Pro tip #1: under the multiplicative model, we remove an element of the time series by dividing the (raw) series by the element in question. As an example, if we were to remove seasonality from the equation, we would divide the raw series by the seasonality values. Under the additive model, we would subtract the component rather than divide by it.
Pro tip #2: under the multiplicative model, removing all of the constituent parts of a time series leaves a constant series of 1. If we were using an additive model, this “remainder” would be 0. This is a good check to ensure that all the elements of the time series have been captured appropriately.
Practical applications
Now that we’re familiar with decomposition, let’s take a look at how we can use it in our analysis.
Removing seasonality highlights trends and unexpected events
High levels of seasonality can mask trends and events, especially if the event takes place during a period of strong seasonality.
For example, consider the number of daily walkers in a park; during the colder winter months, we would expect a drop in these numbers — no big deal. But what if a short cold snap kept even more people away? Would it be easy to see that in a series without seasonality removed? Probably not!

If we remove the derived seasonality from the airline data, we get the chart above (orange for de-seasoned data, grey for original series). Note how a downward spike around March 1960 appears to be masked, and only becomes noticeable once we strip out seasonality.
Removing noise creates a more regular time series.
By definition, the residual component is noisy and contains unexpected events and changes. It’s quite often useful to ask “what if?” questions, like “what if that random thing didn’t happen?”. We can get to a quick answer by simply removing the residual from a time series.

Consider the airline series above. The original series is plotted in grey, and the denoised series is in red. Notice how removing random events creates a more regular time series that’s better suited to analysis and forecasting.
Recap and ramble
The recap
We covered the constituent components of a time series, and how we can put them together. We discussed how long-term changes in a time series are captured as trend, how the seasonality component represents regular and periodic variation, and how random fluctuations and shocks are captured in the residual component.
We also saw how we could formulate an additive and multiplicative time series model, the choice of which to use depending on how the amplitude of the seasonality and residual interacts with the trend.
We used statsmodels decompose an example time series and explore the various components and their effects on the original time series. Lastly, we discussed some practical use cases: the motivation for removing seasonality and for removing residual from the time series.
The ramble
Implicit in this analysis is the use of a univariate time series — i.e., we concentrated on measurements of a single quantity over time. Things don’t tend to operate in isolation in the real world, so it may make sense to analyze multiple time series in conjunction. Luckily for us, multivariate time series is a well-formed branch of statistics!
I mentioned that the time series decomposition approach we used was “naive”; naive in the sense that the decomposition relies on moving averages. While moving averages are great (and simple) tools, they can be sensitive to the choice of window size. There are other decomposition approaches available — like the STL⁶ — which may provide a more nuanced and robust result.
Finally, we need to talk about change points: depending on the size and treatment of the change, the decomposition can be distorted. COVID is a great example where not accounting for the effect of lockdown periods properly can create a distorted seasonality result, which in turn can distort conclusions drawn from an analysis.
That’s it from me — I hope you’ve enjoyed reading as much as I’ve enjoyed writing. Keep an eye out for more articles as I delve into time series analysis and forecasting.
References and resources
- Time series — Wikipedia
- Time Series Analysis: The Basics (abs.gov.au)
- yao, wei (2016), “international-airline-passengers”, Mendeley Data, V1, doi: 10.17632/vcwrx2rwtg.1, downloaded and used under the CC BY 4.0 license.
- statsmodels 0.14.0
- statsmodels.tsa.seasonal.seasonal_decompose — statsmodels 0.15.0 (+8)
- 6.6 STL decomposition U+007C Forecasting: Principles and Practice (2nd ed) (otexts.com)
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

