



LangChain 101: Part 3a. Talking to Documents: Load, Split, and simple RAG with LCEL
Last Updated on February 5, 2024 by Editorial Team
Author(s): Ivan Reznikov
Originally published on Towards AI.
After ChatGPT went viral, one of the first services and applications created was “Use ChatGPT for your documents.” It makes a lot of sense, as allowing users to chat with their data may be a pivotal point of using Generative AI in general and Langchain in particular.
This is Part 3 of the Langchain 101 series, where we’ll discuss how to load data, split it, store data, and even how websites will look in the future. We’ll also talk about vectorstores, and when you should and should not use them. As usual, all code is provided and duplicated in Github and Google Colab.
· About Part 3 and the Course
· Document Loaders
· Document Splitting
· Basics of RAG pipelines
· Time to code
About Part 3 and the Course
This is Part 3 of the LangChain 101 course. It is strongly recommended that you check the first two parts to understand the context of this article better.
LangChain 101 Course (updated)
LangChain 101 course sessions. All code is on GitHub. LLMs, Chatbots
medium.com
In Part 3a, we’ll discuss Document Loading and Splitting and build a simple RAG pipeline.
LangChain Cheatsheet — All Secrets on a Single Page
The onepager summarizes the basics of LangChain. LangChain cheatsheet includes llms, prompts, memory, indexes, agents…
pub.towardsai.net
Document Loaders
To work with a document, first, you need to load the document, and LangChain Document Loaders play a key role here. Here is a short list of the possibilities built-in loaders allow:
- loading specific file types (JSON, CSV, pdf) or a folder path (DirectoryLoader) in general with selected file types
- use pre-existent integration with cloud providers (Azure, AWS, Google, etc.)
- connect to applications (Slack, Notion, Figma, Wikipedia, etc.).
- loading webpage content by URL and pandas dataframe on the fly
These loaders use standard document formats comprising content and associated metadata. There are currently 160+ loaders; most of the time, you only need a correct API key.
Using prebuild loaders is often more comfortable than writing your own. For example, the PyPDF loader processes PDFs, breaking down multi-page documents into individual, analyzable units, complete with content and essential metadata like source information and page number. On the other hand, YouTube content is handled through a chain involving a YouTube audio loader with an OpenAI Whisper parser that converts audio to text format.
Document Splitting
Ok, now imagine you’ve uploaded a document. Let it be a PDF file of 100 pages. There are two types of questions you can ask:
- document-related (how many chapters are there?)
- content-related (what is the symptom of …)
The first question can be asked based on the metadata. But to answer the second one, you don’t need to load the whole document to the LLM. It would be great if question-related chunks of text were loaded to the model only, right?
This is where document splitting comes in handy. This procedure is executed after the initial data loading into a document format before introducing it into the vectorstore. Though seemingly straightforward, the technique contains hidden challenges.
Character Text Splitter and Token Text Splitter are the simplest approaches: you split either by a specific character (\n) or by a number of tokens.
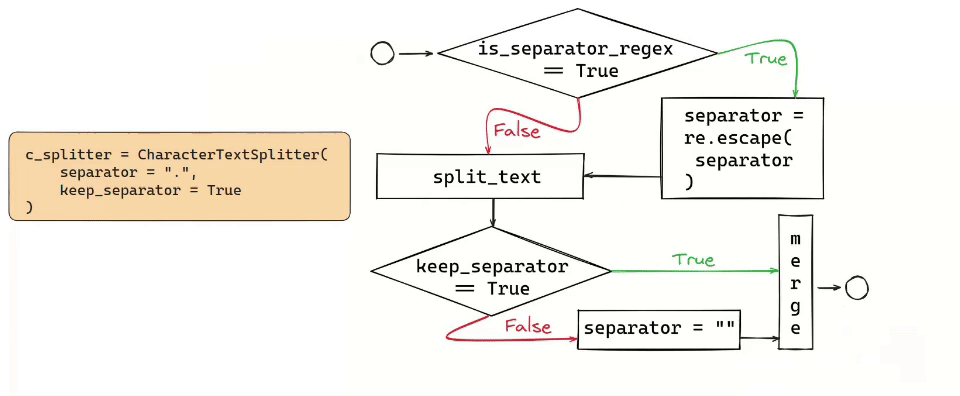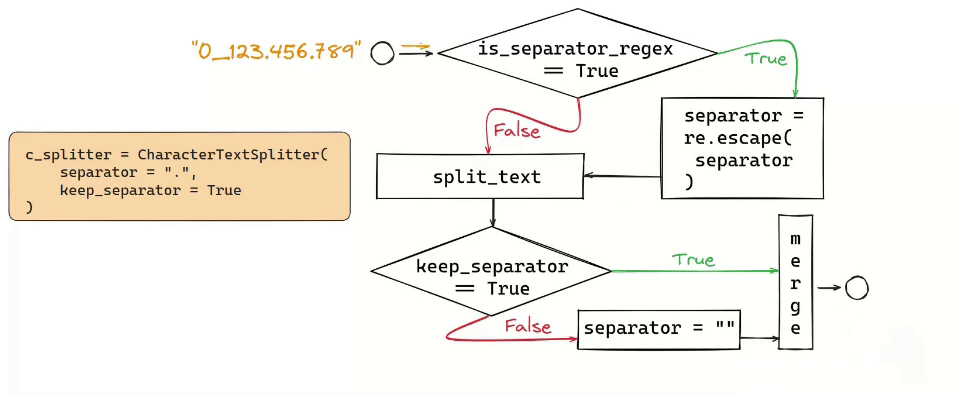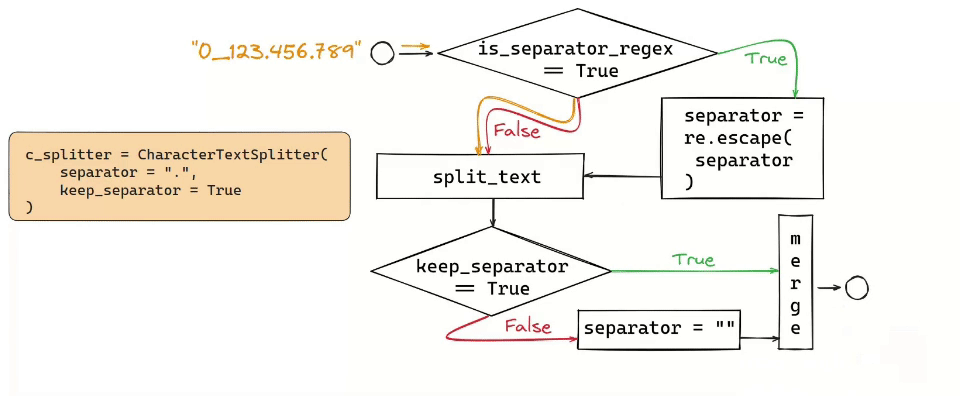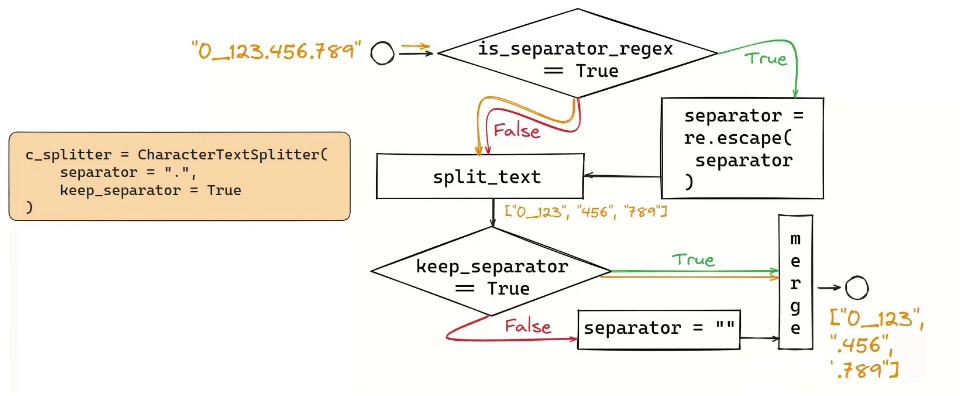
The Recursive Text Splitter, for instance, operates by recursively splitting text based on a list of user-defined characters, aiming to keep contextually related pieces of text together. This method is particularly effective for texts where maintaining the semantic relationship between segments is crucial. These come up with useful parsing HTML or Markdown files.
Such naive approaches might still lead to fragmented and incomplete information. In such cases, key details could be scattered across different chunks, hindering the retrieval of accurate and complete information. Therefore, the method of splitting needs to be tailored, ensuring that chunks are semantically close.
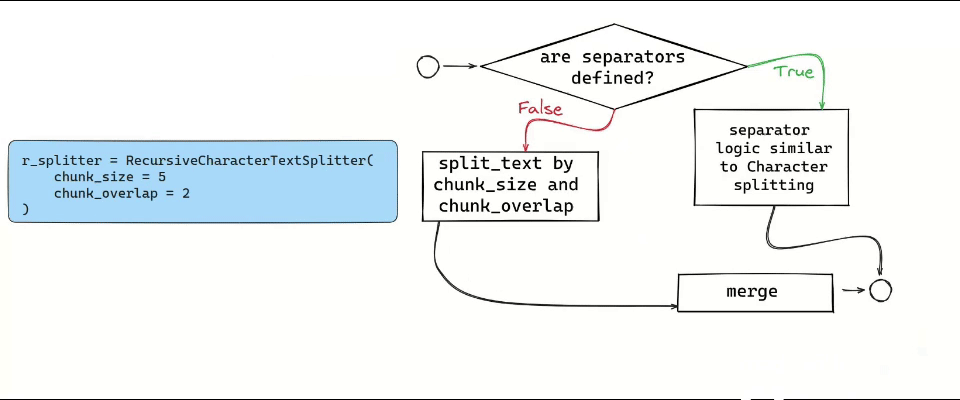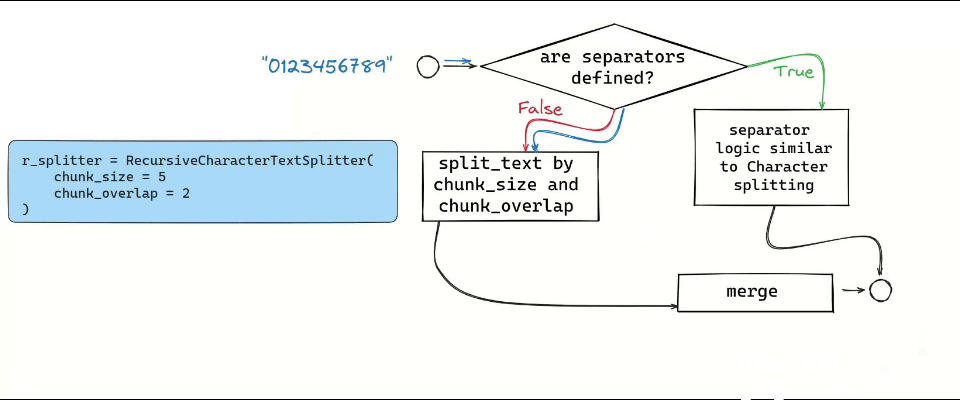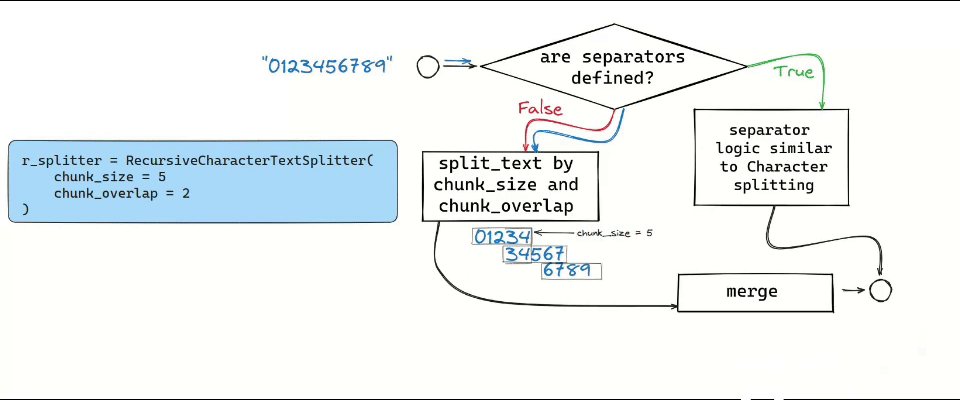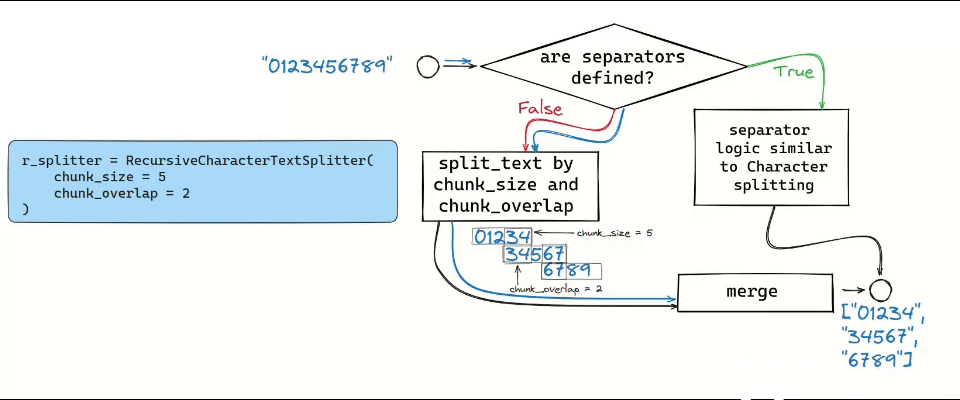
An interesting approach is predefining the chunk size while including a certain degree of overlap between chunks. Like a sliding window, this method ensures consistency by allowing shared context at the end of one chunk and the beginning of another. This is made possible using the chunk_overlap parameters in different splitters.
For coding languages, the Code Text Splitter is adept at handling a variety of languages, including Python and JavaScript, among others. It can distinguish and split text based on language-specific characters, a feature beneficial for processing source code in 15 different programming languages.
Last but not least, an experimental Semantic Chunker, which represents a novel approach to text splitting. It first segments text into sentences and then intelligently groups adjacent sentences if they are semantically similar. This method, conceptualized by Greg Kamradt, offers a sophisticated way to maintain the thematic continuity of the text, ensuring that semantically related sentences are grouped and enhancing the relevance and coherence of the resulting chunks.
The use of overlapping chunks and the ability to handle different types of content — from plain text to code — demonstrates the sophistication of the LangChain framework regarding working with documents. By choosing the correct approach, you can facilitate the effective segmentation of your text. LangChain ensures the preservation and appropriate distribution of metadata, paving the way for more accurate and efficient data analysis in subsequent stages.

To explore what is the right splitter, chunk_size, chunk_overlap, etc. visit the splitting visualizer ChunkViz v0.1 created by Greg Kamradt
Basics of RAG pipelines
So, what have we learned so far? We know how to upload a document and split it. We won’t go into details on what are embeddings, vectorstores and RAGs — these topics deserve their own parts. But we will build a simple pipeline to chat with our documents. Simply put, all that’s missing is a system that quickly finds corresponding chunks and feeds the LLM with them.
We’ll start with creating an index to facilitate easy retrieval of these segments. This is achieved by employing embeddings and vector stores. Embeddings convert text into numerical vectors, allowing for comparing text based on content similarity. These embeddings are put into a vector store. We’ll be using Chroma for its simplicity and in-memory operation.
However, this method has limitations. It sometimes retrieves duplicate or irrelevant information due to the nature of the data or the query’s complexity. Or suppose you’re aiming to find a text from a specific chapter/part, due to the focus on semantic similarity rather than structure. In that case, the retrieved information might be incorrect. We’ll look into such challenges in future parts.

The whole pipeline now looks as follows:
- Load a document
- Split the document
- Embed the splitted chunks
- Store the chunks
Such a pipeline is called indexing. We’ve prepared the data to be searched through and retrieved, pretty much like search engines do.
Now, we can retrieve relevant chunks based on user queries. This part is called Retrieval from the Retrieval-Augmented Generation (RAG). In a RAG system, retrieved data is then fed into a generative language model to generate an output.

As mentioned previously, we’ll cover embeddings, vectorstores, indexes, and RAG in future parts. Now, it’s time to code!
Time to code
In the article, I’ll showcase the code fragments partially.
The whole code can be found on Github and Colab.
First of all, let’s upload some files:
# Example of loading and using document loaders
def load_document_from_url(url: str, filename: str, loader_class: Any) -> Any:
"""Download a document from a URL, save it, and load it using a specified loader class.
Args:
url: URL of the document to download.
filename: Filename to save the downloaded document.
loader_class: The class of loader to use for loading the document.
Returns:
The loaded document.
"""
download_and_save_file(url, filename)
loader = loader_class(filename)
return loader.load()
# Load and process documents
text_document = load_document_from_url(text_url, "planets.txt", TextLoader)
csv_document = load_document_from_url(csv_url, "insurance.csv", CSVLoader)
pdf_document = load_document_from_url(pdf_url, "dubai_law.pdf", PyPDFLoader)
web_document = WebBaseLoader(web_url).load() # WebBaseLoader usage is direct as it doesn't involve downloading
youtube_loader = GenericLoader(YoutubeAudioLoader([youtube_url], "youtube"), OpenAIWhisperParser())
youtube_document = youtube_loader.load()
Now it’s time to split the documents:
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n"], chunk_size=250, chunk_overlap=0, keep_separator=False
)
# split_text
chunks = text_splitter.split_text(text_document[0].page_content)
#split_documents
chunks = text_splitter.split_documents(text_document)
As the documents are split (or not, you might use the document split by page by default), we can push it to our RAG pipeline. In the collab, there are basic pipelines, but for demonstration, I’ll show how sourcing works:
def create_rag_pipeline_with_sourcing(pdf_documents) -> str:
"""Query PDF documents using a parallel processing approach.
Args:
pdf_documents: A list of PDF document objects.
Returns:
The answer to the query based on the PDF documents content.
"""
# Create a vector store from PDF documents
vector_store = Chroma.from_documents(documents=pdf_documents, embedding=OpenAIEmbeddings(), collection_name="pdf")
retriever = vector_store.as_retriever()
# Custom prompt for PDF documents querying
template_text = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:"""
custom_prompt = PromptTemplate.from_template(template_text)
# Setup parallel processing chain for querying
rag_chain_with_source = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
).assign(
answer=(
RunnablePassthrough.assign(
context=(lambda x: format_documents(x["context"]))
)
U+007C custom_prompt
U+007C llm
U+007C StrOutputParser()
)
)
# Execute the query and return the response
return rag_chain_with_source
# Example usage of the function to query PDF documents
rag_pipeline_with_sourcing = create_rag_pipeline_with_sourcing(pdf_document)
Let’s check the results for the Department of Economy & Tourism (DET):
rag_pipeline_with_sourcing.invoke("What are the functions of the DET?")
>>> {'context': [Document(page_content=' \n Executive Council Resolution No... ',
metadata={'page': 5, 'source': 'dubai_law.pdf'})],
'question': 'What are the functions of the DET?',
'answer': 'The functions of the DET (Department of Economy and Tourism)
include qualifying tour guides, determining tourist destinations, and
exercising any other duties or powers that fall within the functions
of the DET under the legislation in force.'
}
Fragment from the PDF for comparison:

Let’s ask another question regarding the fines:
# Question #1
rag_pipeline_with_sourcing.invoke(
"What is the fine for conducting Tourist Transport Activity
with no Permit?"
)
>>> {'context': [Document(page_content=' \nExecutive Council Resolution No ... ',
metadata={'page': 8, 'source': 'dubai_law.pdf'})],
'question': 'What is the fine for conducting Tourist Transport Activity
with no Permit?',
'answer': 'The fine for conducting Tourist Transport Activity without a
Permit is 10,000 dirhams.'}
# Question #2
rag_pipeline_with_sourcing.invoke(
"What is the fine if my permit expired and I continued conducting
Tourist Transport Activity?"
)
>>> {'context': [Document(page_content=' \nExecutive Council Resolution ... ',
metadata={'page': 13, 'source': 'dubai_law.pdf'})],
'question': 'What is the fine if my permit expired and I continued conducting
Tourist Transport Activity?',
'answer': 'The fine for conducting Tourist Transport Activity after expiry
of the Permit is 2,000 dirhams.'}
Fragment from the PDF for comparison:
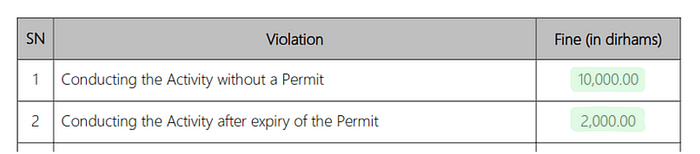
Incredible! Not only were our answers correct, we also got the source of the answer to check the results (metadata={‘page’: 13, ‘source’: ‘dubai_law.pdf’})
This is the end of Part 3a. Talking to Documents: Load and Split. In Part 3b, we’ll discuss Embeddings, Vectorstores, and Indexes. Stay tuned!
LangChain 101 Course (updated)
LangChain 101 course sessions. All code is on GitHub. LLMs, Chatbots
medium.com
If you’re interested in Large Language Models, check Part 2 of the series:
LangChain 101: Part 2ab. All You Need to Know About (Large Language) Models
The Models component is the backbone of Langchain. It is the core that is responsible for token generation that makes…
pub.towardsai.net
Clap and follow me, as this motivates me to write new parts and articles 🙂 Plus, you’ll get notified when the new part will be published.

Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

