



Image Classification with Neural Network
Last Updated on January 4, 2022 by Editorial Team
Author(s): Mugunthan
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Deep Learning
A feedforward neural network is an artificial neural network wherein connections between the nodes do not form a cycle. As such, it is different from its descendant: recurrent neural networks.
The feedforward neural network was the first and simplest type of artificial neural network devised.In this network, the information moves in only one direction — forward — from the input nodes, through the hidden nodes (if any) and to the output nodes. There are no cycles or loops in the network.
— reference from Wikipedia
A Convolution neural network(CNN) is a deep learning algorithm that takes images as input, learn objects/aspects from image and differentiate each image. In primitive methods, filters are hand-engineered and applied to images. Using CNN, filters are learned from the images with enough training.
Why CNN over feedforward neural network?
An Image is nothing but a matrix, why not flatten it into a 1D array and input it into a feed-forward network?.
Let me explain this with an example, Consider an Image with spatial dimensions (64 x 64 x 3), which is converted to dimension (12288 x 1).
Now even if the first layer of the model contains 10 neurons, learnable parameters become 10*12288 = 122880 for a single layer. This will increase the number of learnable parameters in the model and thus computations also increase.
In the case of CNN, the image is fed as such ie. (64 x 64 x 3). convolution layers are a set of filters convoluted over input volume.
These filters or kernel matrices here act as learnable parameters. Hence these will be updated on each iteration of the datasets. So how does it reduce the learnable parameter? It is still the same number!!
The answer is No! Because weights that are learned at a particular depth can be applied to other depths. So a number of parameters are not the same.
So how can we compute the dimensions of the output?
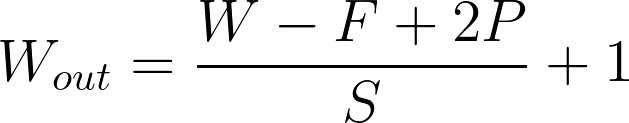
W- dimension of the image, F- Filter Dimension, P- Padding, S- Stride
The stride S controls the size of the step by which the filter is moving. The padding P controls the size of the output by adding zeros (or other values) to the border of the input.
Convolutional Neural networks will easily have a million learning parameters because of the data that they are learning from. This is also one of the reasons there are limited resources on mobile CNN which can lack computational power.
Transfer Learning will help everyone to model without actually training the entire model.
Tensorflow has Object Detection API and model zoo to help with detection and classification problems.
- models/research/object_detection at master · tensorflow/models
- models/tf2_detection_zoo.md at master · tensorflow/models
Image Classification with Neural Network was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")