



How To Read a Machine Learning Paper in 2023 for Beginners
Last Updated on August 29, 2023 by Editorial Team
Author(s): Boris Meinardus
Originally published on Towards AI.
Actionable tips to help with keeping sane during the AI research boom.
I have read dozens of machine learning papers and am starting to get the hang of how to approach studying a paper.
This first involves understanding what the goal of reading a specific paper is! I have found there to be about 3 main reasons, each of which involves slightly different techniques and is an equally important part of doing research.
Stay up to date with the hype
Before we talk about how to really dive deep into a paper, we’ll look at the first reason to read a paper. To stay up to date with the latest breakthroughs and hype. Here, you want the highest level of understanding.
Even if you are a computer vision researcher, you should know about the greatest developments of Large Language Models. And I’m not trying to fuel your “FOMO”, but I think it is important to be able to hold meaningful small talk with other researchers, or ideally get lucky and learn about a new technique that you can apply to your own research.
Now, before you get to skimming the new paper, you first need to know about what the newest and hottest publication is. Therefore, I recommend simply following big AI Labs on Twitter, now called X, and LinkedIn, but also some AI news personalities like Lior S. or
Aleksa Gordić. Often when people post about a paper they give a summary of the main contributions and results.
Nevertheless, if you want to give the paper a look yourself, you should start to read the Abstract to get a feeling for what the paper is about. The Abstract is the most condensed summary of the paper by the authors themselves. It usually already includes their main results, “We are better and/ or more efficient than the other models”. But it might be cool to see really how much better and what its main advantages are.
If the abstract doesn’t highlight the main contributions of the paper, you might need to look for them in the introduction OR use AI to learn about AI! There, of course, already are LLM tools that can assist you with reading a paper. You can, e.g., literally ask a completely free tool like the SciSpace Copilot to summarise the paper or list the main contributions, which usually works really well!
Remember, we need to know what our goal of “reading” the paper is. In this case, we simply want a high-level understanding of what is happening. So, really, AI news personalities on Twitter, LinkedIn, and (for a bit delayed updates) on YouTube are really, really great!
Exploring ideas for your own research
Again, before we get to the reason you probably want to hear the most, we’ll briefly talk about the second reason for reading a paper: Exploring ideas for your own research.
What are new techniques, datasets, or more efficient implementations that might be interesting for you to adopt? There were about 1,000 papers accepted to ICLR alone in 2022. There is absolutely no chance that you can read all of them thoroughly. Besides the hype papers, you will probably want to look at new ideas and insights in your research domain. And if you really break it down, many papers present one core new idea that often is really simple.

E.g. if you are working on Language Models, the basic idea of Contrastive Decoding [1] pretty much just says “Have a powerful and weaker Language Model generate their output logits for the next token and subtract them element-wise for the new output logits. This will yield more diverse results”.
This process, as you might have thought, involves a lot of exploration. Mainly, either by simply googling a paper, going through the list of publications of a conference, or, even more naturally, by recursively looking at the references made in papers you are already reading. Eventually, we again want to read the Abstract and will hopefully find the main idea and its performance improvements, i.e., main results, always keeping in the back of our minds; how can this help me for my research? But since we are in 2023 and onwards, if you don’t understand the main idea straight away, you can again ask AI tools to extract main contributions, novelty, and results and have it explain concepts in simple terms. In fact, in some cases, we can also directly ask to compare the new approach to another one!
Another thing to look at is the architecture diagram, if there is one of course. This often allows you, at a glance, to get an overview of the flow of the model or pipeline.
Integrating into your own research – diving deep
If you now feel like this paper, with its main idea and results, is so fitting to your own research, we finally get to the last reason of reading a paper. Really getting into the nitty gritty details to potentially integrate it into your own research and build on top of it.
Straight up, if there is a video or Blog post on this paper, it is a jackpot! In my opinion, it’s often best to start with a YouTube video or blog post and then read the paper. That way, you know what to expect and pay most attention to and already have a fundamental understanding. The paper lingo is very sophisticated and (arguably) unnecessarily tough.
Now, we should look at the paper. Especially if there is no video or blog post, you will need to, if you haven’t already, start with the Abstract and then go to the Results. If you want to build on top of this paper, it might be very useful to have a look at the datasets that they use for training and evaluation. If available, you might want to use those yourself!
Now to the Methodology section. To really understand the model, I would recommend you start by looking at the model diagram. As mentioned, that will give you a feeling for the flow of data. Afterward, start reading the text explaining this model. On a fundamental level, a bit over-simplified, deep learning models are just a series of reshaping operations on some matrices or tensors. So if you look at individual blocks of the model, there will be an input with a certain shape and an output, with its respective shape. And in the text, there might be some maths formalizing this transformation.
I can not emphasize this enough. You need to always understand how the data dimensions, i.e., its shape change.
What I love to do is always write down the shapes after each operation and then the final block. If I do this step by step, it isn’t as overwhelming as it looks in the end, and it helps me tremendously!
And here is a PRO TIP. If there exists code to the paper: download it and step through it with the debugger in VSCode. This means either looking at the author's own implementation referenced in the paper, looking at third-party implementations on papers with code, or, in my opinion even easier, just importing and running a huggingface model and stepping through their very nice implementation.
What you are looking for is to match the individual code operations or modules to the model diagram and maths formulas in the paper. And again, ALWAYS look at and understand the dimensions of the input and output.
Now, when it comes to math formulas, they often look very scary but mean simple things! Especially if you look at the loss function. Very often, the authors will use a common loss, like the negative log-likelihood, Cross entropy, the Mean Square Error, and so on. But even if they formulate a completely new loss, it’s just a mathematical formulation of a human idea.
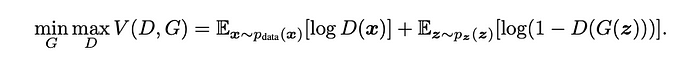
E.g., Train the discriminator to recognize real images as real and generated images as fake. Then, train the generator to produce images so that the discriminator thinks they are real. And rinse and repeat.
You can, yet again, use AI to help you explain those formulas! We are really living in fascinating times!
Using those different techniques, AI tools, VSCode debugging, simply looking at paper explanation videos or blogs, looking at the data shapes or dissecting the loss, whenever you find something you don’t understand or whenever you have an “aha!”-moment, you should always highlight and take your own notes.
Of course, there are really difficult papers, very theoretical or maths-heavy ones, or papers at the intersection of AI and Science that involve a lot of further domain knowledge. In the end, the solution to really understanding a paper is always the same. Keep going. If you don’t understand an idea in the beginning when reading a paper, don’t worry. Continue reading, and it will probably become clearer. If the paper you are currently reading is not giving enough explanations for referenced techniques, go to the papers they reference and read those.
Another pro tip I like is to think of what and how the researchers might have talked about their ideas during a simple coffee break.
I know… it might be annoying, but I promise, the beginning is always the hardest. This knowledge that you struggle with building up, in the beginning will help you in the future go through new papers with a lot less trouble! Again, I promise!
Summary of actionable tips
So, to briefly summarise the actionable tips:
- I pretty much always start by reading the Abstract, then the Results, and then the Methodology section.
- Use other sources like YT or Blogs. The paper lingo is often very condensed and thus often tough.
- If there is code: Use the debugger to step through the code and always understand the shapes of input and output
- And finally, don’t hesitate to use AI tools like the SciSpace Copilot to help you summarize and extract main contributions, make the language more simple, and explain some maths formulas.
I will be doing a lot more of those Paper Explanation blog posts (and YouTube videos!!). I hope that my summaries and explanations make it easier for you to follow along with the progress in AI, and if you don’t want to miss future posts, don’t forget to leave a follow!
P.S.: If you like this content and the visuals, you can also have a look at my YouTube channel, where I post similar content but with more neat animations!
References
[1] Contrastive Decoding, X. L. Li et. al, 2023, https://arxiv.org/abs/2210.15097
[2] Generative Adversarial Networks, I. J. Goodfellow et. al, 2014, https://arxiv.org/abs/1406.2661
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



