



Harness the Power of Vector Databases: Influencing Language Models with Personalized Information.
Last Updated on July 17, 2023 by Editorial Team
Author(s): Pere Martra
Originally published on Towards AI.
Supercharge your language models with Vector Databases! Personalize prompts using your own data to shape the behavior of these powerful models, giving context to them. Integrate personal information for a tailored language generation experience.
In this article, we will learn about how two new technologies: vector databases and large language models, can work together. This combination is currently causing significant disruption in the technology industry.
It is often used to incorporate your own documentation, or enterprise knowledge databases, that the language model hasn’t been trained on. The idea is to ensure that such information is considered when generating model responses. It’s about giving your language model access to your useful information that can make its outputs better, more relevant, or both.
That’s the use case we’ll be exploring. Here are the steps we’ll follow:
- Creating the Vector Database using ChromaDB.
- Storing information in the database.
- Retrieving information through a query.
- Generating an extended prompt using this information.
- Loading a model from Hugging Face.
- Passing the prompt to the model.
- The model will provide a response, taking the provided information into account.
By following these steps, we can use ChromaDB to easily add personal information to the language model’s decision-making process.
This way, we can obtain highly customized and contextually relevant responses.
Let’s dive into each step and unlock the full potential of this approach!
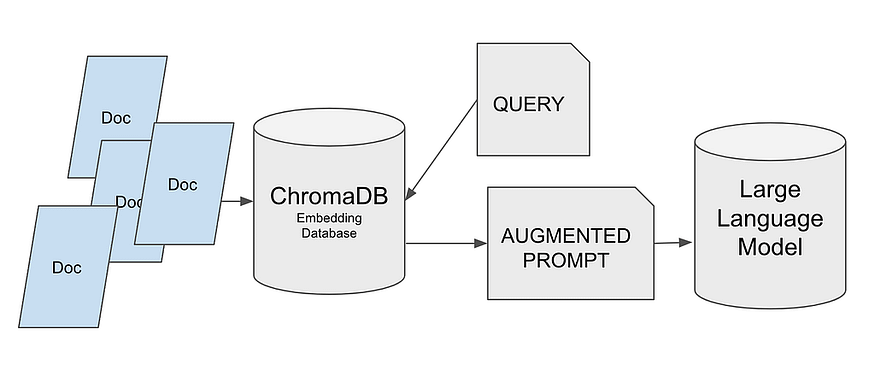
But before we dive in, let’s have a brief introduction to how Vector Databases work.
How do vector databases work?
First, these Databases store vectors, as their name suggests. We need to transform the text we have into information that can be stored in these tools. In other words, we need to convert our text into vectors.
There are various approaches available, but in summary, they all convert a sequence of text, which can be words, syllables, or phrases, into vectors.
The vectors we obtain are multidimensional, and naturally, we can calculate the difference between one vector and another or search for vectors that are closer to a specific one.
With this information, we can understand how it works in a general way.
- We convert the text into vectors and store them.ç
- We convert the text to be searched into vectors and compare them.
- It selects the closest vectors.
- These vectors are then converted back into text and returned.
Let’s forget about text searches! It’s all about vector comparisons.
As you may have already guessed, the process of converting text to vectors should be the same for both the stored text and the text to be searched. Otherwise, the comparison would be meaningless.
Vector Databases are gaining increasing importance, not only for cases like ours where we search for related news but also for any recommendation system.
Indeed, vectors are essentially numerical representations, and they don’t necessarily have to originate from text. We can store movies transformed into vectors, along with their metadata, and search for the most similar ones. We could even identify patterns that allow us to recommend movies based on user viewing habits. Wait a minute… could it be that Netflix is also using them for their recommendation system? Shall we make a bet?
What technology will we use?
As for the database, I have chosen ChromaDB. It is one of the latest databases to emerge and has gained popularity rapidly. You will see that its usage is extremely straightforward! We won’t need to worry about much because ChromaDB handles most of the work for us. It is an open-source solution that can be seamlessly integrated with LangChain, which is important because, in future articles, we will use LangChain to build increasingly complex solutions.
We will obtain the model from Hugging Face. Specifically, I have used dolly-v2–3b. This is the smallest version of the Dolly Models family. I suggest using smaller versions of models whenever possible.
Personally, I enjoy experimenting with different models whenever I have the opportunity, and Hugging Face offers a vast selection of models to choose from.
If you want to try a different model, you can search for it on Hugging Face and make sure it is trained for text generation.

Let’s get started with the project!
You can find the code in a Notebook on Kaggle, where you can fork, run, and experiment with it. It is also available on GitHub in a repository where I store all the notebooks from the Large Language Models course, as well as their corresponding articles.
Use a Vectorial DB to optimize prompts for LLMs
Explore and run machine learning code with Kaggle Notebooks U+007C Using data from multiple data sources
www.kaggle.com
GitHub – peremartra/Large-Language-Model-Notebooks-Course
Contribute to peremartra/Large-Language-Model-Notebooks-Course development by creating an account on GitHub.
github.com
If you are interested in following the complete course, it is best to subscribe to the GitHub Repository. This way, you will receive notifications of new lessons or modifications to the existing ones.
Let’s import the necessary libraries.
To get started, we’ll need to install a few Python packages:
- sentence-transformers: This library is necessary for transforming sentences into fixed-length vectors, i.e., for embedding.
- transformers: This package provides various libraries and utilities that facilitate working with transformer models. Even though we may not use it directly, not installing it will result in an error message when working with the model.
- chromadb: Our vector database. It is easy to use, open-source, and fast. It is possibly the most widely used vector database for storing embeddings.
You can install these packages using the following commands:
!pip install sentence-transformers
!pip install xformers
!pip install chromadb
The following two libraries are likely familiar to you: Numpy and Pandas. They are two of the most widely used Python libraries in data science.
Numpy is a library for numerical computing that makes it easy to do math calculations.
Pandas, on the other hand, is the go-to library for data manipulation and analysis.
import numpy as np
import pandas as pd
Load the dataset.
I have prepared the notebook to work with three different datasets available on Kaggle. All the datasets contain news articles but in different formats. Two of them only contain article summaries, while the third one includes the full text of the articles.
Topic Labeled News Dataset
108774 news articles labeled with 8 topics (balanced)
www.kaggle.com
BBC News
Self-updating dataset – BBC News RSS Feeds
www.kaggle.com
MIT AI News Published till 2023
All the AI-related news published by MIT on their website.
www.kaggle.com
The only reason for making the notebook work with three different datasets is to make it easy to experiment and see how the solution reacts to different inputs. Feel free to try as many datasets as you like. It’s about looking at and understanding the solution’s behavior and performance with different data sources.
As we work with limited resources on platforms like Kaggle or Colab, I have set a limit on the number of news articles to load. This limit is defined by the variable MAX_NEWS.
The field name that contains the news article has been assigned to the variable DOCUMENT, while what could be considered metadata or categories is stored in the variable TOPIC. This way, we isolate the rest of the notebook from the specific dataset we choose to use.
You just need to remove the comment marker for the dataset you want to use it.
news = pd.read_csv('/kaggle/input/topic-labeled-news-dataset/labelled_newscatcher_dataset.csv', sep=';')
MAX_NEWS = 1000
DOCUMENT="title"
TOPIC="topic"
#news = pd.read_csv('/kaggle/input/bbc-news/bbc_news.csv')
#MAX_NEWS = 1000
#DOCUMENT="description"
#TOPIC="title"
#news = pd.read_csv('/kaggle/input/mit-ai-news-published-till-2023/articles.csv')
#MAX_NEWS = 100
#DOCUMENT="Article Body"
#TOPIC="Article Header"
#Because it is just a course we select a small portion of News.
subset_news = news.head(MAX_NEWS)
Let’s import and configure the Vector Database.
First, we will import ChromaDB, followed by its Settings class from the config module. This class allows us to modify the configuration of the ChromaDB system and customize its behavior.
import chromadb
from chromadb.config import Settings
Now that we have imported the library, let’s create a settings object by calling the imported Settings class.
The settings object will be created with two parameters.
- chroma_db_impl: We will indicate the implementation to use for the database and the format in which we will store the data. I won’t go into the specifics of all the various choices, but I will explain the motivations behind the ones I chose:
— For the implementation, we have selected “duckdb”. It offers excellent performance as it operates mostly in memory. And is fully compatible with SQL.
— As for the data format, we will be using “parquet”. It is the optimal choice for tabular data. Parquet provides a good compression ratio and offers high performance for querying and processing data. - persist_directory: This parameter contains the path where we want to save the information. If we do not specify it, the database will be in-memory and not persistent. However, working purely in-memory can cause issues in cloud or collaborative environments like Kaggle, as it may attempt to create a temporary file.
settings_chroma = Settings(chroma_db_impl="duckdb+parquet",
persist_directory='./input')
chroma_client = chromadb.Client(settings_chroma)
Working with the data in ChromaDB.
Data in ChromaDB is organized into collections. Each collection must have a unique name, so if we try to create a collection using an existing name, it will throw an error.
To achieve this, we will check if the collection exists in the list of ChromaDB collections. If it does, we will delete it before creating it again. It’s important to note that this approach is suitable for testing and experimentation in this notebook. A different strategy should be implemented in a production environment.
Alternatively, we could have created three separate collections, one for each dataset. I’ll leave that idea here, in case you want to modify the notebook and adapt it to your preferences.
collection_name = "news_collection"
if len(chroma_client.list_collections()) > 0 and collection_name in [chroma_client.list_collections()[0].name]:
chroma_client.delete_collection(name=collection_name)
collection = chroma_client.create_collection(name=collection_name)
After creating the collection, we are ready to add our data to the ChromaDB database. We can do this by calling the `add` function and providing the document, metadata, and a unique identifier for each record.
The document can be of any length and will include the entire contents of our document. Depending on the length of the documents we want to store, we can consider splitting them into smaller parts, such as pages or chapters. We should keep in mind that the information returned by the database will be used to create the context of our prompt, and that these prompts do have limitations in terms of the length they can reach. Therefore, it’s important to consider the trade-off between the length of the documents and the prompt’s length limitations when designing our system.
In this example, we will use the entire document information to create the prompt. However, in more advanced projects, we can employ another model to generate a summary of the returned information. This allows us to create a prompt with less content but with more relevance. We will explore this approach further when we dive into how LangChain works.
The metadata is not used in the vector search itself. Metadata is used to store categories or additional information that can be used in post-filtering to refine the results.
As for the unique identifier, we can easily generate it using Python. It can be as simple as generating numbers from 0 to MAX_RANGE.
collection.add(
documents=subset_news[DOCUMENT].tolist(),
metadatas=[{TOPIC: topic} for topic in subset_news[TOPIC].tolist()],
ids=[f"id{x}" for x in range(MAX_NEWS)],
)
Once we have the information stored in ChromaDB, we can perform queries and retrieve documents that match the desired topic or search query.
As mentioned earlier, the results are returned based on the similarity between the search terms and the content of the documents.
It’s important to note that metadata is not used in the search process. The comparison is performed solely based on the content of the document itself.
results = collection.query(query_texts=["laptop"], n_results=10 )
print(results)
In the `n_results` parameter, we specify the maximum number of documents we want to be returned.
Let’s see the response:
{‘ids’: [[‘id173’, ‘id829’, ‘id117’, ‘id535’, ‘id141’, ‘id218’, ‘id390’, ‘id273’, ‘id56’, ‘id900’]], ‘embeddings’: None, ‘documents’: [[‘The Legendary Toshiba is Officially Done With Making Laptops’, ‘3 gaming laptop deals you can’t afford to miss today’, ‘Lenovo and HP control half of the global laptop market’, ‘Asus ROG Zephyrus G14 gaming laptop announced in India’, ‘Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865)’, “Apple’s Next MacBook Could Be the Cheapest in Company’s History”, “Features of Huawei’s Desktop Computer Revealed”, ‘Redmi to launch its first gaming laptop on August 14: Here are all the details’, ‘Toshiba shuts the lid on laptops after 35 years’, ‘This is the cheapest Windows PC by a mile and it even has a spare SSD slot’]], ‘metadatas’: [[{‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}, {‘topic’: ‘TECHNOLOGY’}]], ‘distances’: [[0.8593593835830688, 1.02944016456604, 1.0793330669403076, 1.093000888824463, 1.1329681873321533, 1.2130440473556519, 1.2143317461013794, 1.216413974761963, 1.2220635414123535, 1.2754170894622803]]}
As we can see, it has returned 10 news articles. They are all very short but related to laptops. Interestingly, not all of them contain the word “laptop.” How is this possible?
Imagine that vectors are represented in a multidimensional space, where each vector represents a point in that space. The similarity between vectors is determined by measuring the distance between these points. Let’s imagine a two-dimensional space and take one of the returned phrases as an example to represent the words in that space.
‘Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865)’
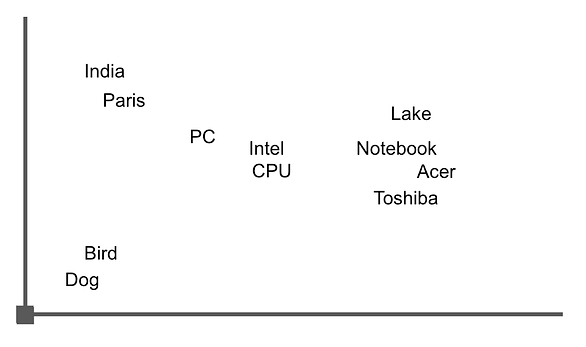
The graph could look similar to this image, where we can see that words related to “notebook” are clustered closely together. By calculating the distance between them using vector arithmetic, we can retrieve sentences or documents that contain these words.
Now that we have the data and a basic understanding of how the search works, we can start working with the model.
Let’s load the model from Hugging Face and create the prompt.
Now it’s time to start working with the libraries from the Transformers universe. The immensely popular library maintained by Hugging Face provides access to an incredible number of models.
Let’s import the following utilities:
- AutoTokenizer: This tool is used for tokenizing text and is compatible with many of the pre-trained models available in Hugging Face’s library.
- AutoModelForCasualLM: Provides an interface for using models specifically designed for text generation tasks, such as the ones based on GPT. In our mini-project, we are using the model databricks/dolly-v2–3b.
- Pipeline: This allows us to create a pipeline that combines different tasks.
The model I have selected is dolly-v2–3b, which is the smallest model in the Dolly family. Even so, it still has 3 billion parameters. This model is more than sufficient for our small experiment, and based on the tests I have conducted, it seems to perform better in this case compared to GPT-2.
However, I encourage you to experiment with different models yourself. My only recommendation is to start with the smallest model available in the family you choose.
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
model_id = "databricks/dolly-v2-3b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
lm_model = AutoModelForCausalLM.from_pretrained(model_id)
After these lines, we now have the tokenizer in the variable `tokenizer` and the model in `lm_model`. We will use these variables to create the pipeline.
In the pipeline call, we need to specify the response size, which I will limit to 256 tokens.
We also provide the value “auto” for the `device_map` field. This indicates that the model itself will decide whether to use CPU or GPU for text generation.
pipe = pipeline(
"text-generation",
model=lm_model,
tokenizer=tokenizer,
max_new_tokens=256,
device_map="auto",
)
Creating the prompt.
To create the prompt, we will use the result of the query we executed earlier on the database. In our case, it has returned 10 articles related to the word “notebook”.
The prompt will consist of two parts:
1. The context: This is where we will provide the information that the model needs to consider in addition to what it already knows. In our case, it will be the result obtained from the query to the database.
2. The user’s question: This is the part where the user can input their specific question or query.
Constructing the prompt is as simple as chaining together the desired texts to end with the desired prompt.
question = "Can I buy a Toshiba laptop?"
context = " ".join([f"#{str(i)}" for i in results["documents"][0]])
#context = context[0:5120]
prompt_template = f"Relevant context: {context}\n\n The user's question: {question}"
prompt_template
Let’s see how the prompt looks like:
“Relevant context: #The Legendary Toshiba is Officially Done With Making Laptops #3 gaming laptop deals you can’t afford to miss today #Lenovo and HP control half of the global laptop market #Asus ROG Zephyrus G14 gaming laptop announced in India #Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865) #Apple’s Next MacBook Could Be the Cheapest in Company’s History #Features of Huawei’s Desktop Computer Revealed #Redmi to launch its first gaming laptop on August 14: Here are all the details #Toshiba shuts the lid on laptops after 35 years #This is the cheapest Windows PC by a mile and it even has a spare SSD slot\n\n The user’s question: Can I buy a Toshiba laptop?”
As you can see, everything is quite straightforward! There are no secrets. We simply tell the model: “Consider this context that I’m providing, followed by a line break, and the user’s question is this.”
From here on, the model takes over and does all the work of interpreting the prompt and generating a correct response.
Let’s obtain the response. All we need to do is call the previously created pipeline and pass it the prompt recently created.
lm_response = pipe(prompt_template)
print(lm_response[0]["generated_text"])
Let’s see the response from the model:
Relevant context: #The Legendary Toshiba is Officially Done With Making Laptops #3 gaming laptop deals you can’t afford to miss today #Lenovo and HP control half of the global laptop market #Asus ROG Zephyrus G14 gaming laptop announced in India #Acer Swift 3 featuring a 10th-generation Intel Ice Lake CPU, 2K screen, and more launched in India for INR 64999 (US$865) #Apple’s Next MacBook Could Be the Cheapest in Company’s History #Features of Huawei’s Desktop Computer Revealed #Redmi to launch its first gaming laptop on August 14: Here are all the details #Toshiba shuts the lid on laptops after 35 years #This is the cheapest Windows PC by a mile and it even has a spare SSD slot
The user’s question: Can I buy a Toshiba laptop?
The answer: No, Toshiba has decided to stop manufacturing laptops.
Perfect! The model has considered the context we provided and has constructed the user’s response correctly, utilizing not only its pre-training knowledge but also the information we passed in the prompt.
Conclusions, next steps.
I suppose you have realized that everything has been much simpler than it seemed at the beginning.
We have used a vector database to store our own information, which we used to construct the prompt for a large language model.
The model has returned the correct response, taking into account the context we provided. You can imagine that this way of working opens up a world of possibilities and complements the fine-tuning of large language models perfectly.
If you want to play around with the notebook, remember that it’s available on Kaggle and GitHub.
Here are some ideas:
1. Use all the datasets that the notebook is prepared for, and if possible, try incorporating a new dataset.
2. Explore different models on Hugging Face and compare the results.
3. Modify the prompt creation process.
Feel free to experiment, iterate, and explore different possibilities. This will help you gain a more in-depth understanding of vector databases, large language models, and their application in natural language processing tasks.
The full course about Large Language Models is available at Github. To stay updated on new articles, please consider following the repository or starring it. This way, you’ll receive notifications whenever new content is added.
GitHub — peremartra/Large-Language-Model-Notebooks-Course
Contribute to peremartra/Large-Language-Model-Notebooks-Course development by creating an account on GitHub.
github.com
This article is part of a series where we explore the practical applications of Large Language Models. You can find the rest of the articles in the following list:

Large Language Models Practical Course
View list3 stories


I write about Deep Learning and machine learning regularly. Consider following me on Medium to get updates about new articles. And, of course, You are welcome to connect with me on LinkedIn.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

