



Face Aging Using Conditional GANs
Last Updated on July 25, 2023 by Editorial Team
Author(s): Manish Nayak
Originally published on Towards AI.
Age-cGANs Explained U+007C Towards AI
An Introduction to Age-cGANs
Introduction
Conditional GANs (CGANs) are extensions of the GANs model. You can read about Conditional GANs in my previous post here. In this post, I will try to explain how we can implement a CGANs to perform automatic face aging. Face Aging cGAN(Age-cGANs) introduced by Grigory Antipov, Moez Baccouche, and Jean-Luc Dugelay, in their paper with titled Face Aging With Conditional Generative Adversarial Networks.
High-Level CGANs’s Architecture Diagram
Age-cGANs’s Architecture
The Face Aging-cGan has four networks.
An Encoder : It learns the inverse mapping of input face images and the age condition with the latent vector Z.
- Encoder network generates a latent vector of the input images. The Encoder network is a CNN which takes an image of a dimension of (64, 64, 3) and converts it into a 100-dimensional vector.
- There are four convolutional blocks and two dense layers.
- Each convolutional block has a convolutional layer, followed by a batch normalization layer, and an activation function except the first convolutional layer.
A FaceNet : It is a facial recognition network that learns the difference between an input image x and a reconstructed image x’.
- FaceNet recognizes a person’s identity in a given image.
- A pre-trained Inception, ResNet-50 or Inception-ResNet-2 model without fully connected layers can be used.
- The extracted embeddings for the real image and the reconstructed image can be calculated by calculating the Euclidean distance of the embeddings.
A Generator Network: It takes a hidden representation of a face image and a condition vector as input and generates an image.
- The Generator network is a CNN and it takes a 100-dimensional latent vector and a condition vector y, and tries to generate realistic images of a dimension of (64, 64, 3)
- The Generator network has dense, upsampling, and convolutional layers.
- It takes two input one is a noise vector and second is a condition vector.
- The condition vector is the additional information that is provided to the network. For the Age-cGAN, this will be the age.
A Discriminator Network: It tries to discriminate between the real images and the fake images.
- The Discriminator network is a CNN and it predicts the given image is real or fake.
- There are several convolutional blocks. Each convolutional block contains a convolutional layer followed by a batch normalization layer, and an activation function, except the first convolutional block, which doesn’t have the batch normalization layer.

Aging-cGANs’s training
Age-cGAN has four networks, which trained in three steps.
Conditional GAN training: Generator and Discriminator network training.
- cGAN training can be expressed as an optimization of the function v(θG, θD), where θG and θD are parameters of G and D, respectively.

Where
- log D(x,y) is the loss for the Discriminator model.
- log(1-D(G(x,y’),y’)) is the loss for the Generator model.
- P(data) is the distribution of all possible images.
Initial latent vector approximation: Encoder network training.
- Initial latent vector approximation method uses to approximate a latent vector to optimize the reconstruction of face images.
- The encoder is a neural network which approximates a latent vector.
- We train the encoder network on the generated images and real images.
- Once trained, the encoder network will start generating latent vectors from the learned distribution.
- The training objective function for training the encoder network is the Euclidean distance loss
Latent vector optimization: Optimization of both Encoder and Generator network together.

Where
- FR is the face recognition network to recognize a person’s identity in an input face image x
- Above equation is the Euclidean distance between the real image x and the reconstructed images x’ and it should be minimal.
- Minimizing this Euclidean distance should improve identity preservation in the reconstructed image.



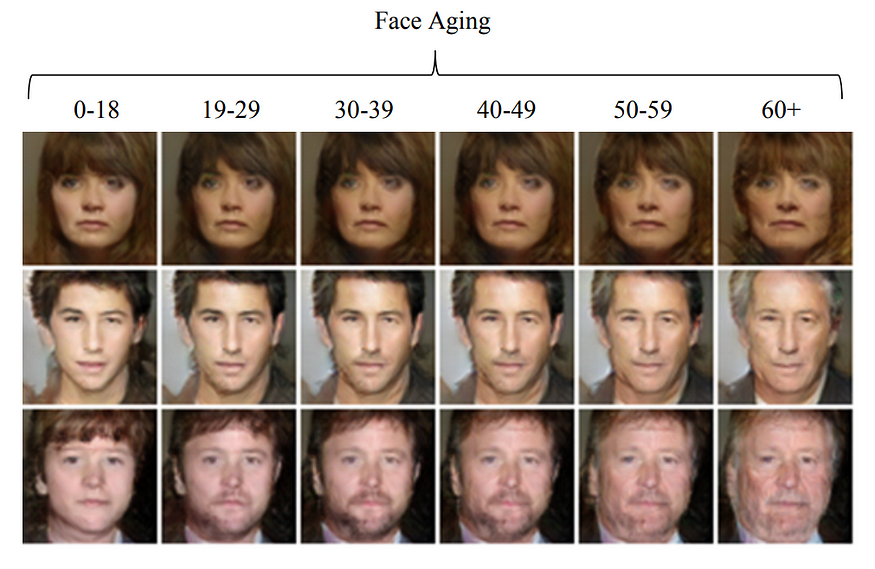
- Image (a) is the original test images.
- Image (b) is reconstructed images generated using the initial latent approximations z0.
- Image (c) is reconstructed images generated using the “Pixelwise” and “Identity-Preserving” optimized latent approximations: z ∗ pixel and z ∗ IP.
- Image (d) is aging of the reconstructed images generated using the identity-preserving z ∗ IP latent approximations and conditioned on the respective age categories y (one per column).
Accompanied jupyter notebook for this post can be found on Github.
Conclusion
Age-cGANs can also use to build Face Aging system, Age synthesis and age progression have many practical industrial and consumer applications like cross-age face recognition, finding lost children, entertainment, visual effects in movies.
I hope this article provides a good explanation and understanding about Age-cGANs and it will help you get started building your own Age-cGANs.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

