



Diffusion Models — my “second?” artist.
Last Updated on July 17, 2023 by Editorial Team
Author(s): Albert Nguyen
Originally published on Towards AI.
Diffusion Models are one of the most popular algorithms in Deep Learning. It is widely used in many applications, such as image generation, object detection, and text-to-image generation. In this article, I will explain how the diffusion models work (Link to paper Denoising Diffusion Probabilistic Models)
The main idea of the algorithm is to have 2 stochastic processes:
- Forward process (Diffusion process)
- Reverse process
Where the forward process is a fixed Markov Chains, and the reverse process is, typically, an Unet for generating images. The following will go into detail about the two processes.
The two processes are in detail
If you are not familiar with the Stochastic processes, the following may give you a headache. To the best of my knowledge, I will explain it intuitively.
The forward process
The process is a fixed Markov Chain with Gaussian transition with a variance schedule β1, …, βT. At each time step, the process will add a Gaussian noise with a given variance to the image.

Intuitive explanation
Say each image is a data point, then your entire dataset will form a distribution. The transition q(x_t U+007C x_t-1) tells us the distribution of the next state x_t given the current state x_t-1. Then, the forward process can be done by recursive sample data from a given distribution. Or, mathematically, we have the closed form:
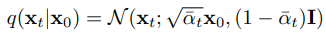
Where α_t:= 1 − βt and α¯t is the cumulative product of a_0 to a_t. Then we can sample directly x_t from x_0 given the scheduled variance. And when the time step T is large enough, note that (1-βt) < 1, α¯t will reach to 0. This means the distribution of x_T will be approximate, a standard multivariate Gaussian.
The reverse process
This process is our deep learning model, where you sample some random noise and get an image. BUT how does it work? As above I mentioned that, we could treat our dataset as a distribution. Hence, if we find some way to sample a data point from it, we’ll get a real-looking image.
Then the task for our model is to learn to sample the data distribution by trying to reverse the forward process. Particularly, in generating, the inputs of model, x_T, will be in standard Gaussian, then it reverses the process with learned Gaussian transition:

> Training
- Given an input image, the forward process will sample x_t
- the sampled x_t will then feed into the model and try to predict the image
The loss is then computed by:
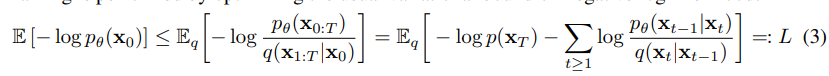
This can be explained as the KL divergence between the distribution of the transition of the two processes. In practice, this formula is simplified to:
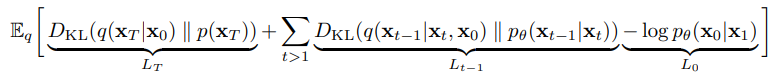
There is quite a lot of math and other parameterizations to get to this, so I left it for you who are interested in reading the paper.
Why is KL Divergence?
KL Divergence tells us the long distance between the two distributions. What we want is to make the distribution of the generated images will be similar to the distribution of the images in the dataset. Then by minimizing the KL Divergence, the distribution of generated images will be pushed close the real distribution.
- Pondering: This is not the only function that can tell how far the 2 distributions are. Indeed, in training GAN for a similar task, sometimes we use “earth-mover-distance” (Wasserstein Loss). But why is the KLD chosen?
Train a model to generate a celeb face.
I used the excellent work from lucidrains/denoising-diffusion-pytorch to train on the CelebA dataset on Kaggle. My notebook

THANK YOU
This is my first article to share the knowledge I gain during my internship. I hope what I share here can help others. If you found this helpful but there is something missing, please share your thought in the comment. I will very much appreciate it.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

