



Choosing a Learning Rate for DNNs
Last Updated on December 26, 2022 by Editorial Team
Author(s): Toluwani Aremu
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
During the application process for an AI-based company, I was given a take-home assessment that included a machine learning task. One of the challenges was improving the performance of a custom deep convolutional neural network (DCNN) on a small, straightforward dataset (MNIST). The DCNN was not performing well on the test set. Upon reviewing the code, I couldn’t identify any issues with the setup. In fact, the hyperparameters used were consistent with those commonly seen in online tutorials (i.e. learning rate [lr] was 1e-3). During my early days learning about artificial intelligence, I took an online course called the Stanford Machine Learning course by Andrew Ng on Coursera. In one lecture, Ng explained that large learning rates can lead to unstable learning and make it harder for models to converge.
Returning to my story, I didn’t realize that the rule I learned from the lecture had other factors to consider. Believing that the learning rate was too high and should be reduced, I changed it from 1e-3 to 3e-4. Unfortunately, this didn’t improve the poor performance on the test set, although it did improve the performance on the training set. This was extremely frustrating! I then increased the learning rate to 1e-1 (a relatively large value) and was surprised to see that the test performance improved. However, the effectiveness of a large learning rate can depend on the complexity of the dataset. For example, it may work well on a simple dataset like the one I was working with, but not as well on a more complex one. Additionally, it’s possible that a learning rate that seems too large to be effective could actually be the optimal value for a particular task.
How do you choose the optimal learning rate for your task? Let’s perform a quick practical experiment to observe the effects of different learning rates using the Adam optimizer to train a custom 7-layer convolutional neural network on the complex CIFAR-100 dataset. Below is the architecture built with Pytorch.
class CNN(nn.Module):
def __init__(self, img_channels=3, num_classes=100):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=img_channels, out_channels=16, kernel_size=3, stride=2, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2)
self.act = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=16, out_channels=64, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1)
self.conv5 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1)
self.conv6 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1)
self.conv7 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=3, padding=1)
self.fc = nn.Linear(in_features=1024, out_features= num_classes)
self.ln = nn.Flatten()
def forward(self, x):
x = self.act(self.conv1(x))
x = self.pool(self.act(self.conv2(x)))
x = self.act(self.conv3(x))
x = self.pool(self.act(self.conv4(x)))
x = self.act(self.conv5(x))
x = self.pool(self.act(self.conv6(x)))
x = self.ln(self.act(self.conv7(x)))
x = self.fc(x)
return x
The following plots show the training loss and test accuracy for four different learning rates: 1e-1, 1e-3, 3e-4, and 625e-5.

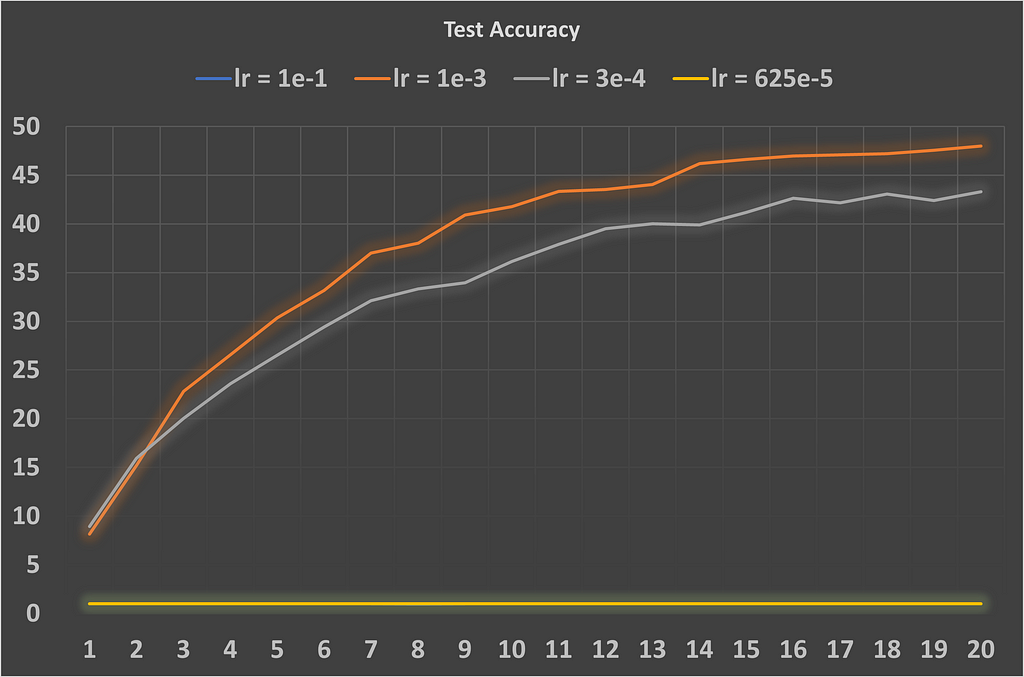
In this example, we can see that the CNN model’s test performance suffers when the learning rate is either too high (1e-1) or too low (625e-5). While using learning rates of 1e-3 and 3e-4 resulted in a gradual decline during training, the model was unstable with the other learning rates. It’s also worth noting that the 3e-4 learning rate seems to converge more slowly than 1e-3 on the CIFAR-100 dataset. To play with different learning rate values and observe the results, edit this code on kaggle.
Choosing the optimal learning rate can be a challenging task. This article aims to address and shed light on this topic. Let’s start with a standard definition.
WHAT IS LEARNING RATE IN DNN?

The learning rate is a hyperparameter that controls the step size at which a model updates its weights during training. It determines how fast or slow the model learns, and it’s an important factor in the model’s overall performance.
Furthermore, the learning rate determines how much the model’s weights are adjusted in response to the error it receives from the loss function. If the learning rate is too small, the model will take a long time to converge to a good solution, but it will be more stable. On the other hand, if the learning rate is too large, the model may never converge or may even diverge, resulting in poor performance. It’s important to find a good balance between these two extremes.
EXTERNAL FACTORS THAT COULD AFFECT LEARNING RATE
There are several factors that can affect the learning rate, including the complexity of the dataset, the type of model being used, the amount of data available for training, and the optimization algorithm being employed. For example, complex datasets may require larger learning rates to make sufficient progress, while simpler datasets may require smaller learning rates to prevent overfitting. The type of model being used can also influence the learning rate. Some models, such as neural networks, may require larger learning rates to learn effectively, while other models, such as linear regression, may be more sensitive to the learning rate.
The amount of data available for training can also influence the learning rate. If the model has a large amount of data to work with, it may be able to afford larger learning rates without overfitting. On the other hand, if the model has a small amount of data, it may be more prone to overfitting, in which case a smaller learning rate may be necessary. The optimization algorithm is used can also affect the learning rate. Some algorithms, such as gradient descent, are sensitive to the learning rate and may require careful tuning to find the best value. Others, such as stochastic gradient descent, are less sensitive to the learning rate and may be able to use larger values without issue.
TECHNIQUES TO USE FOR OPTIMAL LEARNING RATE SELECTION

It’s usually necessary to experiment with different learning rates and carefully monitor the model’s performance to find the best value. However, a manual iteration of these values is time-inefficient and it is better to leverage more automated techniques. There are several strategies for selecting an optimal learning rate for a machine learning model. Some common approaches include:
- Grid search: This involves defining a range of possible learning rates and training the model with each value, evaluating the model’s performance on a validation set for each value. The learning rate that results in the best performance is then chosen as the optimal value. Grid search is a straightforward and reliable method, but it can be computationally expensive, as it requires training the model multiple times.
- Random search: This involves randomly sampling learning rates from a defined range and training the model with each value, evaluating the model’s performance on a validation set for each value. The learning rate that results in the best performance is then chosen as the optimal value. Random search is generally faster than grid search, as it requires fewer model training runs. A drawback is that it may be less reliable, as it relies on random sampling and may not thoroughly explore the range of learning rates.
- Adaptive learning rate methods: These methods adjust the learning rate during training based on the gradient of the loss function. Examples include Adam and RMSProp. These methods can often find good learning rate values without the need for explicit tuning. With this advantage over other optimizers, initiating with a poor choice of learning rate could lead to them never converging. They may not always find the absolute optimal value, and they may require more computational resources than other methods.
- Learning rate schedulers: One strategy for selecting an optimal learning rate is to use a learning rate schedule, which starts with a high learning rate and gradually decreases it over time. This allows the model to make rapid progress at the beginning of training while still fine-tuning its weights as training continues. I personally find this approach to be effective. There are several types of learning rate schedulers available in PyTorch that I have used during experimentation. While learning rate schedules can be useful in cases where the model’s performance plateaus or starts to decline after a certain number of training epochs, they may require careful tuning to find the optimal schedule and may not always produce the best possible results.
As stated above, the optimal learning rate can depend on the complexity of the dataset, the type of model being used, the amount of data available for training, and the optimization algorithm being employed. As such, it may be necessary to experiment with different learning rates and carefully monitor the model’s performance to find the best value. Using the techniques listed above would help in the optimal learning rate selection and make training easier.
If you enjoyed reading this article, please give it a like and follow. For questions, please use the comment section. If you want to chat, reach out to me on LinkedIn or Twitter.
Choosing a Learning Rate for DNNs was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")