



Backtesting Strategy for ML Models
Last Updated on July 26, 2023 by Editorial Team
Author(s): Dr. Samiran Bera (PhD)
Originally published on Towards AI.
A form of cross-validation across time
Model performance is critical to any business process and must be validated periodically. To establish the efficacy of model performance, business organizations often resort to techniques such as cross-validation. Leave-one-out and k-fold cross-validation is widely used in this context. Besides these, business often needs to ascertain model performance over time, i.e., time-based cross-validation.
In this article, the purpose is to discuss time-based cross-validation methods that can be easily incorporated to measure and confirm model performance. It is known as backtesting. It is widely used in stock market analysis to predict future stock values. However, it is not restricted to it. It can be used for any time-based cross-validation purposes. The methods or strategies adapted to this end are briefly provided below. Based on the business context and data, appropriate backtesting can be adopted.
Backtesting strategies
There are three simple ways to backtest and validate machine learning (ML) model performance. Similar to cross-validation methods, backtest also divides the data set into training and validation sets (also referred to as hold-out data). Therefore, in a manner, backtesting can be considered an extension of cross-validation.
To validate ML model performance, the validation set can be identified as shown below. Each of these approaches has certain benefits and limitations.
Simple sampling strategy
In this sampling strategy, training and testing dataset are mutually exclusive, even across iterations. The benefit of this approach is its simplicity in terms of implementation and explainability. Further, it can validate ML model performance within the shortest amount of time for large datasets. However, the training of the ML models may suffer due to a lack of significant data volume for smaller datasets.

The python code for simple sampling is provided next.
def simple_batch(batch_start='2021-01-01', batch_end='2022-12-31', train_days = 30, test_days = 15 ):
batch = []
while True:
a = pd.to_datetime(batch_start) - pd.DateOffset(days=train_days)
b = pd.to_datetime(batch_start)
c = pd.to_datetime(batch_start) + pd.DateOffset(days=test_days) batch.append([a, b, c])
if b + pd.DateOffset(days=train_days+2*test_days) > pd.to_datetime(batch_end):
break
else:
batch_start = b + pd.DateOffset(days=test_days+train_days)
return batch
Note: In the python code, b represents the date where training stops and test/validation begins. Therefore, the training data and test/validation date are from a to b and b to c, respectively.
Overlapped strategy
In this sampling strategy, training and testing dataset are mutually exclusive only for the present iteration. The benefit of this approach is its simplicity in terms of implementation and explainability. Further, it can validate ML model performance within a reasonable amount of time for large datasets. However, for small datasets, the training of the ML model may suffer due to a lack of data volume.

The python code for overlapped sampling is provided next.
def overlap_batch(batch_start='2021-01-01', batch_end='2022-12-31', train_days = 30, test_days = 15 ):
batch = []
while True:
a = pd.to_datetime(batch_start) - pd.DateOffset(days=train_days)
b = pd.to_datetime(batch_start)
c = pd.to_datetime(batch_start) + pd.DateOffset(days=test_days) batch.append([a, b, c])
if b + pd.DateOffset(days=train_days+test_days) > pd.to_datetime(batch_end):
break
else:
batch_start = b + pd.DateOffset(days=train_days)
return batch
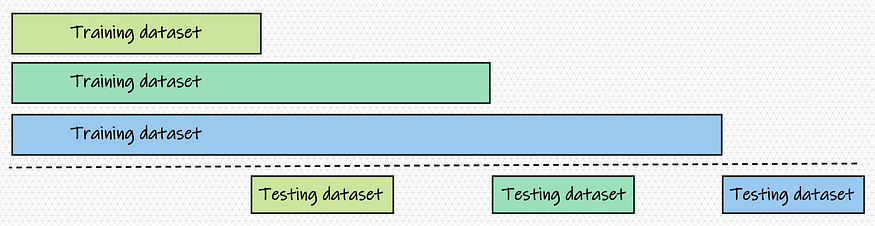
Aggregate strategy
In this sampling strategy, training and testing dataset are mutually exclusive only for the present iteration. Further, the training dataset of successive iterations includes all training data from previous iterations. The benefit of this approach is its ability to provide adequate data volume for ML model training. For small-size problems, it can be adopted to validate ML model performance. However, this approach can result in a longer computational time for large datasets.
The python code for aggregate sampling is provided next.
def aggregate_batch(batch_start='2021-01-01', batch_end='2022-12-31', train_days = 30, test_days = 15, initial_date='2020-01-01' ):
batch = []
a = pd.to_datetime(initial_date)
while True:
b = pd.to_datetime(batch_start)
c = pd.to_datetime(batch_start) + pd.DateOffset(days=test_days) batch.append([a, b, c])
if b + pd.DateOffset(days=train_days+test_days) > pd.to_datetime(batch_end):
break
else:
batch_start = b + pd.DateOffset(days=train_days)
return batch
Note: The starting date for model training is fixed (which is denoted by a). Thereafter, the training date increases in each iteration similar to previous sampling methods.
Note
To understand backtesting in a better way, readers are advised to download any time series or similar problems and execute the above strategies. The above code will provide a training and testing set that needs to be paired with a machine learning model to train and produce forecasts. The progression steps for training and testing should ideally be more than 30 days, if not otherwise directed by the business problems. Further, the performance of the machine learning model is likely to improve for aggregate sampling. However, it is not compulsory for the other strategies — simple and overlapped where certain deviations may be visible.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

