


")
A quick Introduction to Machine Learning. Part-4 (Final Part)
Last Updated on July 17, 2023 by Editorial Team
Author(s): Abhijith S Babu
Originally published on Towards AI.
In this machine learning series, we have come across various machine learning techniques. In part-3, we saw how decision trees can be used in machine learning. The drawbacks of the ID-3 algorithms were pointed out. In this article, We will go through some more decision tree algorithms to address those drawbacks.
A decision tree algorithm serves the purpose of choosing the best variable to split the dataset and the optimal splitting point. The ID-3 algorithm succeeded in choosing the best variable, but splitting the variable optimally was not possible. If the variable has continuous values, a common approach is to divide the set of values into small groups of equal intervals. Splitting the variables into these large groups is computationally complex. Another problem in machine learning is that the data available to us might not be complete. To handle all these problems, an enhanced form of ID-3 was introduced — the C4.5 algorithm.
C4.5 algorithm
In C4.5, the splitting variable is selected similar to the ID-3 algorithm. In ID-3, we chose the variable with minimum entropy, as it has the least impurity. Once we split the data, the entropy will be less than the total entropy before splitting. That difference is the information that we passed on to the decision tree. This is known as the information gain of that variable.
The total split information of the data can be calculated using the formula.

A variable is chosen in C4.5 based on the gain ratio, that is the ratio of information gain of the variable to the split info of the variable. The variable with the maximum gain ratio is selected as the splitting attribute.
Now that we have chosen the splitting variable, our next task is to split the variable. Categorical variables can be split according to the categories, but how to split continuous variables?
Consider our trip example with a small modification. Instead of whether there is an exam, the data shows the number of days left for the upcoming exam.

Now, find all the distinct values in the variable. Here the variable contains the values 6, 7, 8, and 10. We can now split according to each of these values and find the gain ratio of each split. Choose the value that gave the maximum gain ratio to make the split.
The CART algorithm is another technique used to train decision trees. The algorithm uses the Gini index as a measure of impurity. The Gini index of a variable can be calculated using the formula.
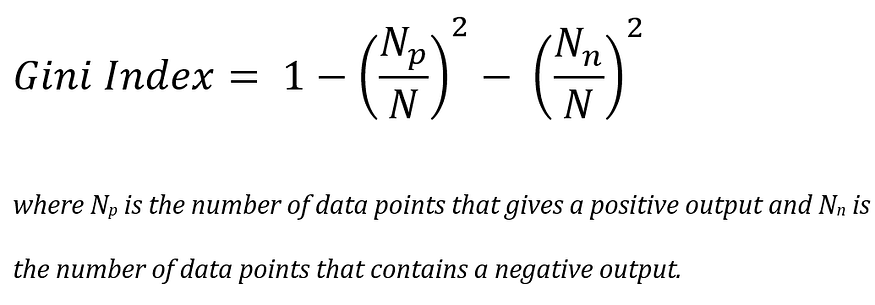
The CART algorithm usually creates a binary tree. The values of categorical values are divided into two groups for splitting. This division is done based on the Gini index of the data. Creating binary decision trees is helpful in easy interpretation and reduces the complexity of testing the data.
By closely examining all the values in a variable, CART can efficiently identify the outliers and imbalances and segregate them into a new sub-tree. Thus this algorithm is useful in dealing with improper data.
Until now, we have seen various techniques in machine learning. As we discussed earlier, the predictions in machine learning will not be 100% accurate. To prevent underfitting, we have to make sure that we use enough data for training. But using a large amount of data for training might lead to overfitting. To address this issue, let us come up with a technique known as regularization. Regularization reduces the overfitting of training data by adding small constraints in the learning process. This makes the machine learning model more generalized.
So far in this series, we have seen a drop in the ocean of machine learning. There are a lot more techniques and theories in machine learning. This series covered the basic topics that will introduce you to the machine learning world. Follow me to read more interesting articles in the field of artificial intelligence. Give your doubts and suggestions in the response and they will be considered in the upcoming parts. Happy reading!!!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

