


A Complete Noobs Guide to Vector Search, Part 1
Last Updated on April 30, 2024 by Editorial Team
Author(s): Harpreet Sahota
Originally published on Towards AI.
If you randomly ended up on this blog, let me give you a bit of context.
I’m writing a book on Retrieval Augmented Generation (RAG) for Wiley Publishing, and vector databases are an inescapable part of building a performant RAG system. I selected Qdrant as the vector database for my book and this series. Over the next several blogs, I’ll teach you everything you need to know to start working with the Qdrant vector database.

Over the last two blogs, I introduced you to vector databases, showed you how to set up your environment, spin up a Qdrant cloud instance, and create your first collection.
Now, it’s time to get practical.
In this post, you’ll gain an intuition for turning real-world text data into vectors and adding them to your Qdrant collection. To follow along with this, you’ll need an OpenAI API Key. OpenAI requires to put some money down upfront. I recommend putting down $20. If you can’t afford that, then Cohere is a good option. Cohere lets you access their models for free without having to enter any credit card information. However, there are rate limits to their free tier. At this time, you can’t send more than 5 requests per minute, 100 requests per hour, and 1000 requests per month.
I primarily use OpenAI because I’ve spent enough time with them to reach their Tier 4 usage limits. This means I can experiment, explore, and hack around as much as I need before committing to something that I’m going to present to you—no other reason than that. You’re free to use whatever language model provider you’d like.
From Text to Vectors
To get the most out of vector search, you must transform human-readable text into a format that machines can understand and process.
The process of going from text to vectors
1. Tokenization: Breaking down the text into smaller units called tokens. Depending on the chosen tokenizer, these can be words, subwords, or even characters.
2. Embedding: Mapping each token to a vector in a high-dimensional space. Each dimension captures some aspect of the token’s meaning and relationship to other tokens.
3. Vector Representation: The resulting set of vectors represents the entire text, capturing its semantic meaning and relationships within the text.
Tokenization

Tokenization involves two main steps:
- Splitting the text into words, subwords, or characters
- Converting each token into a unique integer ID
As of this writing, OpenAI uses a tokenizer called cl100k_base for its new models, including text-embedding-3-large, which will be used in this tutorial. The cl100k_base tokenizer is based on the byte-pair encoding (BPE) algorithm. BPE iteratively replaces the most frequent pair of bytes with a single, unused byte, effectively encoding rare words and subwords.
For words in the English language, tokens are typically single characters, partial, or complete words.
For instance, the sentence “Coding is fun!” would be split into the following tokens: “Coding,” “is,” “fun,” “!”. However, the concept of a token can differ across languages. Depending on the language's structure, some languages might have tokens smaller than a single character or larger than one word. Spaces are usually considered part of the preceding word during tokenization. For example, “learning” would be a token, not “learning “ or “ + learning.” For an excellent deep dive into tokenization, including a comparison of different tokenizers on the same piece of text, I recommend checking out this video by Jay Alammar.
This cool web app also shows you how the `cl100k_base` tokenizer works. Take a look below.
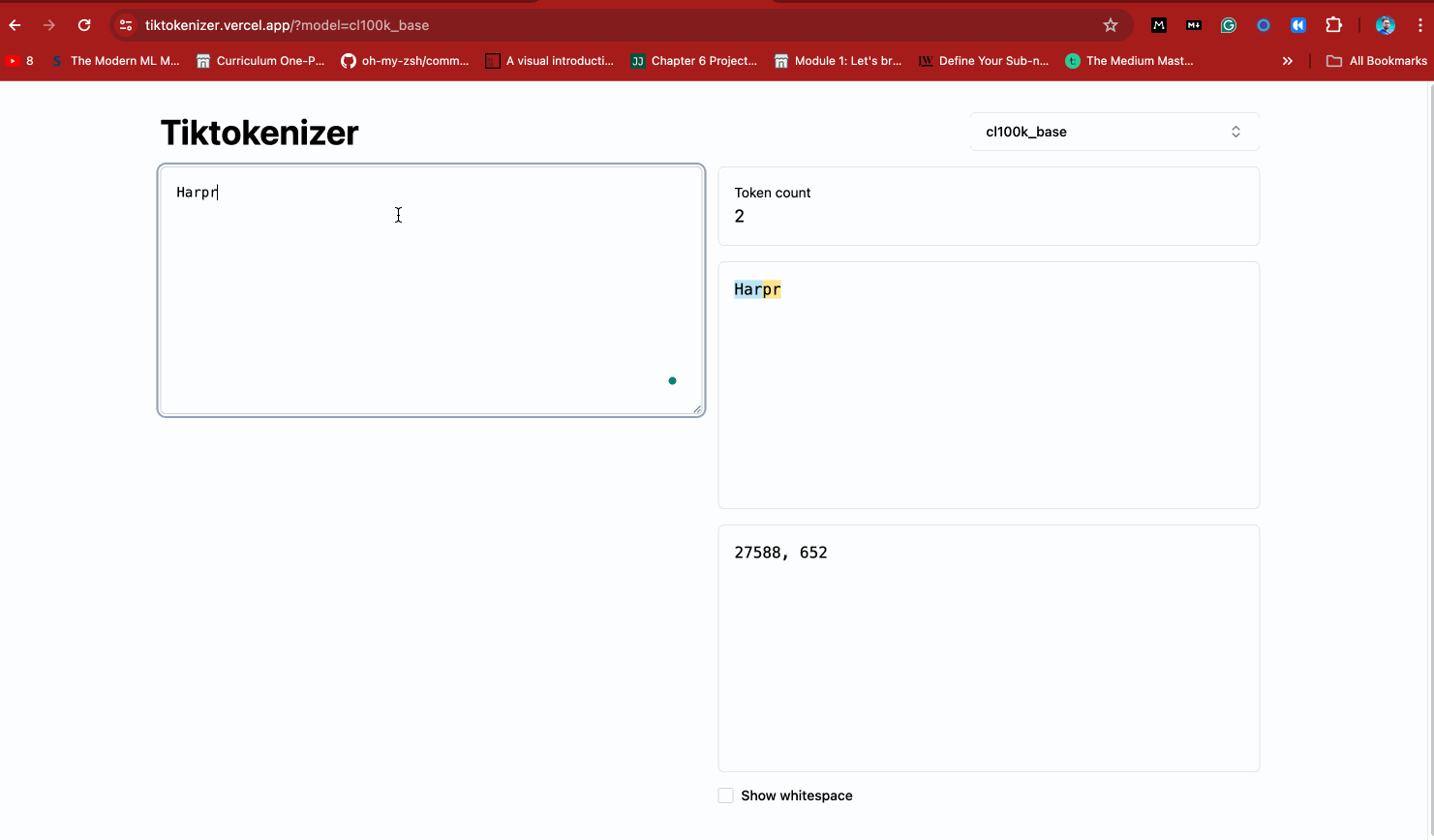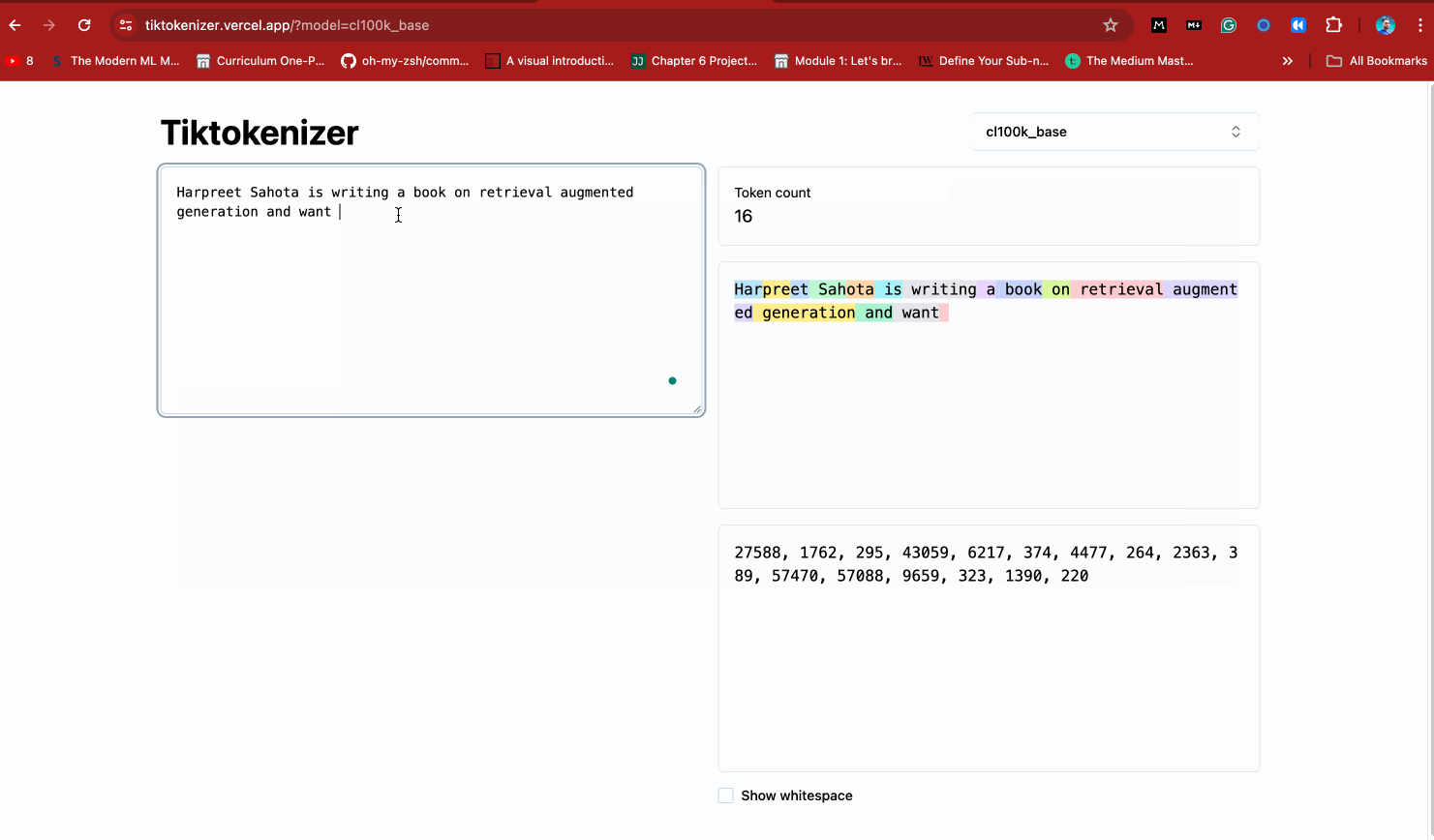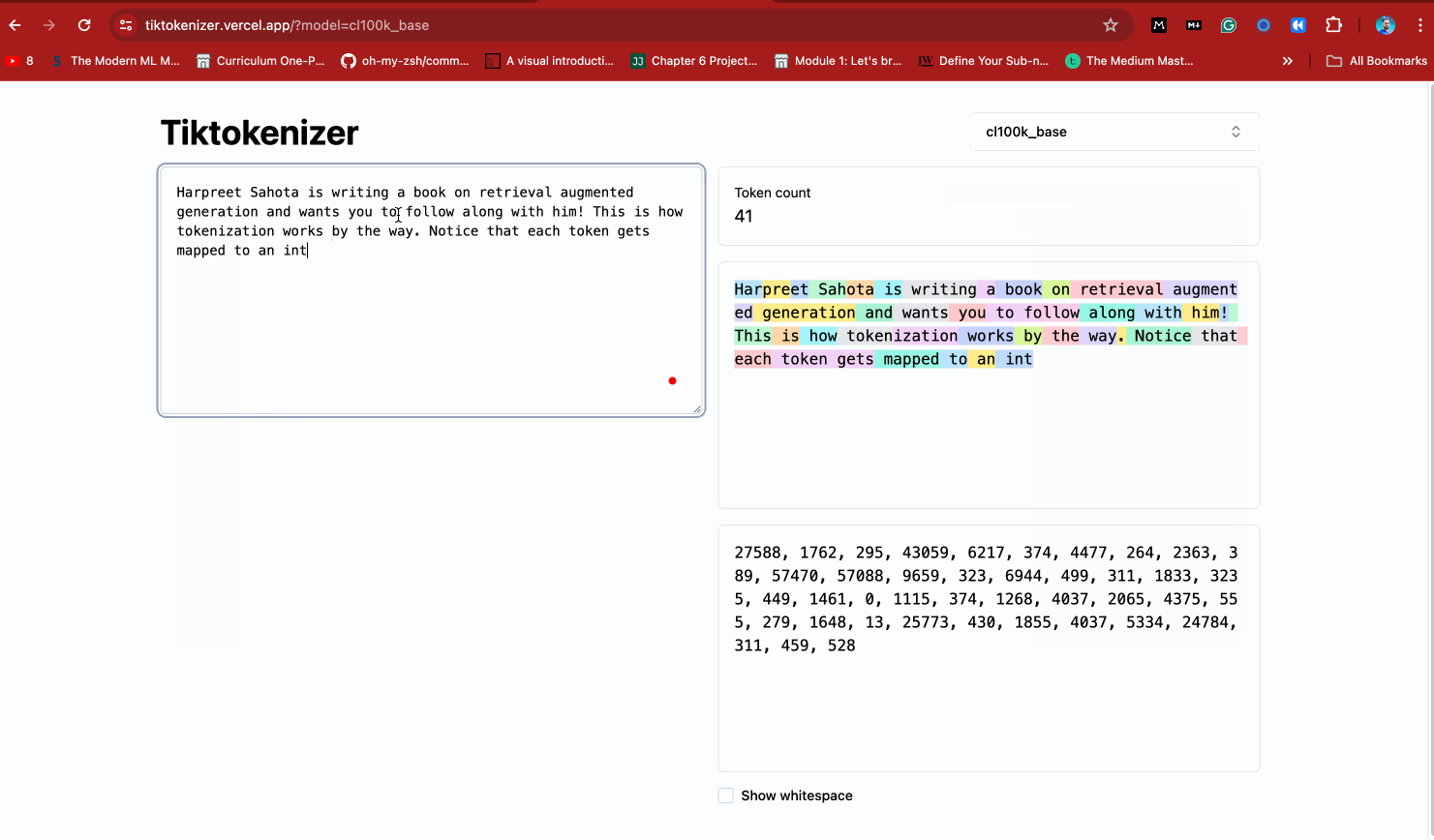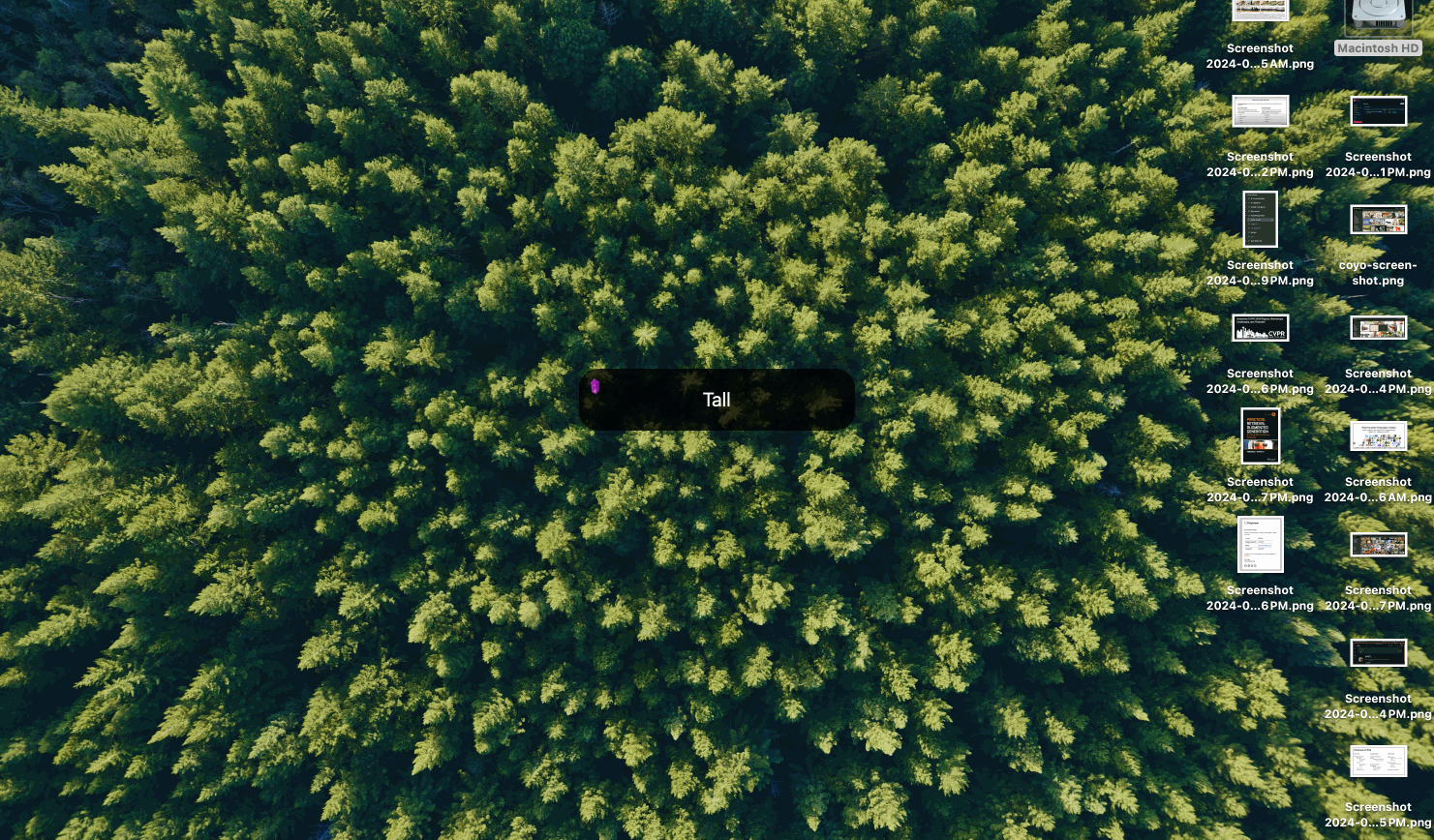
Time to see tokenization in action for yourself. Start by installing tiktoken:
pip install tiktoken==0.6.0
import os
import tiktoken
from dotenv import load_dotenv
load_dotenv("./.env")
example_text = "def hello_world(): print('Hello, world! 🌍') # Bonjour, 世界! Hola, mundo! 1 + 1 = 2, π ≈ 3.14159, e^(i*π) + 1 = 0."
You can count the number of “words” in the string by blank space, and see how this differs from the number of tokens
len(example_text.split())
#23
Now, count the number of tokens.
def num_tokens_from_string(string: str, encoding_name: str = "cl100k_base") -> int:
"""
Calculate the number of tokens in a given text string using a specified encoding.
Args:
string (str): The input text string to be tokenized.
encoding_name (str, optional): The name of the encoding to use for tokenization.
Defaults to "cl100k_base". Other supported encodings include "p50k_base",
"p50k_edit", "r50k_base", etc.
Returns:
int: The number of tokens in the input text string.
Note:
The number of tokens returned by this function depends on the chosen encoding.
Different encodings may have different tokenization rules and vocabulary sizes.
Raises:
ValueError: If an invalid encoding name is provided.
"""
try:
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
except KeyError:
raise ValueError(f"Unsupported encoding: {encoding_name}")
num_tokens_from_string(example_text)
#59
As you can see, that’s quite a difference!
The code below will show you the text, token, and integer representation of each token in the string. I won’t copy and paste the print out here because it will be a lot of text. Run it in your notebook to see for yourself.
def from_text_to_tokens(text:str, encoding_name: str = "cl100k_base" ):
"""
Tokenize the given text using the cl100k_base encoding.
Args:
text (str): The input text to be tokenized.
Returns:
None
"""
encoding = tiktoken.get_encoding(encoding_name)
tokens = encoding.encode(text)
subwords = [encoding.decode([token]) for token in tokens]
print(f"Original text: {text}")
print(f"\nTokens: {tokens}")
print(f"\nSubwords: {subwords}")
print("\nToken to subword mapping:")
for token, subword in zip(tokens, subwords):
print(f"Token: {token}, Subword: {subword.encode('utf-8')}")
from_text_to_tokens(example_text)
I encourage you to play around with it if you’d like!
more_example_text = "Harpreet Sahota is writing a book RAG and is so happy you're joining him on the journey!"
from_text_to_tokens(more_example_text)
When a large language model (LLM) is pretrained or fine-tuned, each token is mapped to a vector representation called a token embedding.
Imagine each token being plotted as a point in a high-dimensional space, where its location and direction reflect its meaning. These embeddings capture the semantic meaning of each token and its relationship to other tokens. This is especially useful for the attention mechanism in the Transformer architecture that modern LLMs use.

For retrieval, you’re not interested in retrieving individual tokens.
You want to retrieve chunks of text, meaning an entire sequence of tokens must be represented as a vector. We don’t have access to the source code for text-embedding-3-large, but in general, the process of going from embedding a token to embedding a sequence of tokens is as follows:
Pooling
After obtaining the token embeddings for the input text, a pooling operation is applied to combine them into a single vector representation.
Common pooling methods include:
- Average pooling: Taking the element-wise average of the token embeddings.
- Max pooling: Taking the element-wise maximum of the token embeddings.
- Last token pooling: Using the embedding of the last token as the representative vector.
Normalization
After obtaining the pooled embedding vector, it is typically normalized to have a unit length. Normalization ensures that the embeddings are scale-invariant and can be compared using some similarity metric. L2 normalization (also known as Euclidean normalization) is commonly used, where each vector element is divided by the vector's Euclidean norm (square root of the sum of squared elements).
Output
The text embedding model's final output is a dense vector of floating-point numbers representing the input text.
The dimensionality of the output vector can vary depending on the specific model and configuration. For the text-embedding-3-large model, the output vector defaults to 3072. However, you can change the dimensionality by fiddling with the dimensions parameter. Note there’s always a trade-off in performance for a more compact representation.
from openai import OpenAI
openai_client = OpenAI()
def get_text_embedding(text: str, openai_client: OpenAI= openai_client, model: str = "text-embedding-3-large") -> list:
"""
Get the vector representation of the input text using the specified OpenAI embedding model.
Args:
openai_client (OpenAI): An instance of the OpenAI client.
text (str): The input text to be embedded.
model (str, optional): The name of the OpenAI embedding model to use. Defaults to "text-embedding-3-large".
Returns:
list: The vector representation of the input text as a list of floats.
Raises:
OpenAIError: If an error occurs during the API call.
"""
try:
embedding = openai_client.embeddings.create(
input=text,
model=model
).data[0].embedding
return embedding
except openai_client.OpenAIError as e:
raise e
You can confirm the length of the embedding.
print(f"This string has {num_tokens_from_string(example_text)} tokens")
vector = get_text_embedding(example_text)
print(f"The vector representation of the text has: {len(vector)} elements")
# This string has 59 tokens
# The vector representation of the text has: 3072 elements
You can inspect the first few elements of the vector as well:
vector[:10]
It doesn’t matter how many tokens the input text has, it will still have the same dimensionality as a vector representation (as long as you’re embedding it with the same model).
print(f"This string has {num_tokens_from_string(more_example_text)} tokens")
vector = get_text_embedding(more_example_text)
print(f"The vector representation of the text has: {len(vector)} elements")
# This string has 23 tokens
# The vector representation of the text has: 3072 elements
This is important because, as was discussed in the previous post, all vectors in our collection must have the same dimensionality.
Let’s download a dataset from Hugging Face and add it to our collection. We’ll use the ai-arxiv-chunked dataset because it’s nicely chunked already and has some columns that will serve well as metadata. This dataset has 41.6k rows and is 153 MB large. For demonstration, time, and keeping your OpenAI bill as low as possible, just randomly sample 100 rows from the dataset.
from datasets import load_dataset
arxiv_chunked_dataset = load_dataset("jamescalam/ai-arxiv-chunked", split="train")
sampled_dataset = arxiv_chunked_dataset.shuffle(seed=51).select(range(100)).to_list()
You can take a peek at a row of the dataset like so:
sampled_dataset[0]
# output
{'doi': '2210.02406',
'chunk-id': '4',
'chunk': 'Figure 1: While standard approaches only provide labeled examples (shown as a grey input box\nwith green label box), Chain-of-Thought prompting also describes the reasoning steps to arrive at\nthe answer for every example in the prompt. Decomposed Prompting, on the other hand, uses the\ndecomposer prompt to only describe the procedure to solve the complex tasks using certain subtasks. Each sub-task, indicated here with A, B and C is handled by sub-task specific handlers which\ncan vary from a standard prompt (sub-task A), a further decomposed prompt (sub-task B) or a\nsymbolic function such as retrieval (sub-task C)\nprompt only describes a sequence of sub-tasks (A, B, and C) needed to solve the complex tasks, indicated with the dashed lines. Each sub-task is then delegated to the corresponding sub-task handler\nshown on the right.\nUsing a software engineering analogy, the decomposer defines the top-level program for the complex task using interfaces to simpler, sub-task functions. The sub-task handlers serve as modular,\ndebuggable, and upgradable implementations of these simpler functions, akin to a software library.\nIf a particular sub-task handler, say the one for identifying the kthletter or retrieving a document,',
'id': '2210.02406',
'title': 'Decomposed Prompting: A Modular Approach for Solving Complex Tasks',
'summary': 'Few-shot prompting is a surprisingly powerful way to use Large Language\nModels (LLMs) to solve various tasks. However, this approach struggles as the\ntask complexity increases or when the individual reasoning steps of the task\nthemselves are hard to learn, especially when embedded in more complex tasks.\nTo address this, we propose Decomposed Prompting, a new approach to solve\ncomplex tasks by decomposing them (via prompting) into simpler sub-tasks that\ncan be delegated to a library of prompting-based LLMs dedicated to these\nsub-tasks. This modular structure allows each prompt to be optimized for its\nspecific sub-task, further decomposed if necessary, and even easily replaced\nwith more effective prompts, trained models, or symbolic functions if desired.\nWe show that the flexibility and modularity of Decomposed Prompting allows it\nto outperform prior work on few-shot prompting using GPT3. On symbolic\nreasoning tasks, we can further decompose sub-tasks that are hard for LLMs into\neven simpler solvable sub-tasks. When the complexity comes from the input\nlength, we can recursively decompose the task into the same task but with\nsmaller inputs. We also evaluate our approach on textual multi-step reasoning\ntasks: on long-context multi-hop QA task, we can more effectively teach the\nsub-tasks via our separate sub-tasks prompts; and on open-domain multi-hop QA,\nwe can incorporate a symbolic information retrieval within our decomposition\nframework, leading to improved performance on both tasks. Datasets, Code and\nPrompts available at https://github.com/allenai/DecomP.',
'source': 'http://arxiv.org/pdf/2210.02406',
'authors': ['Tushar Khot',
'Harsh Trivedi',
'Matthew Finlayson',
'Yao Fu',
'Kyle Richardson',
'Peter Clark',
'Ashish Sabharwal'],
'categories': ['cs.CL'],
'comment': "ICLR'23 Camera Ready",
'journal_ref': None,
'primary_category': 'cs.CL',
'published': '20221005',
'updated': '20230411',
'references': [{'id': '2210.03350'},
{'id': '2207.10342'},
{'id': '2205.12255'},
{'id': '2210.02406'},
{'id': '2204.02311'},
{'id': '2110.14168'},
{'id': '2204.10019'}]}
How to Embed and Upsert Data into Qdrant
Time to get this data into Qdrant. Start by instantiating the client and updating the collection so it’s ready for the vectors we will give it. Recall that, over the next few blogs, you’ll work exclusively with text data. I’ll use OpenAI’s text-embedding-3-large embedding model, which has a default dimensionality of 3072. I’ll also use cosine similarity as the distance metric. This information will go into the vectors config in create_collection.
from qdrant_client import QdrantClient, AsyncQdrantClient
from qdrant_client.models import Distance, VectorParams
from qdrant_client.http.models import CollectionStatus, UpdateStatus
q_client = QdrantClient(
url=os.getenv('QDRANT_URL'),
api_key=os.getenv('QDRANT_API_KEY')
)
q_client.create_collection(
collection_name="arxiv_chunks",
vectors_config={
"chunk": VectorParams(size=3072, distance=Distance.COSINE),
"summary": VectorParams(size=3072, distance=Distance.COSINE),
}
)
As discussed in the previous post, Points are the main data structure (for lack of a better word) that Qdrant uses to store and retrieve data.
These are defined by some vector embedding and any additional metadata you want to include.
The add_data_to_collection function takes a list of dictionaries as input, where each dictionary represents a document to be inserted into the Qdrant vector database. The function iterates over each dictionary in the list and performs the following steps:
- Extracts the key-value pairs from the dictionary, including summary, chunk, title, source, and authors.
- Converts the summary and chunk texts into vector embeddings using the OpenAI embeddings endpoint.
- Generates a unique ID for each document using the uuid module.
- Creates a payload dictionary containing the title, source, and authors metadata.
- Constructs a PointStruct object using the generated ID, the concatenated summary and chunk vectors, and the payload metadata.
- Appends the `PointStruct` object to the points list.
- After processing all the documents, the function uses the client.upsert method to insert the points list into the specified Qdrant collection. The wait parameter is set to True to ensure the insertion operation is completed before proceeding.
- Finally, the function checks the status of the insertion operation. If the status is UpdateStatus.COMPLETED, it prints a success message. Otherwise, it prints a failure message.
The `PointStruct` objects are the fundamental data storage units in Qdrant.
It encapsulates the vector embeddings along with any associated metadata. This enables efficient retrieval and similarity search operations. By converting the `summary` and `chunk` texts into vector embeddings and storing them along with the relevant metadata, you can insert the data into the Qdrant vector database for retrieval tasks.
from typing import List
import uuid
from qdrant_client.models import PointStruct
def add_data_to_collection(data: List[dict], qdrant_client: QdrantClient = q_client, collection_name: str = "arxiv_chunks"):
"""
Inserts data into the Qdrant vector database.
Args:
data (List[dict]): A list of dictionaries containing the data to be inserted.
Each dictionary should have the following keys:
- 'summary': The summary text to be converted into a vector embedding.
- 'chunk': The chunk text to be converted into a vector embedding.
- 'title': The title of the document.
- 'source': The source URL of the document.
- 'authors': A list of authors of the document.
qdrant_client (QdrantClient): An instance of the QdrantClient. Defaults to qdrant_client.
collection_name (str): The name of the collection in which to insert the data. Defaults to "arxiv_chunks".
Returns:
None
"""
# instantiate an empty list for the points
points = []
# get the relevent data from the input dictionary
for item in data:
text_id = str(uuid.uuid4())
summary = item.get("summary")
chunk = item.get("chunk")
title = item.get("title")
source = item.get("source")
authors = item.get("authors")
# get the vector embeddings for the summary and chunk
summary_vector = get_text_embedding(summary)
chunk_vector = get_text_embedding(chunk)
# create a dictionary with the vector embeddings
vector_dict = {"summary": summary_vector, "chunk": chunk_vector}
# create a dictionary with the payload data
payload = {
"text_id":text_id
"title": title,
"source": source,
"authors": authors,
"chunk": chunk,
"summary": summary,
}
# create a PointStruct object and append it to the list of points
point = PointStruct(id=text_id, vector=vector_dict, payload=payload)
points.append(point)
operation_info = qdrant_client.upsert(
collection_name=collection_name,
wait=True,
points=points)
if operation_info.status == UpdateStatus.COMPLETED:
print("Data inserted successfully!")
else:
print("Failed to insert data")
add_data_to_collection(sampled_dataset)
You can verify that the collection exists via the UI and programmatically. Notice that you can do some visualization via the UI as well.

To verify it programmatically:
q_client.get_collections()
# CollectionsResponse(collections=[CollectionDescription(name='arxiv_chunks')])
You can programmatically verify the number of points that were created as well.
arxiv_collection = q_client.get_collection("arxiv_chunks")
print(f"This collection has {arxiv_collection.points_count} points")
Go ahead and close the connection to the client.
q_client.close()
That’s it for this one!
In the next blog in this series, I’ll teach you the basics of indexing and querying the vectors in your collection.
After that blog, you’ll have a solid foundation on which to build as we start doing some more interesting things, like learning the difference between sparse and dense vectors, various types of optimizations we can make with our Qdrant collections, and eventually work our way towards multimodal and crossmodal retrieval!
Be sure to keep in touch.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

