



Volga — Open-source Feature Engine For Real-time AI — Part 1
Last Updated on April 7, 2024 by Editorial Team
Author(s): Andrey Novitskiy
Originally published on Towards AI.
This is the first part of a 2-post series describing the background and motivation behind Volga. For technical details, see the second part.
TL;DR
Volga is an open-source, self-serve, scalable data/feature calculation engine tailored for modern real-time AI/ML applications. It features convenient Pandas-like API to define data entities, online/offline pipelines and sources, consistent online+offline feature calculation semantics, configurable hot and cold storage, feature lookups, real-time serving and on-demand request-time calculations.
It is built on top of Ray and aims to be a completely standalone and self-serve system removing any heavy-weight dependency on general data processors (Flink, Spark) or cloud-based feature platforms (Tecton.ai, Fennel.ai) and can be run on a laptop or on a 1000-node cluster.
GitHub — https://github.com/anovv/volga
Content:
- Real-time ML background and infra challenges
- The rise of Feature Stores
- 3 Types of Features by latency and Computation Engine(s) requirements
- The rise of managed Feature Platforms
- The Problem
- Introducing Volga
Real-time ML background and infra challenges
While the topic of real-time machine learning is pretty vast and is a matter of a separate book, the goal of this article is to give our reader a minimal understanding of infrastructure challenges in this area and demonstrate the problem we are trying to solve (if a reader wants to have a deeper understanding of the subject, Chip Huyen’s blog and Fennel.ai blog are good places to start).
In short, real-time ML is a concept of:
(1) — using streaming (real-time) data to calculate ML model inputs (features) with higher accuracy, lower latency as soon as data arrives, instantly infer results from ML model and
(2) — adapting ML model to changing conditions (data drift, concept drift) via model retraining, online learning, incremental learning.
Our problem space is (1).
Example use cases for real-time ML systems are fraud detection, anomaly/outlier detection, recommendation systems, search personalization, RAG (Retrieval-Augmented Generation) for LLMs, trading systems in financial markets, etc.
While building production-ready real-time ML systems is not an easy task, many practitioners agree that the main challenge of building a complete end-to-end solution is creating and maintaining a robust feature engineering/calculation/storage pipeline. To better understand all nuances of building feature calculation pipelines for real-time ML, you can read these blog posts by Fennel and Chip Huyen. In short, key requirements for a mature production-ready feature calculation system are:
- Have feature metadata storage to ensure consistency in sharing and authoring (feature schema/data type, unique name/id, authors/owners, etc.)
- Different feature access latency requirements for inference and offline training require different storages: hot (cache, e.g. Redis, Cassandra, RocksDB) and cold (offline, e.g. SQL dbs, data lakes)
- Ability to compute features in real-time for online (inference) and offline (training) setting
- Consistency between online and offline feature definitions (same code to define online and offline calculation) and calculation semantics (same result when computed on real-time data and on historical data)
- Data-scientist-friendly API (preferably Python)
- Typical platform requirements: Scalability, Multitenancy support, fault tolerance, etc.
The Rise of Feature Stores
The first iteration to solve these problems was the introduction of Feature Stores. At the time these systems were being introduced, one of the biggest hurdles in ML engineering was the lack of feature standartization — many teams defining custom Python scripts, pieces of Pandas/Spark functions without a centralized data-model and storage lead to bugs and slow development cycle.
A Feature Store is essentially a storage layer providing consistent feature metadata models (schemas, data types, unique ids/names, owners, ranges, lineage) as well as connectors to hot (Redis) and cold (SQL, data lakes) storages and computation engines. Notable example of a feature store is Feast.
While they have found their adoption among users, Feature Stores solved only the first two problems from the above list. Problems regarding managing the compute layer and computation models were still up to the user to solve. You can read more about the differences between Feature Store and Feature Platform at Feast FAQ (https://feast.dev/).
3 Types of Features by Latency and Computation Engine(s) Requirements
To better understand the requirements for a compute layer of a feature platform, let’s look at different feature types based on how they are used and their latency demands. In most current Feature Platforms, there are 3 different types:
Offline Features (other names — Batch, Backfill)
- Calculated offline on historical data, used for model training/validation
- Example — the average number of purchases a user made in a week, timestamped on each new purchase, recorded for each purchase in a span of the last year.
- Latency requirements are dictated by model training process — minutes to days.
- Compute Infra — Spark, Bounded Flink streams in some cases, custom engines
Online Features (other names — Streaming, Near Real-time, sometimes referred as Real-time)
- Calculated as soon as new data entry arrives, used for model inference.
- Example — same as above, but calculated at a specific timestamp received by the system
- Latency — milliseconds to seconds
- Compute Infra — Flink, Spark Streaming, custom streaming engines
On-Demand Features (other names — Real-time)
- Stateless transformations calculated at inference time, used in cases when the calculation is too resource-expensive for streaming or requires data available only at inference time
- Examples — call to a third party service (e.g. GPS tracking), query to a meta-model whose outputs are used as inputs for this model, dot product for large embeddings, user’s age at millisecond precision
- Latency — milliseconds
- Compute Infra — Fleet of Python workers — Celery or custom
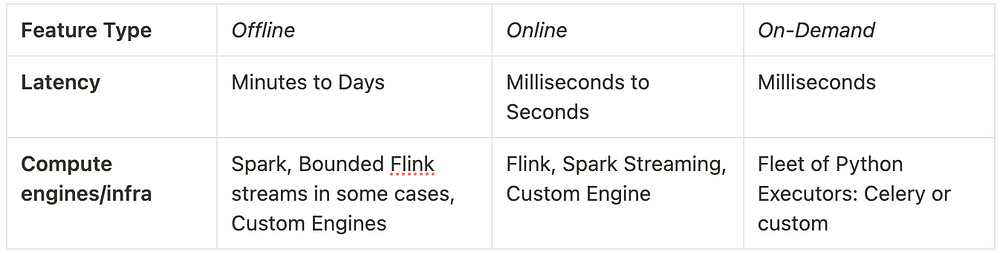
As seen from the above, in order to support the whole spectre of feature types the system needs to rely on 2–3 different compute engines and provide a common computation model as well as cross-language (e.g. Flink uses Java API) user-facing interface, data model and API to ensure feature declaration consistency between all feature types and proper computation model to ensure consistency between streaming and batch features.
While possible, it becomes significantly challenging to orchestrate these compute engines in a platform setting, when a single job needs to synchronize scalability requirements, resource isolation, fault tolerance between Spark, Flink and Python Executor Fleet. Building and maintaining such a system requires a dedicated team of engineers and ops and infeasible for most medium sized engineering teams.
The rise of managed Feature Platforms
To solve challenges above, managed Feature Platforms were introduced. In a nutshell, A Feature Platform = Feature Store + Feature Computation Engine(s), where Feature Computation Engine(s) is a combination of different compute engines mentioned above (open-source or in-house), orchestrated together, platformized and served as a PaaS. Notable examples of such platforms are Tecton.ai and Fennel.ai.
From a user perspective, the biggest and obvious problem with managed Feature Platforms is vendor lock-in — they are based on closed-source infra, hard-coded data models, tied to a specific cloud vendor and pricing plan.
The Problem
In the current state of things, if a user wants to set up a real-time feature computation infra, they have the following choices:
- Outsource to an existing managed Feature Platform which leads to a vendor lock-in (Tecton.ai, Fennel.ai, FeatureForm, Chalk.ai, etc.)
- Build in-house infra using existing Feature Stores that rely on multiple compute engines + build an API and computation model across different languages (Java + Python) to unify online+offline pipelines, build unified orchestration layer. Extremely high development and operational cost, especially in platform scenarios (synchronizing Spark + Flink job scaling, isolation and fault-tolerance in a multitenant setting is a hell of a task).
- Some cloud providers allow on-premise setup (e.g. Fennel) which is a combination of two above — maintenance of in-house closed source infra and provider’s cloud resources + vendor lock-in to provider’s cloud of choice (e.g. AWS in Fennel’s Deployment Model)
As a result, there are currently no open-source, self-serve feature calculation engines that provide single, unified, consistent computation layer for all feature types and solve all of the above needs (online/offline consistency, single computation platform, ease of scalability and multitenancy, cloud-agnostic, easy local prototyping, mature cloud integration).
Introducing Volga
Volga is designed to solve the problems above. It aims to provide a single computation layer for all feature types as well as simple and unified user facing API to define online/offline/on-demand pipelines in a consistent manner along with an ease of experimentation, deployment and maintenance.
Volga is built on top of Ray — a powerful distributed runtime that has deep and mature integration with modern cluster managers: native Kuberenetes with KubeRay, native AWS support on bare EC2 instances or fully-managed solution — Anyscale, easy local setup, developer-friendly Python API, large and mature community as well as AI first ecosystem that can be used to build end-to-end real-time ML platform.
Volga’s heart is it’s custom streaming engine built with Ray Actors, ZeroMQ for messaging and some Rust for perf-critical parts.
Volga’s API is inspired by Fennel and lets users define strongly-typed data schemas, online/offline/on-demand pipelines, sources and transformations.
Features:
- Utilizes custom scalable stream processing engine using Ray Actors for execution, ZeroMQ for messaging and Rust for some perf-critical parts (exeprimental). Kappa architecture — no Flink or Spark
- Built on top of Ray — Easily integrates with Ray ecosystem (cluster/job/cloud management, model training/serving, zero-copy data transfers, etc.) as well as your custom ML infrastructure
- Kubernetes ready, no vendor lock-in — use KubeRay to run multitenant scalable jobs or create your own deployment/scheduling logic in pure Python
- Pure Python, no heavy JVM setups — minimal setup and maintenance efforts in production
- Standalone and self-serve — launch on your laptop or a cluster with no heavy-weight external dependencies
- Cold + Hot storage model allows for customizable offline storage and caches, fast real-time feature queries
- Easy to use declarative Pandas-like API to simultaneously define online and offline feature pipelines, including operators like
transform,filter,join,groupby/aggregate,drop, etc. - [Experimental] Perform heavy embedding dot products, query meta-models or simply calculate users age in milliseconds at request time using On-Demand Features
The second part of the series dives into Volga’s architecture, API design and other technical details.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

