



Inside AVIS: Google’s New Visual Information Seeling LLM
Last Updated on August 22, 2023 by Editorial Team
Author(s): Jesus Rodriguez
Originally published on Towards AI.
The new model combines LLMs with web search, computer vision, and image search to achieve remarkable results.
I recently started an AI-focused educational newsletter, that already has over 160,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence U+007C Jesus Rodriguez U+007C Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
Multimodality is one of the hottest areas of research in foundation models. Despite the astonishing progress shown by models such as GPT-4 in multimodal scenarios, there are plenty of challenges that remain open in this area. One of those areas is visual information-seeking tasks where external knowledge is required to answer a specific question.
In the paper titled “Autonomous Visual Information Seeking with Large Language Models (LLMs)”, Google Research introduced a novel approach is introduced that attains interesting outcomes in tasks related to seeking visual information. The method integrates LLMs with three distinct categories of tools:
1) Computer vision tools are employed to extract visual data from images.
2) A web search tool is utilized to retrieve information from the broader realm of open-world knowledge and facts.
3) An image search tool is harnessed to extract pertinent details from metadata linked to visually akin images.
The combination of the three results in a technique that involves an LLM-driven planner to determine the suitable tools and queries for each step. Furthermore, an LLM-powered reasoner is employed to scrutinize the outputs of the tools and extract essential insights. Throughout the process, a functional memory module retains and preserves information.
Some Background
The ideas behind Google’s AVIS have their roots in recent areas of research. Recent explorations, such as Chameleon, ViperGPT, and MM-ReAct, have focused on enhancing LLMs with supplementary tools for multimodal inputs. These systems operate in two stages: planning, which involves deconstructing questions into structured instructions, and execution, wherein tools are employed to amass information. While this approach has exhibited success in rudimentary tasks, it often falters when confronted with intricate real-world scenarios.
A growing interest has also been observed in utilizing LLMs as self-governing agents, as seen in WebGPT and ReAct. These agents interact with their environment, acclimatize based on real-time feedback, and accomplish objectives. However, these methodologies do not impose limitations on the assortment of tools that can be invoked at various stages, resulting in an extensive search space. Consequently, even the most advanced LLMs can succumb to infinite loops or propagate errors. The AVIS method addresses this issue through guided LLM application, influenced by human decisions drawn from a user study.
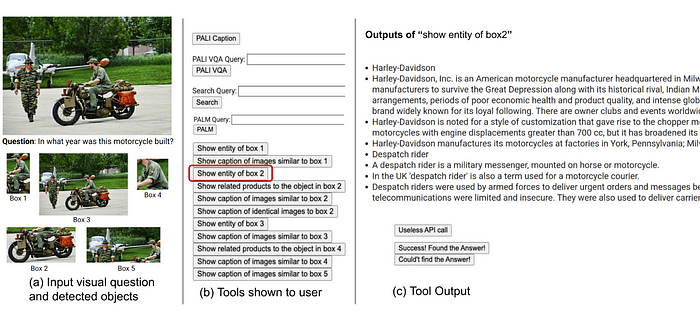
Numerous visual queries within datasets like Infoseek and OK-VQA pose challenges even for human responders, often necessitating the aid of diverse tools and APIs. To gain an understanding of human decision-making when employing external tools, a user study was conducted.
Participants were equipped with an identical set of tools as utilized in the AVIS method, including PALI, PaLM, and web search. They received input images, questions, cropped object images, and buttons linking to image search findings. These buttons provided assorted information about the cropped object images, such as entities within knowledge graphs, similar image captions, correlated product titles, and identical image descriptions.
User actions and outputs were recorded and employed as a reference for the AVIS system in two significant ways. Primarily, a transition graph was constructed by analyzing the sequence of decisions made by users. This graph delineates discrete states and confines the available range of actions within each state. For instance, at the initial state, the system is limited to three actions: PALI caption, PALI VQA, or object detection. Secondly, examples of human decision-making were leveraged to steer the planner and reasoner within the AVIS system, imbuing them with pertinent contextual instances to heighten performance and efficacy.
Inside AVIS
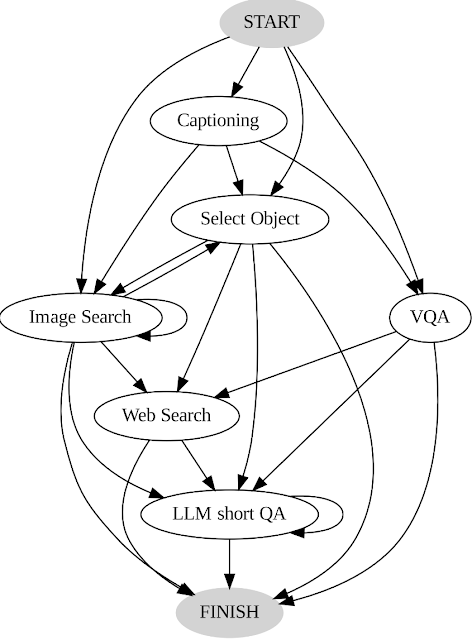
In AVIS, Google Research adopts a dynamic approach to decision-making specially tailored for addressing queries involving the quest for visual information. The methodology consists of three fundamental components within the system’s architecture.
1) Initially, a planner takes the helm, deciphering the subsequent course of action, encompassing the appropriate API invocation and the corresponding query for processing.
2) Alongside, a working memory module is in place, diligently preserving data regarding outcomes stemming from API executions.
3) Lastly, a reasoner assumes a pivotal role by sifting through the results generated from API calls. This role encompasses assessing whether the acquired information holds enough merit to furnish a definitive response or if further data retrieval is imperative.

The planner embarks on a sequence of steps whenever a verdict is to be rendered concerning the selection of tools and the corresponding queries to dispatch. Tailored to the current state, the planner unfolds an array of possible ensuing actions. The breadth of potential actions can become unwieldy, posing challenges in the search space. To tackle this quandary, the planner references a transition graph, expelling irrelevant actions from consideration. Actions previously executed and enshrined in the working memory are also excluded.
Subsequently, the planner assembles an array of pertinent contextual instances, derived from the judgments earlier rendered by human participants during the user study. Armed with these instances and the reservoir of data encapsulated within the working memory, the planner crafts a prompt. This prompt is then channeled to the LLM, which furnishes a structured response. This output dictates the subsequent tool to activate and the correlated query to dispatch. This blueprint sanctions the planner to be triggered recurrently throughout the process, thereby effectuating dynamic decision-making that progressively navigates toward addressing the initial query.
The reasoner steps into the fray to dissect the outcomes of tool executions. It gleans valuable insights and discerns the category into which the tool output aligns: informative, uninformative, or culminating response. The technique hinges on harnessing the LLM with suitable prompts and contextual instances for the reasoning task. If the reasoner ascertains readiness to yield a response, it duly issues the definitive reply, thereby drawing the task to a close. In instances where the tool output proves barren, the reasoner defers to the planner for the selection of an alternative action, grounded in the extant state. Should the tool output prove insightful, the reasoner orchestrates a state shift and reinstates the planner’s authority, prompting a fresh decision premised on the novel state.
The Results
As expected, Google evaluated AIVS on different visual information-seeking benchmarks such as Infoseek and OK-VQA datasets. The results were incredibly impressive, even achieving over 50% accuracy without fine-tuning.

The AVIS research combines different ideas in a novel framework for visual information-seeking models. Don’t be surprised if we see AVIS incorporated into the new wave of multimodal foundation models released by Google.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

