



AI Systems: Unearthed Bias and the Compelling Quest for True Fairness
Last Updated on August 7, 2023 by Editorial Team
Author(s): João Areias
Originally published on Towards AI.
And how we can prevent the automation of prejudice
Artificial Intelligence (AI) is no longer a futuristic concept — it has become an intrinsic part of our lives. It’s hard to think how Visa would validate 1,700 transactions per second and detect fraud in them without AI assistance or how, out of the nearly 1 billion uploaded videos, Youtube could find the one video that is just right. With its pervasive influence, it is crucial to establish ethical guidelines to ensure the responsible use of AI. For that, we need strict criteria of fairness, reliability, safety, privacy, security, inclusiveness, transparency, and accountability in AI systems. In this article, we will delve deeper into one of these principles, fairness.
Fairness in AI Solutions
Fairness is at the forefront of responsible AI, implying that AI systems must treat all individuals impartially, regardless of their demographics or backgrounds. Data Scientists and ML Engineers must design AI solutions to avoid biases based on age, gender, race, or any other characteristic. Data used to train these models should represent the population’s diversity, preventing inadvertent discrimination or marginalization. Preventing bias seems like an easy job; after all, we are dealing with a computer, and how the heck can a machine be racist?
Algorithmic Bias
AI fairness problems arise from Algorithmic bias, which is systematic errors in the model’s output based on a particular person. Traditional software consists of algorithms, while machine learning models are a combination of algorithms, data, and parameters. It doesn’t matter how good an algorithm is; a model with bad data is bad, and if the data is biased, the model will be biased. We introduce bias in a model in several ways:
Hidden biases
We have biases; there’s no question about that, stereotypes shape our view of the world, and if they leak into the data, they will shape the model’s output. One such example of this occurrence is through language. While English is mainly gender-neutral, and the determiner “the” does not indicate gender, it feels natural to infer gender from “the doctor” or “the nurse.” Natural Language models, such as translation models or Large language models, are particularly vulnerable to that and can have the results skewed if not appropriately treated.
A few years ago, I heard a riddle that went like this. A boy was playing on the playground when he fell and was severely injured; the father took the child to the hospital, but upon arriving, the doctor said, “I cannot operate on this child; he is my son!” How can this be? The riddle was that the doctor was a woman, the child’s mother. Now picture a nurse, a secretary, a teacher, a florist, and a receptionist; were they all women? Surely we know there are male nurses out there, and nothing keeps a man from being a florist, but it is not the first thing we think about. Just as our mind is affected by this bias, so is the machine’s mind.
Today, July 17, 2023, I asked Google Translate to translate some professions from English to Portuguese. Google’s translation of occupations such as teacher, nurse, and seamstress, make use of the Portuguese feminine pronoun “A” indicating the professional is a woman (”A” professora, “A” enfermeira, “A” costureira, “A” secretaria). In contrast, occupations such as professor, doctor, programmer, mathematician, and engineer use the Portuguese masculine pronoun “O” indicating the professional is a man (”O” professor, “O” médico, “O” programador, “O” matemático, “O” engenheiro).

While GPT-4 has made some improvements, and I could not replicate the same behavior with my short quick tests, I did reproduce it in GPT-3.5.

While the examples presented don’t pose much of a threat, it’s easy to think of potentially dire consequences of models with the same technology. Consider a CV analyzer that reads a resume and uses AI to determine if the applicant is suitable for the job. It would undoubtedly be irrational and immoral, and in some places, illegal to disregard the applicant for a programmer position because her name is Jennifer.
Unbalanced classes in training data
Is 90% accuracy good? How about 99% accuracy? If we predict a rare disease that only occurs in 1% of people, a model with 99% accuracy is no better than giving a negative prediction to everyone, completely ignoring the features.
Now, imagine if our model is not detecting diseases but people. By skewing the data toward a group, a model may have issues detecting a misrepresented group or even ignore it entirely. This is what happened to Joy Buolamwini.
In the documentary Coded Bias, MIT computer scientist Joy Buolamwini exposed how many facial recognition systems would not detect her face unless she wore a white mask. The model’s struggles are a clear symptom that the dataset heavily underrepresents some ethnic groups, which is unsurprising, as the datasets used to train these models are highly skewed, as demonstrated by FairFace [1]. The misrepresentation of the group proportions can lead the model to ignore essential features of misrepresented classes.

While FairFace [1] balanced its dataset among the different ethnicities, it’s easy to see that important datasets in the industry, such as LFWA+, CelebA, COCO, IMDM-Wiki, and VGG2 are composed of about 80% to 90% of white people, this is a distribution that is hard to see even in the whitest of countries [2] and, as demonstrated by FairFace [1], can significantly degrade models performance and generalization.
While facial recognition may allow your friend to unlock your iPhone [3], we may face worse consequences from different datasets. The US judicial system systematically targets African Americans [4]. Suppose we create a dataset of arrested people in the US. In that case, we will skew the data toward African Americans, and a model trained on this data may reflect this bias to classify Black Americans as dangerous. This happened to COMPAS, an AI system to create a risk score of a criminal rescind in crime, exposed by ProPublica in 2016 for systematically targeting black people [5].
Data leakage
In 1896, in the case of Plessy vs. Ferguson, the US solidified racial segregation. In the National Housing Act of 1934, the US federal government would only back neighborhood building projects that were explicitly segregated [6]. This is one of the many reasons why race and address are highly correlated.
Consider now an electricity company creating a model to aid bad debt collection. As a data-conscious company, they decided not to include name, gender, or personally identifiable information on their training data and to balance the datasets to avoid bias. They instead aggregate the clients based on their neighborhood. Despite the efforts, the company has also introduced bias.
By using a variable so correlated to race as an address, the model will learn to discriminate against race, as both variables could be interchanged. This is an example of data leakage, where a model indirectly learns to discriminate against undesired features. Navigating a world of systemic prejudice can be challenging; bias will sneak into the data in the most unexpected ways, and we should be overly critical of the variables we include in our model.
Detecting Fairness problems
There is no clear consensus on what fairness means, but there are a few metrics that can help. When designing an ML model to solve a problem, the team must agree on the fairness criteria based on the potential fairness-related issues they may face. Once the criteria are defined, the team should track the appropriate fairness metric during training, testing, validation, and after deployment to detect and address fairness-related problems in the model and address them accordingly. Microsoft offers a great checklist to ensure fairness is prioritized in the project [7]. Consider dividing people into two groups of sensitive attributes A, a group a with some protected attributes, and a group b without those attributes; we may define some fairness metrics as follows:
- Demographic Parity: This metric asks if the probability of a positive prediction for someone from a protected group is the same as for someone from an unprotected group. For example, the likelihood of classifying an insurance claim as fraudulent is the same regardless of the person’s race, gender, or religion. For a given predicted outcome R this metric is defined by:
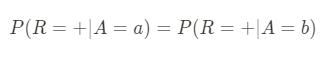
- Predictive Parity: This metric is all about the accuracy of positive predictions. In other words, if our AI system says something will happen, how often does it happen for different groups? For example, suppose a hiring algorithm predicts a candidate will perform well in a job; the proportion of predicted candidates who actually do well should be the same across all demographic groups. If the system is less accurate for one group, it could be unfairly advantaging or disadvantaging them. For a given realized outcome Y we can define this metric as:
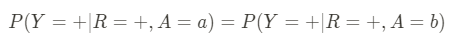
- False Positive Error Rate balance: Also known as equal opportunity, this metric is about the balance of false alarms. If the AI system makes a prediction, how often does it wrongly predict a positive outcome for different groups? For instance, when an admissions office rejects applicants to a university, how often are good suitable candidates rejected in each group? We can define this metric as:
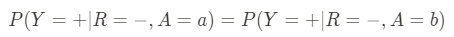
- Equalized odds: This metric is about balancing both true positives and false positives across all groups. For a medical diagnostic tool, for example, the rate of correct diagnoses (true positives) and misdiagnoses (false positives) should be the same regardless of the patient’s gender, race, or other demographic characteristics. In essence, it combines the demands of Predictive Parity and False Positive Error Rate Balance and can be defined as follows:

- Treatment equality: This metric examines the distribution of mistakes across different groups. Are the costs of these mistakes the same for other groups? For instance, in a predictive policing context, if two people — one from a protected group and one from an unprotected group — both don’t commit a crime, they should have the same likelihood of being mistakenly predicted as potential criminals. Given the false positives FP and false negatives FN of a model, this metric can be defined as follows:
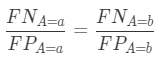
At least in classification problems, computing the fairness criteria can be easily done using a confusion matrix. Still, Microsoft’s fairlearn provides a suite of tools [8] to compute those metrics, preprocess data, and post-process predictions to comply with a fairness constraint.
Addressing fairness
While fairness must be in the mind of every Data Scientist throughout the entirety of the project, we can apply the following practices to avoid problems:
- Data collection and preparation: Ensure your dataset is representative of the diverse demographics you wish to serve. Various techniques can address bias at this stage, such as oversampling, undersampling, or generating synthetic data for underrepresented groups.
- Model design and testing: It is crucial to test the model with various demographic groups to uncover any biases in its predictions. Tools like Microsoft’s Fairlearn can help quantify and mitigate fairness-related harms.
- Post-deployment monitoring: Even after deployment, we should continuously evaluate our model to ensure it remains fair as it encounters new data and establishes feedback loops to allow users to report instances of perceived bias.
For a more complete set of practices, one can refer to the previously mentioned checklist [7].
In conclusion
Making AI fair isn’t easy, but it’s important. It is even harder when we can’t agree on what fair even is. We should ensure everyone is treated equally and no one is discriminated against by our model. This will become harder as AI grows in complexity and presence in daily life.
Our job is to ensure the data is balanced, biases are questioned, and every variable in our model is scrutinized. We must define a fairness criterion and adhere closely to it, being always vigilant, especially after deployment.
AI is a great technology at the foundation of our modern data-driven world, but let’s ensure it is great for all.
References
[1] FairFace: Face Attribute Dataset for Balanced Race, Gender, and Age
[2] https://en.wikipedia.org/wiki/White_people
[3] https://www.mirror.co.uk/tech/apple-accused-racism-after-face-11735152
[4] https://www.healthaffairs.org/doi/10.1377/hlthaff.2021.01394
[5] https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
[6] https://en.wikipedia.org/wiki/Racial_segregation_in_the_United_States
[7] AI Fairness Checklist — Microsoft Research
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

