



Face Off: Practical Face-Swapping with Machine Learning
Author(s): Aliaksei Mikhailiuk
Originally published on Towards AI.
I first laid my hands on the face-swapping at Snap, working on a face swap lens. Diving deep into the subject, I have realized that there is a myriad of technological branches that address various parts of the problem.
While very impressive, face swap technology still requires a huge amount of manual work to be made indistinguishable from the real videos. It also requires computational resources to achieve high-quality results, making it hard for the current methods to operate in real-time at scale.
Below I try to answer the following three questions: What matters for a high-quality face swap method? What has been done in the past? And what to do in practice?
While writing this article I have also found a paper-stack with face-swap papers, you might want to check it out!
What matters?
Generally there two categories into which Face-Swapping methods fall — 3D based, where the method first reconstructs the 3D model of both faces and after that finds a transformation from one face to another; and machine learning based methods, where, given two photos we learn an end-to-end mapping to the face with the transitioned identity of one image and preserved attributes of another.
In this article, I will focus on machine learning methods. 3D methods although with an initial momentum (mainly due to the fact that we didn’t have sufficient resources and knowledge to efficiently train larger neural networks) suffer from lower quality and lower processing speeds.
Going over the papers, I have noticed that the proposed solutions generally try to improve one of the three key aspects: quality, identity, and attribute preservation. Typically, these aspects are covered by either inventing or modifying existing identity and attribute losses, looking for ways to efficiently inject identity information into the attribute encoders, augmenting datasets with diverse images, and introducing the model architecture tweaks to better transfer the features from the attribute image.

Dataset considerations
One of the aspects that each of the methods listed below acknowledges is the need for a diverse dataset with high-quality images of human faces. Ideally a dataset for training face swap methods would contain versatile:
- Facial expressions: raised eyebrows, open/closed mouth, open/closed/squinted eyes and various positions of head pose.
- Facial occlusions: glasses, hair bangs, beards, head covers (these (can be pre-generated or sampled from datasets, for example: egohands, gtea hand2k, ShapeNet).
- Diversity attributes: skin-colours, disabilities, gender, age
Typical datasets used for training and evaluation are: Celeb-HQ, CalebA-HQ, CelebV-HQ, VoxCeleb2, FaceForensics++ and FFHQ. These datasets have a large number of real images; however, they suffer from a limited number of facial expressions and occlusions, and, perhaps unsurprising, they have a large number of celebrities, which look fairly different from a real population sample. However, with various data augmentations, for example, through pasting objects into the image, simulating occlusions, or using synthetic datasets by re-sampling a pre-trained generator for human faces with different pitch, yaw, and expression settings, these datasets could achieve the required quality.
What has been done?
First, we need to agree on terminology. Face-swap methods typically have two inputs: the face that will be used for identity extraction and the face into which the identity is to be posted. In the literature, typically, the names source and target images are used, however, these might be used interchangeably, depending on the article, and to avoid any confusion, I will call the image from which we take the identity as identity image and the one from which we extract attributes, I will call the attribute image.
Without further due, lets jump into the history and present of face swapping!
DeepFaceLab: Integrated, flexible and extensible face-swapping framework, 2018, code

DeepFaceLab is perhaps the most well-known method for face-swapping — back in 2018; it managed to successfully build an easy-to-use pipeline and community around it on encouraging data and checkpoint charing.
The method comes with a big limitation — it can only be tuned for a specific pair of faces and wouldn’t generalize beyond these. The method has two variations (DF) and (LIAE), in the DF variation, identity and attribute mask+image share the same encoder and interconnected (inter) layers and have their own decoders; (ii) LIAE Structure was proposed to tackle the lightning transfer problem share the encoder, but have separate interconnected layers, followed by a shared decoder that takes concatenated features from InterAB and InterB for A and B images respectively.
The method uses several losses, weighted mask SSIM (more on eyes), DSSIM, MSE, and the difference between the features of the idenity and attribute images after inter layer, to make sure that the information about one information is disentangled from the other.
FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping, 2019, code


This work is perhaps the first successful method that didn’t require fine-tuning for pair-specific source and target faces.
The faces are first aligned, and then the target identity is extracted with an identity encoding network. The attribute image is fed through UNet like decoder extracting multiple-res features. The target identity and source features are normalized and blended together.
The method has four losses: identity, adversarial, reconstruction (when source and target are the same), and attribute preservation loss, which penalizes the difference in the source encoder embeddings from the generated and source images. On top of the method, runs a refinement network that ensures that occluded regions in the source image are preserved — without it, parts of the occluded face might experience ghost artifacts.
SimSwap: An Efficient Framework For High Fidelity Face Swapping, 2021, code
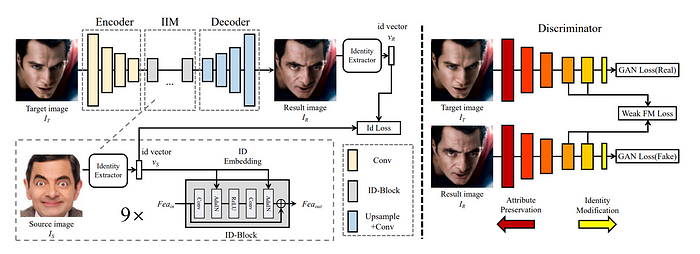
The main idea is to extract source identity feature vector using face recognition neural (arcface) and modulate it into encoded target features (using AdaIN).
The loss then consists of identity loss (cosine between source identity vector and generated identity vector), reconstruction loss (L1 between images, used only if the source and target identities are same), adversarial loss, weak feature matching loss (L1 between several latest discriminator layers for gt vs. generated).
One Shot Face Swapping on Megapixels, 2021, code

While not the first one (the work builds on the paper exploring face swapping through latent space manipulation) the methods attains superior results, taking a different angle to the problem of face-swapping compared to other methods. It looks in exchanging the identity via non-linear latent space manipulation of StyleGan2 via GAN-inversion. Each of the modules in the paper can be trained separately, making fine-tuning on large-scale images feasible in the realm of constrained GPU resources.
The model uses reconstruction, LPIPS for quality preservation, identity and landmark losses.
Smooth-Swap: A Simple Enhancement for Face-Swapping with Smoothness, 2021
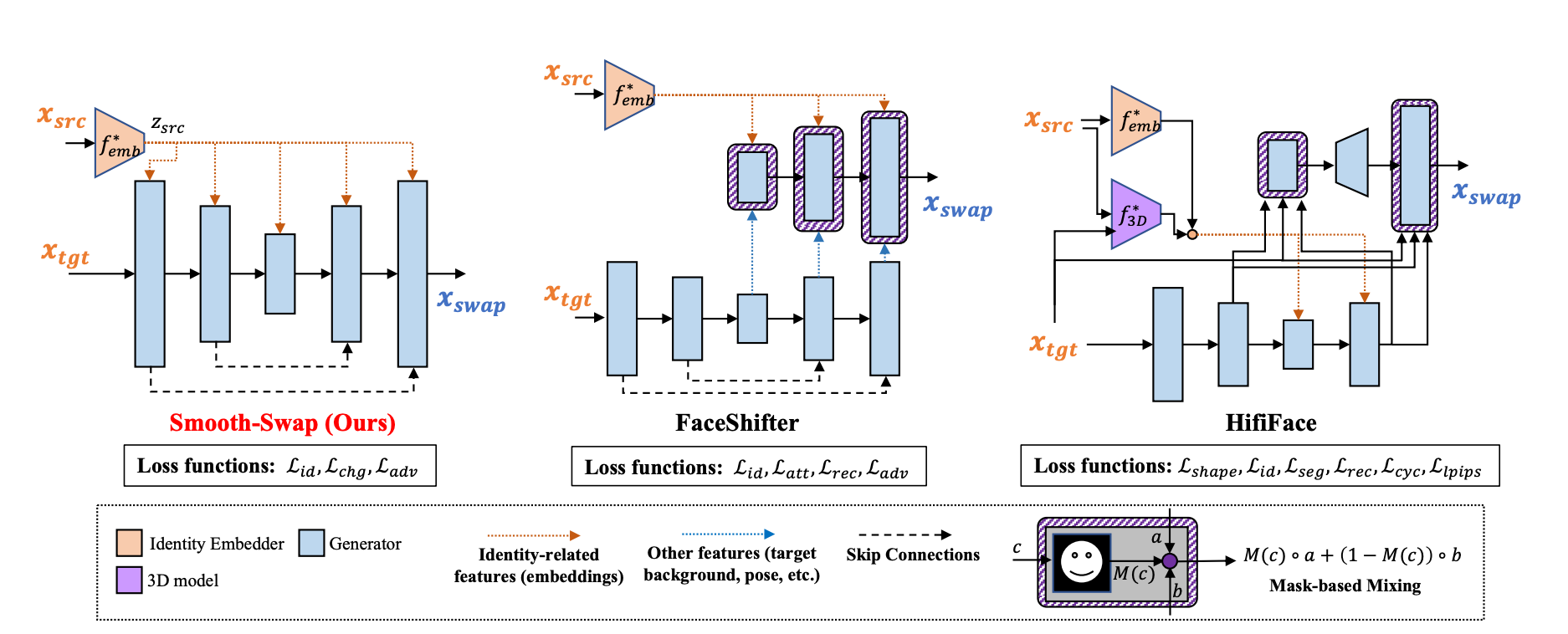

There are two interesting parts to this paper, the first is that it is a much simplified architecture compared to the earlier methods — instead of looking into the intricate ways to merge the features from the identity and attribute images the model directly injects identity embeddings into end-to-end architecture.
The second interesting part is an additional contrastive lost term that smoothes the identity embedding space to ensure that the gradient propagation is quicker and the learning is faster. The rest of the losses are adversarial, identity and reconstruction losses (when the identity is the same in the identity and attribute images).
A new face swap method for image and video domains: a technical report [(Ghost)], 2022, code

The method presents a simplified architecture of FaceShifter. First, and perhaps the most important improvement is that it does not require two models to produce high quality images. Second instead of generating the whole image from scratch, it pastes the generated face into the source image based on the insertion mask. The mask is shrinked or expanded depending on the size of the face and also has blurry edges to make the transition between the pasted and generated images smooth.
The method also presents several modifications to the loss functions — first is that it relaxes the constraint on the reconstruction loss — not requiring the reconstruction loss to be generated from the output where input identity and attribute images are the same, the only requirement is that these represent these have the same identityand add a new eye loss, where eyes appeared to be important for visual perception of human identity.
MobileFaceSwap: A Lightweight Framework for Video Face Swapping, 2022, code

The work proposes a lightweight face-swap method that is supposed to be mobile friendly and focuses on the architectural tweaks that would make it lightweight, for example it uses UNet-like architecture with standard convolutions replaced depth-wise and point-wise convolutions, thus making it lighter and faster.
To inject identity to the inference model employ another network that predicts weights for depth-wise and modulation parameters for point-wise (because latter are heavier) parts. Hence the identity network modifies weights of the main network and then the main network is used for inference. ID-network uses ID vectors from ArcFace.
The work proposes to train the final light-weight network using a teacher model along with GAN and ID-ARCFace losses.
Learning Disentangled Representation for One-shot Progressive Face Swapping, 2022, code

Unlike other methods this work focuses specifically on feature disentanglement — once independent representations are available, these can be mixed and match to transfer the identities from one image to another. The method simultaneously performs two face swaps and two reconstructions from identity and attribute images.
The work trains separate encoders for identity and attributes, as well as their own fusion module that employs landmarks and facial mask to inject identity vector — mask and landmarks are used as direct assumptions on where to insert identity information.
The model employs four losses — reconstruction, identity, adversarial and attribute transfer losses.
Migrating Face Swap to Mobile Devices: A lightweight Framework and A Supervised Training Solution, 2022, code

The work follows the track of building practical face-swapping models for mobile. However, the most interesting part of the paper is data augmentation procedure.
In this work the authors take two pictures with the same identity, transform the one of the face images with with ageing or fatting. Then they train the method to paste the unchanged image into the transformed one and since we still have the untransformed original image that was transformed we have the ground truth for face-swap transformation.
The model has six losses — 3 multi-scale discriminators (the decoder is split into three layer chunks each third from the deep to shallower layers is forced to output a valid reconstruction of the face swapped result at various resolutions), VGG, ID and pixel-wise losses.
High-resolution Face Swapping via Latent Semantics Disentanglement, 2022, code
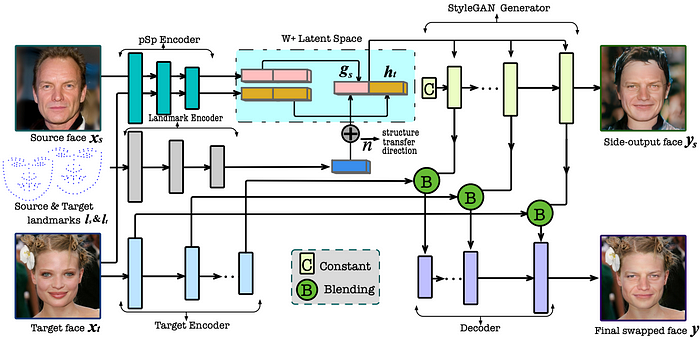
The work continues the stream of the One Shot Face Swapping on Megapixels — looking at manipulating the W+ latent space, however, has many more stages.
The model first construct a side-output swapped face using a StyleGAN generator, by blending the structure attributes of the attribute and the identity faces in the latent space while reusing the appearance attributes of the attribute image. To further transfer the background of the attribute’s face, the model uses an encoder to generate multi-resolution features from the attribute image, and blend them with the corresponding features from the upsampling blocks of the StyleGAN generator. The blended features are fed into a decoder to synthesis the final swapped face image.
The model relies on adversarial, landmark alignment, identity, reconstruction, style-transfer losses.
Region-Aware Face Swapping, 2022

The model has two branches to encode ID features — local (based on facial features, for example, lips, nose, brows, and eyes) and global (to encode global identity-relevant cues for example wrinkles).
Instead of AdaIN to inject local facial features the model uses transformers in the local branch as too much of irrelevant information is entangled in the ID feature and transformer architecture can encode it. The decoder is StyleGAN2 and interestingly instead of using the blending mask pre-computed with landmarks the method predicts it in a separate branch.
Total loss is fairly straight forward: reconstruction (L2), perceptual and ID losses.
FastSwap: A Lightweight One-Stage Framework for Real-Time Face Swapping, 2023, code.

The model consists of three modules: 1) Identity Encoder which extracts the identity feature and provides the skip connections to the generator, 2) Pose Network which extracts pose from target image and decodes the spatial pose feature, and 3) Decoder with TAN Block which effectively integrates the features from 1) and 2) in an adaptive fashion.
The model is trained in a self-supervised manner — both identity and attribute image have the same identity. During the training process both original identity and attribute images have their colour distorted, making the model to put more effort in identifying the right transformation guided by the additional “attribute image” which gives guidance to the lightning and skin color image.
Loss functions include — reconstruction (L2), perceptual, adversarial, ID, and pose losses.
Diffusion based face-swapping
The methods described above are based on CNN-based models that combine several loss functions and are trained in a GAN-like manner. However, in the past two years, we have seen the growth of diffusion models due to their superior quality. Despite the differences in the intrinsic mechanisms for image generation, the overall principle of building a diffusion-based face-swapping method remains the same: encoding the attribute information and guiding the diffusion process with the ID vectors and landmarks.
- DiffFace: Diffusion-based Face Swapping with Facial Guidance, 2022, code
- DiffSwap: High-Fidelity and Controllable Face Swapping via 3D-Aware Masked Diffusion, 2023, code
Evaluation
Each of the three aspects mentioned above: quality, identity, and attribute preservation, needs to be measured, and typically, each of these is measured separately. The following methods can be used to evaluate your method:
- Identity preservation: face-net and compare the identity between the target and generated with cosine similarity
- Artefacts: realism metrics, e.g. FID , however, these are not fine-tuned for human faces
- Source image attributes: comparing facial expression embeddings and eye landmarks for gaze location.
Although these metrics can provide some insights into the performance of the face-swapping methods, running subjective studies is instrumental in making reliable conclusions about the models. Ideally the method should be tested on the videos — photos might be limited in their ability to exhibit artefacts that would otherwise be noticeable in the videos, for example temporal consistency or flickering.
What to do in practice?
Once you are ready to design your own face-swapping app the first step is to see if you can utilise the available solutions. Depending on your needs, either one of the existing solutions would work, or, for example if there tight computational constraints (porting your face-swap model to mobile) you could use the following recipe:
- Prepare a dataset with diverse identity and attribute images;
- Generate swapped identity images with the best method from the literature;
- Distill the dataset to the model that would fit your computational requirements with a supervised training, having paired input — output (swapped identity reference).
Liked the author? Stay connected!
Have I missed anything? Do not hesitate to leave a note, comment or message me directly on LinkedIn or Twitter!
Deep Video Inpainting
Removing unwanted objects from videos with deep neural networks. Problem set up and state-of-the-art review.
towardsdatascience.com
Perceptual Losses for Deep Image Restoration
From mean squared error to GANs — what makes a good perceptual loss function?
towardsdatascience.com
On the edge — deploying deep learning applications on mobile
Techniques on striking the efficiency-accuracy trade-off for deep neural networks on constrained devices
towardsdatascience.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



