



BatchNorm for Transfer Learning
Last Updated on July 24, 2023 by Editorial Team
Author(s): Michal Lukac
Originally published on Towards AI.
Making your networks to learn faster in TensorFlow 2+
There are still a lot of models that use Batch Normalization layers. If you would like to do transfer learning on such models, you can have a lot of problems. It was much easier to finetune AlexNet or VGG as they do not contain batch norm layers. Many developers are curious why the more modern CNN architecture is not able to perform as well as the older one.
I ran to the problem of batch norm layers several times. I thought that something is wrong with the optimization of the model. Then I found the article by Datumbox about the broken Batch Norm layer in Keras. The problem was that when the layer is frozen, it continues to use the mini-batch statistics during training. The pull request by the author was not merged. However, the new TensorFlow 2 should behave a bit better when working with Batch Norm layers. Some people still have problems with tf.keras.applications in TF2 and need to reinject new Batch Norm layers to the model.
Other people are still wondering why their TensorFlow models are worse than the PyTorch when finetuning their models. The default gamma param causes one common problem in TF2. Default gamma param in PyTorch is 0.9. However, in TensorFlow, it is 0.99.
This number is not optimal if you are doing Transfer Learning on a pre-trained imagenet model and:
- your dataset is from a different domain than “Imagenet.”
- your dataset has only a few thousand of images
- you are using a small batch size
Another difference between TF2 and PyTorch is how the frameworks are behaving when freezing/unfreezing pretrained backbone models.
BatchNorm when freezing layers
If you are freezing the pretrained backbone model then I recommend looking at this colab page by Keras creator François Chollet.
Setting base_model(inputs, training=False) will make the batch norm layers to stop update the non-trainable params during the training which is critical during freezing and unfreezing. Be aware that this setting is not going to freeze trainable weights in your base_model. If you want to freeze trainable weights of the base model then set base_model.trainable = False. But don’t forget also call base_model(inputs, training=False) first because BatchNormalization layers contain non-trainable params that are still changing even if base_model.trainable = False. Just look at the colab file, it will make more sense!
Let’s Experiment with momentum
Let’s see what momentum param means when you are doing Transfer Learning in your models. We are going to pick two datasets for our experiments “imagenette” and “colorectal_histology.” Our model in this experiment is unfrozen, which means all layers/weights are trainable.
The first dataset, “imagenette,” has images similar to Imagenet. That’s why the model can be easily fitted as it was pre-trained on Imagenet. The BatchNorm statistics of images is similar to the original dataset. We can see it in the following figure. This is just a simple example to show that the model can easily achieve almost 100 % accuracy, so ignore the overfitting:

If we will try to fit “colorectal_histology,” the figure looks like this.

Let’s apply this fix to change the param of the batch norm from 0.99 to 0.9, so the layers will learn a bit faster. We will create our BatchNorm layers and inject it into the model.
Reinject the Batch Norm layer with fixed 0.9 momentum param.
Now the learning of such model looks much better:

Small batch size
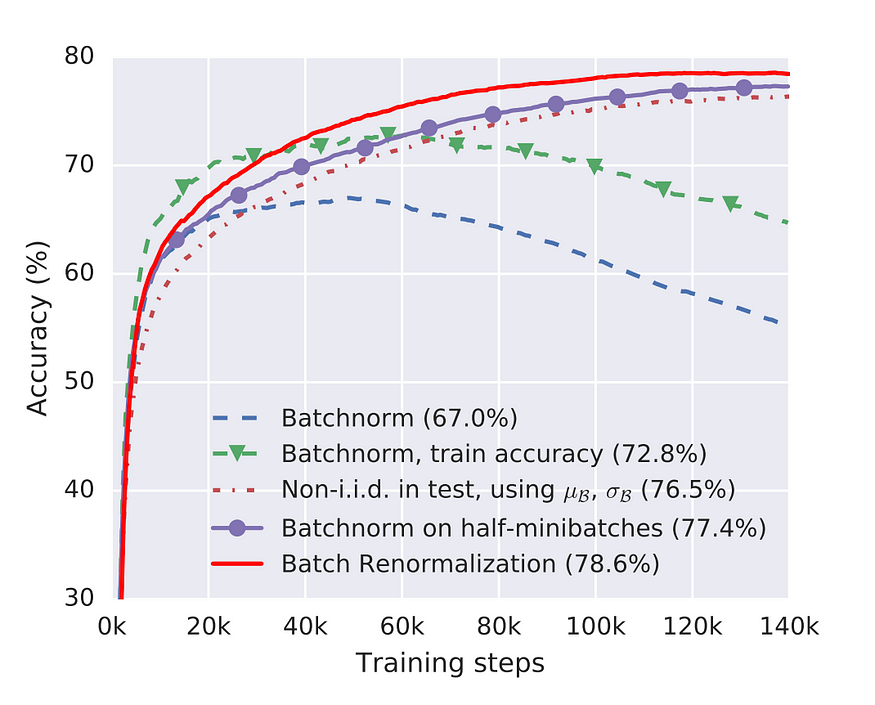
Some projects and teams use the Batch Renormalization [source] layer instead of Batch Normalization. The technique looks very promising for big networks (Object Detection, …) because you can’t use a big batch size as you are not able to fit larger ones on the GPU card. Batch Renormalization layer is implemented as param ‘renorm’ in the TensorFlow BatchNormalization layer. The authors of the paper fit model with the first 5000 steps with params rmax = 1 and dmax = 0 (classic BatchNormalization). After these initial steps, they gradually increase to rmax =3 and dmax = 5. You can do this in TensorFlow 2+ by writing your own callback. If you want to know how this technique works then read the original paper. There are also other promising normalization techniques that look better than classic BatchNorm like Group Normalization [source]. GroupNorm is implemented in TF Addons library.
To sum up
If your model contains batch normalization layers, be aware that it can cause you a lot of problems during the training or when deployed in a production environment. To learn more about the best practices, I recommend a great fast.ai course and forums. See also our previous article about the preprocessing layer, which can save you a lot of time.
Starting with a pre-trained model on Imagenet is sometimes (for example, most of the healthcare pictures) not optimal, and different pretraining techniques make perfect sense.
Michal
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



