



From Garbage In to Gold Out: Understanding Denoising Autoencoders
Last Updated on July 17, 2023 by Editorial Team
Author(s): Anay Dongre
Originally published on Towards AI.
A denoising autoencoder (DAE) is a type of autoencoder neural network architecture that is trained to reconstruct the original input from a corrupted or noisy version of it.
Let’s begin by asking the question, What do Autoencoders exactly do?
Autoencoders are a type of neural network architecture that are designed to learn a compact, low-dimensional representation of the input data, called the encoded representation or bottleneck. The main idea behind autoencoders is to use the encoded representation to reconstruct the original input data through a process called decoding. Autoencoders are trained to minimize the difference between the original input and the reconstruction.
Its’ now clear what autoencoders are and what they are used for, Now we deep dive into Denoising Autoencoders.
Introduction: A denoising autoencoder (DAE) is a type of autoencoder neural network architecture that is trained to reconstruct the original input from a corrupted or noisy version of it. The main idea behind a DAE is to add noise to the input data during training, and then train the network to reconstruct the original, noise-free input. This allows the network to learn a more robust and generalizable representation of the input data.
How do DAE’s learn?
Denoising autoencoders (DAEs) learn by training the encoder and decoder networks to reconstruct the original, noise-free input from a corrupted or noisy version of it. The training process can be summarized in the following steps:
- Input data is corrupted by adding noise to it. The noise can be added in different ways, such as masking out a certain percentage of the input’s pixels, or adding Gaussian noise.
- The corrupted input is passed through the encoder network, which maps the input data to a lower-dimensional encoded representation.
- The encoded representation is passed through the decoder network, which generates a reconstruction of the original, noise-free input.
- The reconstruction is compared to the original input, and the difference is used to calculate the reconstruction error. The reconstruction error is used as the loss function to update the weights of the encoder and decoder networks.
- The process is repeated for multiple iterations, and the weights of the encoder and decoder networks are updated in order to minimize the reconstruction error.
During the training process, the DAE learns to map the noisy input data to a robust, low-dimensional encoded representation, which is less sensitive to the noise. The decoder network learns to map the encoded representation back to the original, noise-free input.
Architecture of DAE’s
A denoising autoencoder (DAE) is typically composed of two main parts: an encoder and a decoder network.
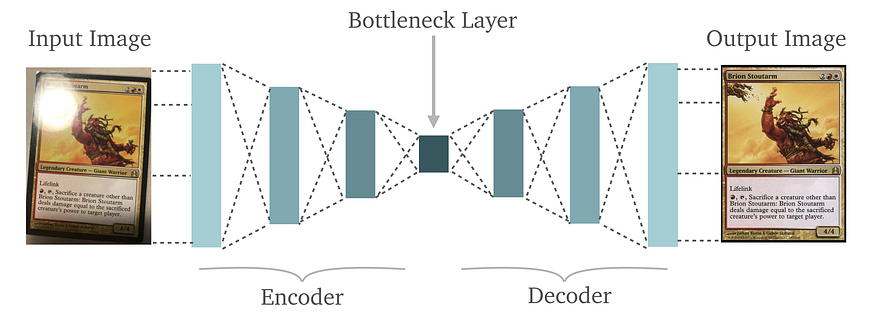
Encoder Network: The encoder network in a denoising autoencoder (DAE) maps the input data to a lower-dimensional encoded representation. The architecture of the encoder network can vary depending on the specific application and the type of input data.
For example, for image data, the encoder network can be composed of convolutional layers that extract features from the image. The convolutional layers can be followed by pooling layers that reduce the spatial dimensions of the feature maps. These layers can also be followed by fully connected layers that map the features to the encoded representation.
For text data, the encoder network can be composed of recurrent layers that capture the sequential information in the text. The recurrent layers can be followed by fully connected layers that map the sequential information to the encoded representation.
The encoded representation is usually a low-dimensional vector, that contains the most important information from the input data. The size of the encoded representation vector is typically much smaller than the size of the input data, and it’s also known as the bottleneck of the network.
Additionally, some variations of the autoencoder architecture, such as Variational Autoencoder (VAE) and Generative Adversarial Autoencoder (GAE) have the encoder network to output the parameters of a probability distribution, and not only a fixed vector.
Decoder Network: The decoder network in a denoising autoencoder (DAE) maps the encoded representation back to the original input space, in order to reconstruct the original input from the noisy version of it. The architecture of the decoder network is typically the mirror of the encoder network, with the layers arranged in reverse order.
For example, if the encoder network is composed of convolutional and pooling layers, the decoder network can be composed of up-sampling layers followed by convolutional layers, in order to increase the spatial dimensions of the feature maps and reconstruct the original image.
For text data, the decoder network can be composed of recurrent layers followed by fully connected layers, in order to reconstruct the original text from the encoded representation.
The decoder network is usually trained to minimize the reconstruction error between the original input and the reconstruction. The decoder network should learn to ignore the noise in the input and focus on the underlying structure of the input data.
Hyperparameters of DAE’s
There are several hyperparameters that can be adjusted when training a denoising autoencoder (DAE), including:
- Noise level: The level of noise added to the input data during training. A higher noise level will make the training process more difficult, but it can lead to a more robust and generalizable representation of the input data.
- Number of layers: The number of layers in the encoder and decoder networks. A deeper network can learn more complex representations of the input data, but it can also increase the risk of overfitting.
- Number of neurons: The number of neurons in each layer of the encoder and decoder networks. A higher number of neurons can increase the capacity of the network to learn complex representations, but it can also increase the risk of overfitting.
- Learning rate: The learning rate is a hyperparameter that controls the step size at which the optimizer makes updates to the model’s parameters.
- Batch size: The number of samples used in one forward/backward pass. A larger batch size can speed up the training process, but it can also require more memory.
- Number of epochs: The number of times the entire dataset is passed through the network during training. A higher number of epochs can lead to a better trained model, but it can also increase the risk of overfitting.
- Activation function: The activation function used in the layers of the network. Different activation functions have different properties and can affect the performance of the network.
- Optimizer : The optimizer used to update the model’s parameters during training. Different optimizers have different properties and can affect the performance of the network.
You just learnt about how DAE’s learn and its architecture. The obvious question is, what are its applications ?
Applications of DAE’s
- Image denoising: DAEs can be used to remove noise from images, such as salt and pepper noise, Gaussian noise, and impulse noise.
- Anomaly detection: DAEs can be used to detect outliers or anomalies in the data. By training the DAE on normal data and then using it to reconstruct new, unseen data, the DAE can identify data points that are significantly different from the normal data.
- Data compression: DAEs can be used to compress data by learning a low-dimensional representation of the input data. The encoded representation can be used as a compact representation of the data, while the decoder network can be used to reconstruct the original data from the encoded representation.
- Generative models: DAEs can be used to generate new data that is similar to the training data. By sampling from the encoded representation, the decoder network can generate new data points that are similar to the training data.
- Pre-training for deep neural networks: DAEs can be used as a pre-training method for deep neural networks. The encoded representation learned by the DAE can be used as the starting point for training a deeper network, which can improve the performance and stability of the training process.
It is very important to get your hand’s dirty to fully grasp the concept. Simply reading about theory isn’t enough.
Implementation of DAE’s
- For implementation of Denoising Autoencoder using Keras, refer to Denoising Images Using Autoencoders.
- If you want PyTorch implementation, refer to Collaborative Denoising Autoencoders on PyTorch Lightning
If the article isn’t enough to suffice your thirst for knowledge,
Refer to these research papers and articles which are also my references:
- Meng, L., Ding, S. & Xue, Y. Research on denoising sparse autoencoder. Int. J. Mach. Learn. & Cyber. 8, 1719–1729 (2017). https://doi.org/10.1007/s13042-016-0550-y
- Wang J, Xie X, Shi J, He W, Chen Q, Chen L, Gu W, Zhou T. Denoising Autoencoder, A Deep Learning Algorithm, Aids the Identification of A Novel Molecular Signature of Lung Adenocarcinoma. Genomics Proteomics Bioinformatics. 2020 Aug;18(4):468–480. doi: 10.1016/j.gpb.2019.02.003. Epub 2020 Dec 18. PMID: 33346087; PMCID: PMC8242334.
- Komal Bajaj, Dushyant Kumar Singh, Mohd. Aquib Ansari,
Autoencoders Based Deep Learner for Image Denoising,
Procedia Computer Science, Volume 171,2020,Pages 1535–1541,
ISSN 1877–0509,https://doi.org/10.1016/j.procs.2020.04.164.
(https://www.sciencedirect.com/science/article/pii/S1877050920311431) - Monn, Dominic. “Denoising Autoencoders Explained — Towards Data Science.” Medium, 11 June 2018, towardsdatascience.com/denoising-autoencoders-explained-dbb82467fc2.
- Jadhav, Murli. “Auto Encoders: De-Noising Text Documents — Analytics Vidhya.” Medium, 13 Dec. 2021, medium.com/analytics-vidhya/auto-encoders-de-noising-text-documents-c58d6950dfad.
- Meng, L., Ding, S. & Xue, Y. Research on denoising sparse autoencoder. Int. J. Mach. Learn. & Cyber. 8, 1719–1729 (2017). https://doi.org/10.1007/s13042-016-0550-y
To end on a lighter note, here a pun for the people who stuck till the end.
Why did the DAE cross the road?
To get to the other side of the noise.
Sorry for the pun and happy learning !
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

