



Face Data Augmentation. Part 2: Image Synthesis
Last Updated on December 29, 2022 by Editorial Team
Author(s): Ainur Gainetdinov
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
In this paper, I present methods for generating synthetic images for face augmentation using recently presented GANs.
An essential bottleneck in deep learning is data availability. Effective training of models requires a lot of data. Plenty of techniques are used for dataset augmentation to increase the number of training examples. Typical data augmentations include a very limited set of transformations like rotation, reflection, cropping, translation, and scaling of existing images. A little additional information can be achieved from small changes to the images. Synthetic data augmentation is a new, advanced type of data augmentation. High-quality synthetic data produced by a generative model facilitate more variability and enrich the dataset to further improve the model.
The huge progress of generative models provides powerful tools for the creation of new data from a trained distribution. Mathematically, generative models work as follows. Black dots on the right side of figure 1 represent images from the true data distribution. The generative model, the yellow one, maps unit gaussian distribution into generated distribution, the green one. The shape of the generated distributionа depends on model parameters θ. The goal of training is finding the parameters θ, which minimize the difference between generated and true data distributions.
Among the most popular generative models are Generative Adversarial Networks (GAN), Variational Autoencoders (VAE), and diffusion models. GAN consists of two models, a generator and a discriminator, which compete with each other while making each other stronger at the same time. The discriminator learns to distinguish between real or fake input images, while the generator learns to generate fake samples which are indistinguishable for the discriminator. VAE consists of two components: an encoder and a decoder. The encoder encodes input data to a latent representation, specifically into gaussian distribution. The decoder decodes latent points from gaussian distribution back into data space. Diffusion models progressively add gaussian noise to data, then learn to reverse this process for sample generation.
Let’s see how we can use GANs for image augmentation. Sometimes it is impossible or laborious to get a big, diverse, quality dataset. It’s beneficial to train GAN on that limited data before training a model for tasks like classification, object detection, segmentation, etc. Once we train a model, we can generate as much data as we want. Of course, the diversity of such a synthesis is limited as our trained GAN just replicates training data. Quite a different matter if we fine-tune GAN pre-trained on a bigger dataset. In this case, pre-trained GAN can generate rich, diverse data in advance. Fine-tuning step learns training data distribution while it retains properties of the pre-trained model if distributions of pre-train and train data are close enough. This allows you to qualitatively increase the size of the dataset by several orders of magnitude.
A useful property of GANs is the ability to manipulate a process of image generation. Let’s take a look at the most popular GAN in the field of human face generation — StyleGan[1]. Instead of directly mapping input 512-dimensional gaussian noise to the image, it maps it to intermediate latent code of the same dimension. Neural net learns to disentangle face representation and creates meaningful latent space. It allows the manipulation of human faces. There are directions in this latent space that correspond to face modifications like gender, haircut, emotions, shape, etc. Varying latent code toward some direction, we alter the generated image respectively.
Another generative model SemanticStyleGAN[2] gives control of the generation of each facial semantic part like shape, color, eye, eyebrow, mouth, nose, hair, background, etc. The authors suggest using different latent codes for each facial part with a corresponding local generator for each latent code. Local generators map the latent codes into facial parts with depth masks, and then they are combined into a single image. This provides more precise local controls over the face image shown in figure 2.

The Augmentation process looks as follows. We take a generated image from unit gaussian distribution or invert any face photo to latent space. Inversion can be made by an optimization algorithm. For complete similarity between our and inverted image, we can fine-tune GAN on calculated latent code for approximately 300 iterations. Now we can alter face semantics by mixing our latent codes with latent codes of other faces. For example, if we solve the problem of face recognition, we would be interested in retaining the identity and adding modifications to lighting conditions and haircuts. For this purpose, we freeze all latent codes except ones responsible for lightning and haircuts and vary them as demonstrated in figures 3, and 4.

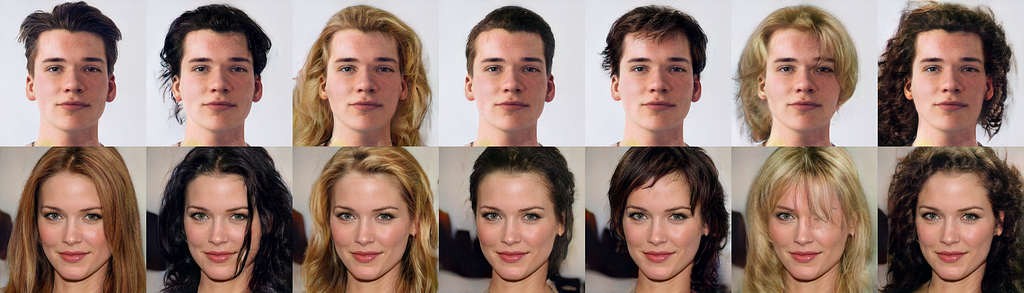
The ability of generative models to synthesize plausible, diverse images opens new opportunities to boost the performance of deep learning models. In this article, we talked about several methods of how we can use GANs for face data augmentation.
Thank you for reading. I hope this helps you to improve your models.
References:
- A Style-Based Generator Architecture for Generative Adversarial Networks. Tero Karras, Samuli Laine, Timo Aila.
- SemanticStyleGAN: Learning Compositional Generative Priors for Controllable Image Synthesis and Editing. Yichun Shi, Xiao Yang, Yangyue Wan, Xiaohui Shen.
- Project site of SemanticStyleGAN: https://semanticstylegan.github.io
Face Data Augmentation. Part 2: Image Synthesis was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts



")


