


Unlocking Document Intelligence: E2E Azure-Powered Chatbot with Vector-Based Search (Part 1 — Embedding)
Last Updated on February 29, 2024 by Editorial Team
Author(s): Shravankumar Hiregoudar
Originally published on Towards AI.
In today’s fast-paced business environment, having quick and efficient access to information is crucial. Many organizations deal with a vast amount of unstructured data, such as documents and images, and need to extract and retrieve specific information from these documents. Additionally, providing a natural language interface for querying this information can enhance user experience and productivity.
Table of contents:
- Introduction
- Problem Statement
- Solution Overview
3.1 Architecture
3.2 Embedding Pipeline - Implementation Highlights
- Embedding Implementation
5.1 Project Layout
5.2 Prerequisites
5.3 Project Files - Next Part
Introduction
In this part of our technical journey, we focus on the pivotal stage of document embedding and its storage as a vector store, which forms the fundamental basis for enabling efficient and effective querying. The next part will reveal the intricacies of querying this vector store using natural language questions, thereby unlocking the full potential of our document processing pipeline.
This development is split into two blog parts: PART 1 U+007C PART 2

Problem Statement
Imagine you are working on a business use case of managing many documents in various formats, such as PDF, Word, PowerPoint, and Images. Your goal is to create a system that can:
- Automatically extract text, table, and key-value pair data from these documents.
- Store the extracted information in a way that allows for efficient querying.
- Provide a chat interface for users to ask questions and receive answers.
Solution Overview
Architecture

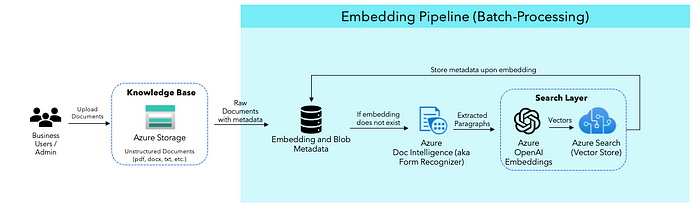
Embedding Pipeline
The Embedding Pipeline focuses on extracting documents from Azure Blob Storage, processing this data using Azure Form Recognizer, and storing it in a format that enables efficient querying in Azure Search Index. Let’s break down the key components and steps in this pipeline:

- Document Retrieval: The code first connects to an Azure Storage container, where the documents are stored. It iterates through the documents in the container, checking for specific file types (in this use case, we are extracting only PDF files If you want to implement .docx, .pptx, etc., I recommend converting the file to .pdf as the form recognizer doesn’t support other Microsoft data files) and whether the document has already been processed. (BlobServiceClient Class)
- Text Extraction: If a document is not embedded yet (we maintain a database to keep track of embedding metadata), the code extracts text, table, and key-value information from the document using Azure Form Recognizer.
- Text Chunking: The extracted text is split into smaller chunks to facilitate efficient processing. (langchain text splitter)
- Embedding: The code uses OpenAI’s “text-embedding-ada-002” model to generate embeddings for the text chunks. These embeddings represent the textual content and are used for later retrieval. (Embeddings in the context of NLP are numerical representations of text that allow words or phrases with similar meanings to have a similar representation. The Azure OpenAI embedding model creates these embeddings. To obtain an embedding vector for text, we request the embedding endpoint.)
- Vector Store: The embeddings are stored in Azure Cognitive Search, enabling fast and scalable querying of the documents. (After creating embeddings, they can be stored in a vector store (like pinecone, chroma, and faiss). The vector store we are using is the index of Azure search, a memory-efficient way to store large volumes of high-dimensional vectors, which can be searched and compared efficiently. These vector representations are language-agnostic and can handle various data types, making them versatile for different applications.)
The Embedding Pipeline ensures that text and document data are efficiently processed, embedded, and available for retrieval.
Implementation Highlights
The code makes extensive use of Python and relies on several libraries and services, including:

- Azure Blob Storage: For accessing and storing documents.
- Azure Form Recognizer: For text and document data extraction.
- Azure Cognitive Search: For storing document embeddings and enabling efficient retrieval.
- OpenAI’s GPT-3.5 Turbo: For generating responses to user queries.
- OpenAI’s text-embedding-ada-002: For generating embeddings.
- Langchain: The Library provides essential components for NLP and document retrieval, including tools for text splitting, generating text embeddings, working with Azure Cognitive Search, and interacting with OpenAI chat models.
- Streamlit: For building a user-friendly chat interface.
Embedding Implementation
Python code that demonstrates an end-to-end document processing pipeline.
Project Layout
# Project Layout
.
├── README.md
├── requirements.txt
├── app.py
├── .gitignore
├── .env
├── db/
│ ├── metadata.db
└── src/
├── database_manager.py
Prerequisites
Before running the code, ensure you have the following prerequisites set up:
- Azure Services: Create the services Azure Blob Storage, Azure Form Recognizer, and Azure Cognitive Search.
- OpenAI APIs: You’ll need access to the OpenAI APIs to use the chat models and embeddings.
- Python Dependencies: Install the required Python packages by running
pip install -r requirements.txt. - Environment Variables: Create a
.envfile in the same directory as the script with the following environment variables:
# Azure Cognitive Search configurations
AZURE_COGNITIVE_SEARCH_SERVICE_URL=<your_search_service_url>
AZURE_COGNITIVE_SEARCH_SERVICE_NAME=<your_search_service_name>
AZURE_COGNITIVE_SEARCH_API_KEY=<your_search_service_api_key>
# Azure Storage configurations
AZURE_STORAGE_CONNECTION_STRING=<your_storage_connection_string>
AZURE_CONTAINER_NAME=<your_container_name>
# Azure AI Document Intelligence (Form Recognizer) configurations
FORM_RECOGNIZER_ENDPOINT=<your_form_recognizer_endpoint>
FORM_RECOGNIZER_KEY=<your_form_recognizer_key>
# OpenAI Chat API configurations
OPENAI_API_TYPE=<your_openai_api_type>
OPENAI_API_BASE=<your_openai_api_base_url>
OPENAI_API_KEY=<your_openai_api_key>
OPENAI_API_VERSION=<your_openai_api_version>
# OpenAI Embedding API configurations
EMBED_API_BASE=<your_openai_embedding_api_base_url>
EMBED_API_KEY=<your_openai_embedding_api_key>
EMBED_API_VERSION=<your_openai_embedding_api_version>
5. Azure Services Connection Check: Check the API connections for all the Azure services
Project Files
Let's take a look at the code and its functionalities.
- requirements.txt
# Project Layout
.
├── README.md
├── requirements.txt
├── app.py
├── .gitignore
├── .env
├── db/
│ ├── metadata.db
└── src/
├── database_manager.py
# requiremnt.txt
streamlit==1.0.0
python-dotenv==0.19.1
langchain==0.0.276
azure-ai-formrecognizer==3.3.0
azure-common==1.1.28
azure-core==1.29.4
azure-identity==1.14.0
azure-search-documents==11.4.0b8
azure-storage-blob==12.18.2
- database_manager.py
# Project Layout
.
├── README.md
├── requirements.txt
├── app.py
├── .gitignore
├── .env
├── db/
│ ├── metadata.db
└── src/
├── database_manager.py
database_manager.py is for managing an SQLite database (metadata. db)that stores metadata about embedded blobs, such as documents processed in an embedding pipeline ((EmbeddingMetadata) table)
This class helps track the status and history of documents processed in an embedding pipeline by maintaining a record of their existence and the timestamp of their last embedding.
import sqlite3
from datetime import datetime
class DatabaseManager:
def __init__(self, db_file):
"""
Initialize the DatabaseManager.
:param db_file: The name of the SQLite database file.
"""
self.db_file = db_file
self.conn = sqlite3.connect(self.db_file)
self.cursor = self.conn.cursor()
self.create_database_table()
def create_database_table(self):
"""
Create the 'EmbeddingMetadata' table in the database if it doesn't exist.
This table stores metadata about embedded blobs.
:return: None
"""
self.cursor.execute('''CREATE TABLE IF NOT EXISTS EmbeddingMetadata
(BlobName TEXT PRIMARY KEY, ExistsInBlob TEXT, ExistsInSearch TEXT, LatestEmbeddedOn DATE)''')
self.conn.commit()
def record_exists_in_database(self, blob_name):
"""
Check if a record with the given `blob_name` exists in the database.
:param blob_name: The name of the blob to check.
:return: True if the record exists, False otherwise.
"""
self.cursor.execute("SELECT COUNT(*) FROM EmbeddingMetadata WHERE BlobName=?", (blob_name,))
count = self.cursor.fetchone()[0]
return count > 0
def insert_record_to_database(self, blob_name, exists_in_blob, exists_in_search):
"""
Insert a new record into the 'EmbeddingMetadata' table.
:param blob_name: The name of the blob to insert.
:param exists_in_blob: A flag indicating if the blob exists.
:param exists_in_search: A flag indicating if the blob exists in search.
:return: None
"""
latest_embedded_on = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
if not self.record_exists_in_database(blob_name):
self.cursor.execute("INSERT INTO EmbeddingMetadata (BlobName, ExistsInBlob, ExistsInSearch, LatestEmbeddedOn) VALUES (?, ?, ?, ?)",
(blob_name, exists_in_blob, exists_in_search, latest_embedded_on))
self.conn.commit()
- app.py
# Project Layout
.
├── README.md
├── requirements.txt
├── app.py
├── .gitignore
├── .env
├── db/
│ ├── metadata.db
└── src/
├── database_manager.py
Import the libraries and get all the .env variables.
# app.py
import os
import logging
import streamlit as st
import openai
import json
from dotenv import load_dotenv
from azure.ai.formrecognizer import FormRecognizerClient
from azure.core.credentials import AzureKeyCredential
from azure.storage.blob import BlobServiceClient
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores.azuresearch import AzureSearch
from langchain.chat_models import AzureChatOpenAI
from langchain.vectorstores.base import Document
from langchain.chains import RetrievalQA, RetrievalQAWithSourcesChain
from langchain.retrievers import AzureCognitiveSearchRetriever
from src.database_manager import DatabaseManager
load_dotenv()
# Configure the logger
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Disable logging for azure.core.pipeline.policies.http_logging_policy
logging.getLogger("azure.core.pipeline.policies.http_logging_policy").setLevel(
logging.WARNING)
# Azure Search configurations
AZURE_SEARCH_URL = os.getenv("AZURE_COGNITIVE_SEARCH_SERVICE_URL")
AZURE_SEARCH_NAME = os.getenv("AZURE_COGNITIVE_SEARCH_SERVICE_NAME")
AZURE_SEARCH_KEY = os.getenv("AZURE_COGNITIVE_SEARCH_API_KEY")
# Azure Storage configurations
STORAGE_CONTAINER_STRING = os.getenv("AZURE_STORAGE_CONNECTION_STRING")
STORAGE_CONTAINER_NAME = os.getenv("AZURE_CONTAINER_NAME")
# Form Recognizer configurations
FORM_RECOGNIZER_ENDPOINT = os.getenv("FORM_RECOGNIZER_ENDPOINT")
FORM_RECOGNIZER_KEY = os.getenv("FORM_RECOGNIZER_KEY")
# Azure OpenAI Chat Completion configurations
OPENAI_API_TYPE = os.getenv('OPENAI_API_TYPE')
CHAT_API_BASE = os.getenv('OPENAI_API_BASE')
CHAT_API_KEY = os.getenv('OPENAI_API_KEY')
CHAT_API_VERSION = os.getenv('OPENAI_API_VERSION')
# Azure OpenAI Embedding configurations
EMBED_API_BASE = os.getenv('EMBED_API_BASE')
EMBED_API_KEY = os.getenv('EMBED_API_KEY')
EMBED_API_VERSION = os.getenv('EMBED_API_VERSION')
# Default items
DEFAULT_EMBEDDING_MODEL = "text-embedding-ada-002"
DEFAULT_CHAT_MODEL = "gpt-35-turbo"
DEFAULT_SEARCH_INDEX = "<your-index>"
DEFAULT_SEARCH_FILE_EXTENSION = ".pdf"
LOAD_VECTORS = True
The EmbeddingPipeline class resides in app.py and is responsible for the document embedding process, which involves extracting text from documents, splitting text into chunks, and storing text embeddings for retrieval.
# app.py
class EmbeddingPipeline:
def __init__(self):
load_dotenv()
self.form_recognizer_client = self.get_form_recognizer_client()
self.db_manager = DatabaseManager("db/metadata.db")
self.embedder = OpenAIEmbeddings(model=DEFAULT_EMBEDDING_MODEL,
openai_api_base=EMBED_API_BASE,
openai_api_key=EMBED_API_KEY,
openai_api_version=EMBED_API_VERSION,
openai_api_type=OPENAI_API_TYPE)
def get_form_recognizer_client(self):
"""
Get an instance of the Form Recognizer Client.
Returns:
FormRecognizerClient: An instance of the FormRecognizerClient class.
"""
credential = AzureKeyCredential(FORM_RECOGNIZER_KEY)
return FormRecognizerClient(endpoint=FORM_RECOGNIZER_ENDPOINT, credential=credential)
def form_recognizer_data_extract(self, blob_content):
"""
Azure Form Recogniser extracts text from the PDF files loaded from the container.
NOTE: You can process other data files (.docx, .pptx etc) by manually converting them to .pdf as form recognizer doesnt support all the microsoft file types.
Args:
blob_content (bytes): The content of the blob to extract data from.
Returns:
tuple: A tuple containing:
- list of dictionaries: Extracted table data.
- list of dictionaries: Extracted line data.
- str: Extracted text data.
"""
table_data = []
line_data = []
text = ""
try:
form_recognizer_result = self.form_recognizer_client.begin_recognize_content(
blob_content).result()
for page in form_recognizer_result:
for table in page.tables:
table_info = {"table_cells": []}
for cell in table.cells:
cell_info = {
"text": cell.text,
"bounding_box": cell.bounding_box,
"column_index": cell.column_index,
"row_index": cell.row_index
}
table_info["table_cells"].append(cell_info)
table_data.append(table_info)
for line in page.lines:
text += " ".join([word.text for word in line.words]) + "\n"
line_info = {
"text": line.text,
"bounding_box": line.bounding_box
}
line_data.append(line_info)
logger.info(
"\t\tStep 3: Azure Form Recognizer - Extracted text from the file/s loaded from the container")
return table_data, line_data, text
except Exception as e:
logger.warning(
f"\t\tStep 3 (ERROR): Azure Form Recognizer - An error occurred while extracting form data: {e}")
return [], [], []
def get_text_chunks(self, text, blob_name):
"""
Split a large text into smaller chunks for further processing.
Args:
text (str): The text to be split into chunks.
Returns:
list of Document: List of Document objects representing text chunks.
"""
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_text(text)
docs = [Document(page_content=chunk, metadata = {"source":blob_name}) for chunk in chunks]
logger.info("\t\tStep 4: Pre-Embedding - File is split into many smaller chunks")
return docs
def load_vectorstore(self, documents):
"""
Azure OpenAI "text-embedding-ada-002" model prepare embeddings to the chunked files and upload vectors into Azure Cognitive Search Index.
Args:
documents (list of dict): List of documents to be added to Azure Cognitive Search.
Returns:
AzureSearch: An instance of AzureSearch containing the loaded vectors.
"""
try:
vectorstore = AzureSearch(
azure_search_endpoint=AZURE_SEARCH_URL,
azure_search_key=AZURE_SEARCH_KEY,
index_name=DEFAULT_SEARCH_INDEX,
embedding_function=self.embedder.embed_query,
)
vectorstore.add_documents(documents=documents)
logger.info(
f"\t\tStep 5: Azure Cognitive Search - Embeddings are created and vectors are stored in Azure Search index: '{DEFAULT_SEARCH_INDEX}'")
except openai.error.APIError as api_error:
logger.error(
f"\t\tStep 5 (ERROR): Azure Cognitive Search - Error: {api_error}")
def perform_embedding_pipeline(self):
"""
Process documents in an Azure Storage container and perform an embedding pipeline on them.
This function retrieves documents stored in an Azure Storage container specified by 'container_name'
and processes each document. It checks if the document's content type matches a predefined extension
(e.g., '.pdf') and, if so, extracts data using Form Recognizer, processes the extracted data,
and loads it into a vector store.
Parameters:
storage_connection_string (str): The connection string for the Azure Storage account where the
container is located.
container_name (str): The name of the Azure Storage container containing the documents to process.
"""
logger.info( f"__NOTE__ Processing only {DEFAULT_SEARCH_FILE_EXTENSION} types")
try:
blob_service_client = BlobServiceClient.from_connection_string(STORAGE_CONTAINER_STRING)
blob_container_client = blob_service_client.get_container_client(STORAGE_CONTAINER_NAME)
exists, inserted = 0, 0
for blob in blob_container_client.list_blobs():
if blob.name.endswith(DEFAULT_SEARCH_FILE_EXTENSION) and not self.db_manager.record_exists_in_database(blob.name):
blob_client = blob_service_client.get_blob_client(container = STORAGE_CONTAINER_NAME, blob = blob.name)
blob_content = blob_client.download_blob().readall()
logger.info( f"\tProcessing Document '{blob.name}' : ")
logger.info( f"\t\tStep 2: Azure Storage Container - Blob content fetched successfully")
# only using 'raw_text' as of now
table_data, line_data, raw_text = self.form_recognizer_data_extract(blob_content)
documents = self.get_text_chunks(raw_text, blob.name)
self.load_vectorstore(documents)
self.db_manager.insert_record_to_database(blob.name, 'Y', 'Y')
inserted +=1
elif blob.name.endswith(DEFAULT_SEARCH_FILE_EXTENSION) and self.db_manager.record_exists_in_database(blob.name):
exists +=1
logger.info(f"Embedding Summary : Processed {inserted} new file(s) out of {exists + inserted} total file(s) in the container. Stored vectors for {inserted} new file(s); as {exists} file(s) already had vectors.")
except Exception as e:
print(e)
class ChatPipeline:
# ........ (refer to part 2)
def main():
# ........ (refer to part 2)
if __name__ == "__main__":
main()
In this segment of our technical journey, we delve into the crucial step of document embedding and its storage as a vector store, an essential foundation for enabling efficient and effective querying. As we progress, the next part of our exploration will unveil the intricacies of querying this vector store using natural language questions, thereby unlocking the full potential of our document processing pipeline.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

