



The NLP Cypher | 03.14.21
Last Updated on July 24, 2023 by Editorial Team
Author(s): Ricky Costa
Originally published on Towards AI.
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
The NLP Cypher U+007C 03.14.21
Set the Controls for the U+2665 of the Sun
Happy Pi Day!
Let’s talk about “Cryptonite: How I Stopped Worrying and Learned(?) to Love Ambiguity”
Cryptonite is a cryptic clue, a short phrase or sentence with a misleading surface reading, whose solving requires disambiguating semantic, syntactic, and phonetic wordplays, as well as world knowledge.
example:

And luckily, It’s also a dataset…
And it’s an important dataset to consider the ambiguity of language. Solving the ambiguity problem, whether its derived strictly from NLP only or from a combination of multi-modal models, or from graphs, will be key in order for models to achieve what Thomas Paine called “Common Sense”. Why? Because it requires models to have n-order logic. You can think of n-order logic as the Russian doll of logic, which is, logic nested within logic. And it’s what we use when we do battle with a New York Times crossword puzzle, which requires different uses of word play, world knowledge and other linguistic artifacts.
This is a very tough problem for current transformers to solve for. In fact, the authors of the paper said that a T5-Large trained on the Cryptonite dataset achieved only 7.6% accuracy U+1F440, which is on par with rule-based accuracy U+1F648 .
Translation: Transformers suck at this task.
This type of ‘reasoning’ is what lies at the highest level of abstraction of the human brain. Intuition tells me that n-order-logic will require hypergraphs, but the future is unwritten…
aviaefrat/cryptonite
Current NLP datasets targeting ambiguity can be solved by a native speaker with relative ease. We present Cryptonite, a…
github.com
Hub Datasets
Hub, the data storage application from Activeloop.AI is riding the dataset gravy train. Their framework stores datasets in the cloud as numpy arrays so you can access it seamlessly across several frameworks. Here are the features:
- Store and retrieve large datasets with version-control
- Collaborate as in Google Docs: Multiple data scientists working on the same data in sync with no interruptions
- Access from multiple machines simultaneously
- Deploy anywhere — locally, on Google Cloud, S3, Azure as well as Activeloop
- Integrate with your ML tools like Numpy, Dask, Ray, PyTorch, or TensorFlow
- Create arrays as big as you want. You can store images as big as 100k by 100k!
- Keep shape of each sample dynamic. This way you can store small and big arrays as 1 array.
- Visualize any slice of the data in a matter of seconds without redundant manipulations
activeloopai/Hub
Note: the translations of this document may not be up-to-date. For the latest version, please check the README in…
github.com
PyTorch Lightning Update U+1F525
A new update is out!
PyTorch is going in heavy on multiple methods for distributed training and model compression, here are some the features in BETA:
DeepSpeed
Pruning
Quantization
They are also integrating PyTorch Geometric! GNNs!!! (hype)
PyTorch Lightning V1.2.0- DeepSpeed, Pruning, Quantization, SWA
Including new integrations with DeepSpeed, PyTorch profiler, Pruning, Quantization, SWA, PyTorch Geometric and more.
medium.com
Talking about PyTorch… Basic Tutorials
An awesome introduction to PyTorch showing an end-to-end ML pipeline from loading your data all the way to saving a trained model, includes a Colab notebook:
Learn the Basics – PyTorch Tutorials 1.8.0 documentation
Learn the Basics U+007CU+007C Quickstart U+007CU+007C Tensors U+007CU+007C Datasets & DataLoaders U+007CU+007C Transforms U+007CU+007C Build Model U+007CU+007C Autograd U+007CU+007C…
pytorch.org
Ok Ok, Last Mention of PyTorch… Promise
Here’s a handy deep learning project template using PyTorch Lightning, Hydra, and Tensorboard. Ok I’m done. U+1F60E
lkhphuc/lightning-hydra-template
Use this template to rapidly bootstrap a DL project: Write code in Pytorch Lightning's LightningModule and…
github.com
Transformers as Universal Computation Engines
Important paper to read if you are interested on how pretrained language models can be used to transfer its knowledge to other domains outside of NLP (i.e. vision, computing numbers etc.). Authors suggest that these models, that have kept their self-attention/feed forward layers frozen (without fine-tuning) can actually match the performance of a fully trained model trained on the downstream task.
Code:
kzl/universal-computation
Official codebase for Pretrained Transformers as Universal Computation Engines. Contains demo notebook and scripts to…
github.com
Paper:
Pretrained Transformers as Universal Computation Engines
We investigate the capability of a transformer pretrained on natural language to generalize to other modalities with…
arxiv.org
LineFlow: Dataset Loader
LineFlow is a framework agnostic dataset loader for NLP.
Tasks it supports:
- Commonsense Reasoning
- Language Modeling
- Machine Translation
- Paraphrase
- Question Answering
- Sentiment Analysis
- Sequence Tagging
- Text Summarization
tofunlp/lineflow
LineFlow is a simple text dataset loader for NLP deep learning tasks. LineFlow was designed to use in all deep learning…
github.com
Repo Cypher U+1F468U+1F4BB
A collection of recently released repos that caught our U+1F441
Information Extraction (in Julia)
Combining deep learning and context free grammars for information extraction
deepcpcfg/datasets
This repository contains supplementary materials for DeepCPCFG: Deep Learning and Context Free Grammars for End-to-End…
github.com
Connected Papers U+1F4C8
TypeShift (in R)
A UI that helps visualize how peeps type language on a keyboard. For example, was it fast or slow, differences across languages etc.
angoodkind/TypeShift
The task of "visualizing language production" is both broad and difficult to execute conclusively. Common…
github.com
Connected Papers U+1F4C8
MATH Dataset
A new dataset of 12,500 challenging competition math word problems. FYI, not the same as DeepMind’s Math dataset.
hendrycks/math
This is the repository for Measuring Mathematical Problem Solving With the MATH Dataset by Dan Hendrycks, Collin Burns…
github.com
Connected Papers U+1F4C8
Byte2Speech
Framework adopts the multi-lingual and multi-speaker transformer TTS framework in Yang & He (2020), and extends it to byte inputs.
mutiann/byte2speech
This is an implementation of the paper, based on the open-source Transformer-TTS. Audio samples of the paper is…
github.com
Connected Papers U+1F4C8
Rissanen Data Analysis
Rissanen Data Analysis (RDA) is a method to determine what capabilities are helpful to solve a dataset.
ethanjperez/rda
Rissanen Data Analysis (RDA) is a method to determine what capabilities are helpful to solve a dataset, as described…
github.com
Connected Papers U+1F4C8
MediaSum Dataset
Interview transcript dataset with abstractive summaries
zcgzcgzcg1/MediaSum
This large-scale media interview dataset contains 463.6K transcripts with abstractive summaries, collected from…
github.com
Connected Papers U+1F4C8
Dataset of the Week: Contract Understanding Atticus Dataset (CUAD)
What is it?
A corpus of 13,000+ labels in 510 commercial legal contracts that have been manually labeled under the supervision of experienced lawyers to identify 41 types of legal clauses that are considered important in contact review in connection with a corporate transaction, including mergers & acquisitions.
Sample
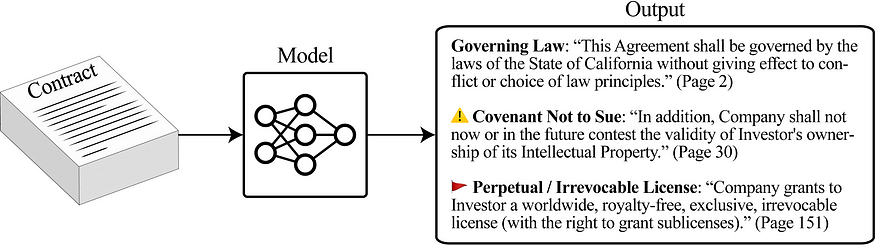
Where is it?
TheAtticusProject/cuad
This repository contains code for the Contract Understanding Atticus Dataset (CUAD), a dataset for legal contract…
github.com
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
For complete coverage, follow our Twitter: @Quantum_Stat
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

