



The LLM Series #1: The Fast Track to Fine-Tuning Mastery with Azure
Last Updated on January 30, 2024 by Editorial Team
Author(s): Muhammad Saad Uddin
Originally published on Towards AI.
Welcome, AI explorers! if you’ve ever struggled to fine-tune a large language model, you’re not alone. It’s often like trying to teach a cat to fetch — theoretically possible, but practically? Well, that’s another story U+1F605 . We will start with Azure, and I am going to show you how Azure isn’t just a pretty name with a cool logo. It’s the secret weapon you never knew you needed in your AI arsenal. We’ll dive into the nuts and bolts of Azure’s capabilities, showcasing how it can turn the often Herculean task of fine-tuning large language models into a walk in the park. Or at least, a manageable hike U+1F506 . So stay tuned and get ready to take the fast track to finetuning mastery!
We start with the basics first, I know many of you already know these concepts, but its never too late for a little refresher
What are LLMs
In simplest term, LLMs are type of generative AI that can recognize, generate, and even predict text based on the knowledge it has gained from its training from massive datasets.
How massive? GPT-3 was trained on somewhere between 570GB to 45TB of data and 570GB roughly translate to around 300 billion words!!!
large language models are like data sponges, absorbing and learning from billions of data points. It uses a neural network architecture known as a transformer model to do this. The underlying transformer is a set of neural networks that consist of an encoder and a decoder with self-attention capabilities. You can learn more about basic transformer architecture here.
What is finetuning
Finetuning involves taking an LLM that’s already been trained and adjusting it with a more specific, smaller dataset that’s tailored to specific task. LLMs are pre-trained to have a broad understanding of language, which means a significant portion of the developmental work is already completed. It’s like adding a layer of specialized knowledge to the solid base of general understanding that the LLM already has. This custom training helps the model become an expert in a specific field, whether that’s chatting, translating, summarizing, or anything else you need it to do.
Why finetuning
Fine-tuning is a crucial step in the optimization of pre-trained models like GPT, allowing them to specialize in specific tasks. A fitting analogy for this process is the transformation of a general-purpose vehicle into a high-performance race car.
Think of a pre-trained GPT model as a standard factory-made car. This car is designed for general use, performing well in everyday scenarios, much like how a GPT model is trained on a wide range of data. But if you plan to enter this car into a Formula One race, it wouldn’t perform as well as the specialized race cars that are “fine-tuned” for high-speed racing. To compete on a level playing field, your factory-made car would need to undergo significant modification. Just as a fine-tuned race car outperforms a factory-made car in a Formula One race, a fine-tuned LLM performs better in its specialized domain than a general LLM.
For best explanations of the various “W’s” related to fine tuning, I highly recommend checking out this outstanding piece penned by
Let’s begin with Azure OpenAI, before you can start fine-tuning, you need to fulfill the following prerequisites:
- An Azure subscription. if you don’t have one, you can create one here
- Access to Azure OpenAI subscription
Azure OpenAI Environment
The reason for selecting Azure OpenAI service was not only due to the availability of powerful language models, including the GPT-4, 3.5 Turbo, and Embeddings model series, but also because of the flexibility it offers in access via REST APIs, Python SDK, or web-based interface in the Azure OpenAI Studio. Another primary reason is that Microsoft guarantees that your personal or organizational data will not be shared or utilized for LLM training.
Lets get familiar with the environment. After getting the access, your resource page will appear like this:
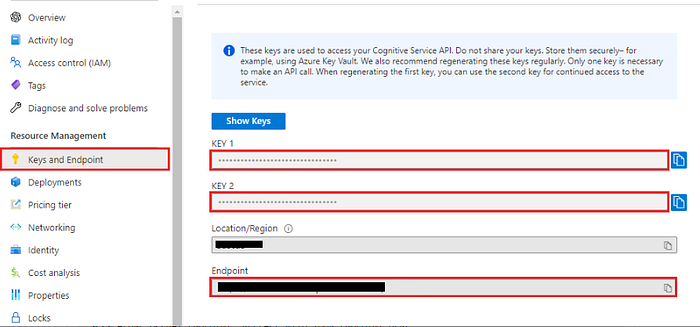
This page provides several options, including an overview of resources, access control for these resources, and details about keys and costs. If you intend to call or fine-tune your model via API, you’ll need the keys and endpoint details. However, as this article primarily focuses on minimal coding, most of our work will be conducted within the Azure OpenAI Studio’s web interface, which can be navigated from the overview page, as shown below:


There are multiple tabs, but our focus will primarily be on the ‘Deployments’ and ‘Models’ tabs for fine-tuning. The ‘Models’ tab contains both the available base models and the custom models that we fine-tune with our data and format. The ‘Deployments’ tab displays the model you’ve deployed from the list available in the ‘Models’ tab, as well as any custom deployments (Like one we will do in the next steps)
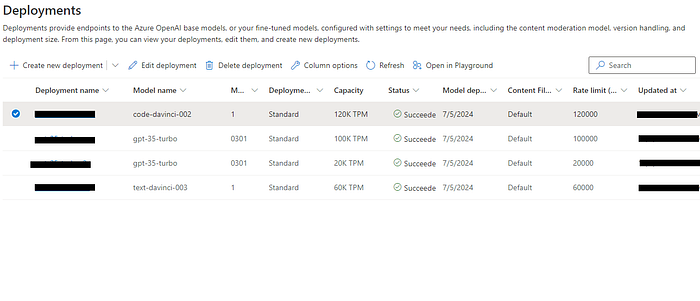
The ‘Deployments’ tab also provides an overview of the model version, token capacity, and options to create new base models or custom deployments
Creating the dataset
The next step involves creating the dataset for finetuning. This task cannot be performed directly in OpenAI Studio, as the finetuning job requires a specially formatted JSONL training file. While I will not add the details of data cleaning and quality checks here, always ensure to clean your data to create high quality examples, as low-quality examples can negatively impact the model’s performance
Just a summary of what I did here was import the dataset in python, clean it and convert it to required format for fine tuning as shown below.
{"messages": [{"role": "system", "content": "Your prompt to design model behaviour"}, {"role": "user", "content": "What?"}, {"role": "assistant", "content": "."}]}
{"messages": [{"role": "system", "content": "Your prompt to design model behaviour"}, {"role": "user", "content": "Who?"}, {"role": "assistant", "content": "?"}]}
{"messages": [{"role": "system", "content": "Your prompt to design model behaviour"}, {"role": "user", "content": "How?"}, {"role": "assistant", "content": "."}]}
This format includes 3 roles as system , user and assistant.
⮞ The ‘System’ role serves as the primary prompt to guide your model’s behavior throughout the conversation.
⮞ The ‘User’ role represents the type of questions a user may ask.
⮞ The ‘Assistant’ role reflects how the model should respond to a user’s query.
Based on this format, you’ll need to create two files training.jsonl and validation.jsonl One is used to fine-tune the model, and another to test its performance.
df = pd.read_json("training.jsonl", orient='records', lines=True)
dfv = pd.read_json("validation.jsonl", orient='records', lines=True)
We will then upload these files in the studio, and the remainder of the work will be done directly via the web interface. Just a suggestion that when fine-tuning a model on proprietary data, always ensure data quality and removal of Personally Identifiable Information (PII) data as privacy becomes a critical consideration and the model may inadvertently memorize and reproduce sensitive information.
Selecting the model
Within Azure Studio, the models available for fine-tuning include GPT-3.5-Turbo (0613 version), babbage-002, and davinci-002**. One thing to remember here is that GPT-3.5-Turbo (0613) is available in specific region and you may have to use a subscription in that region to utilize it (and always look for updates about new available regions)
** babbage-002 and davinci-002 are not trained to follow instructions.
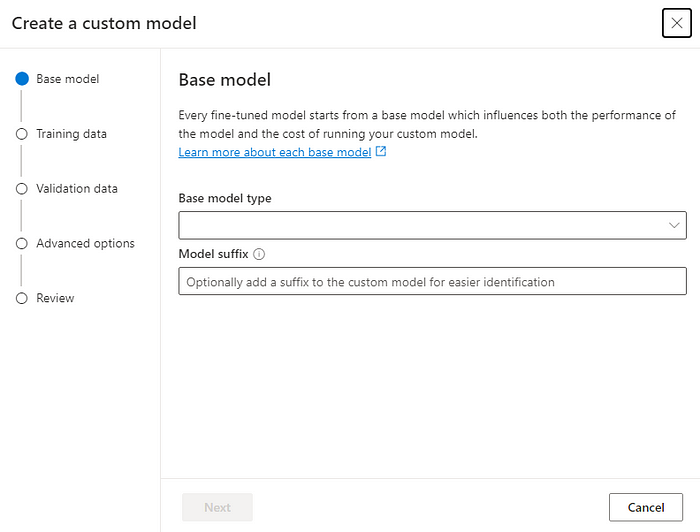
We will create the deployment from create a custom modeloption in the Models tab, which will pop up the above screen. We’ll select the newly available GPT-3.5-Turbo (0613) model and then choose the training and validation datasets we previously created in Python.


Performing Finetuning
In this next step, we focus on the crucial task of selecting hyperparameters for fine-tuning. These include:
epochs: how many iterations the model train for
batch size: number of training examples used to train a single pass
learning rate: fine tuning learning rate is the original learning rate used for pretraining multiplied by this value.
prompt loss weight: controls how much the model focuses on learning from the instructions given to it
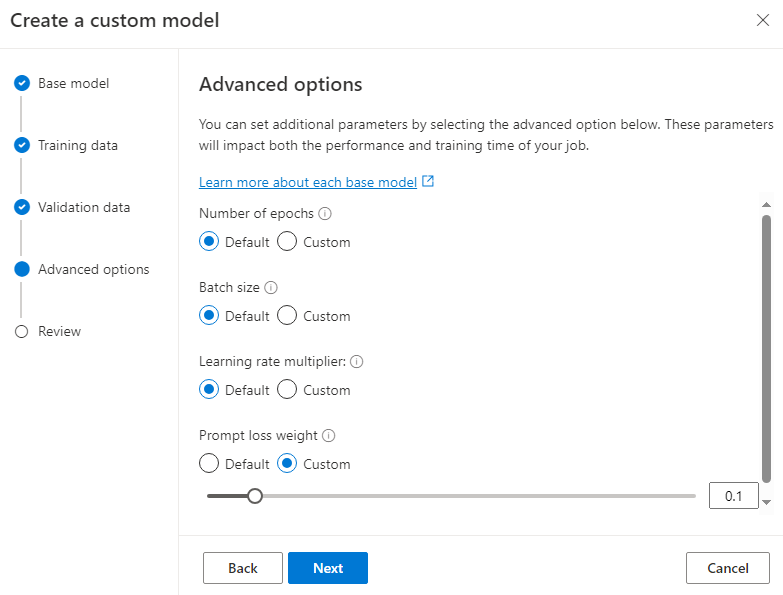

Once everything is set, we can start the finetuning job. The duration of this process will depend on the size of your dataset. In my case, it took around 4 hours as my dataset was quite small and I only queued it for fewer epochs. After the fine-tuning job is complete, we can review the metrics to gauge how our training went. As you can see, my finetuning job still has a lot of room for improvement.


If you’ve fine tuned different versions of a model or used different data, you can examine each instance separately, as shown below.

Deploying the Model
Lastly, we test a little with our fine-tuned model and if meets the expectations, we can deploy it for general use via + create new deployment the option in the Deployments tab. This will open a window where we can select our fine-tuned model, configure the rate limit, and select what kind of content to block via Content Filter.

and that’s all, TADA! our model is now ready to use. If you feel like this is too easy, or you have a developer mindset and want to perform all these steps via code, you can refer to this guide.
Also, don’t forget to share your experiences and methods on finetuning, as well as any intriguing tools or guides you’ve found useful in the comments section, so we all have the opportunity to learn from each other.
If you still feel like you need to learn more, here is the guide about best practices for deploying LLMs developed by OpenAI, Cohere and AI21 Best practices for deploying language models (openai.com)
That’s it for today, But don’t worry, the adventure continues! In the next chapter of the LLM series, we will have a look at the functional calling capabilities of GPT models. If this guide has sparked your curiosity and you wish to explore more exciting projects in this LLM series, make sure to follow me. With each new project, I promise a journey filled with learning, creativity, and fun. Furthermore:
- U+1F44F Clap for the story (50 claps) to help this article be featured
- U+1F514 Follow Me: LinkedIn U+007CMedium U+007C Website U+007C Got AI queries?
References
- Attention Is All you Need
- Google Researchers Got ChatGPT to Reveal Its Training Data, Study (businessinsider.com)
- To fine-tune or not to fine-tune. U+007C by Michiel De Koninck U+007C ML6team
- Best practices for deploying language models (openai.com)
- Azure OpenAI fine tuning tutorial
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

