


Scaling AI with Ray
Last Updated on August 1, 2023 by Editorial Team
Author(s): Luhui Hu
Originally published on Towards AI.
Ray is emerging in AI engineering and becomes essential to scale LLM and RL
Spark is almost essential in data engineering. And Ray is emerging in AI engineering.
Ray is a successor to Spark from UCB. Spark and Ray have many similarities, e.g., unified engines for computing. But Spark is mainly focused on large-scale data analytics, while Ray is designed for machine learning applications.
Here, I’ll introduce Ray and touch on how to scale large language models (LLM) and reinforcement learning (RL) with Ray, then wrap up with Ray’s nostalgia and trend.
Introduction to Ray
Ray is an open-source unified compute framework making it easy to scale AI and Python workloads, from reinforcement learning to deep learning to model tuning and serving.
Below is Ray's latest architecture. It mainly has three components: Ray Core, Ray AI Runtime, and Storage and Tracking.

Ray Core provides a small number of core primitives (i.e., tasks, actors, objects) for building and scaling distributed applications.
Ray AI Runtime (AIR) is a scalable and unified toolkit for ML applications. AIR enables simple scaling of individual workloads, end-to-end workflows, and popular ecosystem frameworks, all in just Python.
AIR builds on Ray’s best-in-class libraries for Preprocessing, Training, Tuning, Scoring, Serving, and Reinforcement Learning to bring together an ecosystem of integrations.
Ray enables seamless scaling of workloads from a laptop to a large cluster. A Ray cluster consists of a single head node and any number of connected worker nodes. The number of worker nodes may be autoscaled with application demand as specified by Ray cluster configuration. The head node runs the autoscaler.
We can submit jobs for execution on the Ray cluster or interactively use the cluster by connecting to the head node and running ray.init.
It’s simple to start and run Ray. The following will illustrate how to install it.
Install Ray
$ pip install ray
████████████████████████████████████████ 100%
Successfully installed ray
$ python
>>>import ray; ray.init()
... INFO worker.py:1509 -- Started a local Ray instance. View the dashboard at 127.0.0.1:8265 ...
Install Ray libraries
pip install -U "ray[air]" # installs Ray + dependencies for Ray AI Runtime
pip install -U "ray[tune]" # installs Ray + dependencies for Ray Tune
pip install -U "ray[rllib]" # installs Ray + dependencies for Ray RLlib
pip install -U "ray[serve]" # installs Ray + dependencies for Ray Serve
Furthermore, Ray can run at scale on Kubernetes and cloud VMs.
Scale LLM and RL with Ray
ChatGPT is a significant AI milestone with rapid growth and unprecedented impact. It is built on OpenAI’s GPT-3 family of large language models (LLM) employing Ray.
Greg Brockman, CTO and cofounder of OpenAI, said, At OpenAI, we are tackling some of the world’s most complex and demanding computational problems. Ray powers our solutions to the thorniest of these problems and allows us to iterate at scale much faster than we could before.
It takes about 25 days to train GPT-3 on 240 ml.p4d.24xlarge instances of the SageMaker training platform. The challenge is not just processing but also memory. Wu Tao 2.0 appears to need more than 1000 GPUs only to store its parameters.
Training ChatGPT, including large language models like GPT-3 requires substantial computational resources and is estimated to be in the tens of millions of dollars. By empowering ChatGPT, we can see the scalability of Ray.
Ray tries to tackle challenging ML problems. It supports training and serving reinforcement learning models from the beginning.
Let’s code in Python to see how to train a large-scale reinforcement learning model and serve it using Ray Serve.
Step 1: Install dependencies for reinforcement learning policy models.
!pip install -qU "ray[rllib,serve]" gym
Step 2: Define training, serving, evaluating, and querying a large-scale reinforcement learning policy model.
import gym
import numpy as np
import requests
# import Ray-related libs
from ray.air.checkpoint import Checkpoint
from ray.air.config import RunConfig
from ray.train.rl.rl_trainer import RLTrainer
from ray.air.config import ScalingConfig
from ray.train.rl.rl_predictor import RLPredictor
from ray.air.result import Result
from ray.serve import PredictorDeployment
from ray import serve
from ray.tune.tuner import Tuner
# train API for RL by specifying num_workers and use_gpu
def train_rl_ppo_online(num_workers: int, use_gpu: bool = False) -> Result:
print("Starting online training")
trainer = RLTrainer(
run_config=RunConfig(stop={"training_iteration": 5}),
scaling_config=ScalingConfig(num_workers=num_workers, use_gpu=use_gpu),
algorithm="PPO",
config={
"env": "CartPole-v1",
"framework": "tf",
},
)
tuner = Tuner(
trainer,
_tuner_kwargs={"checkpoint_at_end": True},
)
result = tuner.fit()[0]
return result
# serve RL model
def serve_rl_model(checkpoint: Checkpoint, name="RLModel") -> str:
""" Serve an RL model and return deployment URI.
This function will start Ray Serve and deploy a model wrapper
that loads the RL checkpoint into an RLPredictor.
"""
serve.run(
PredictorDeployment.options(name=name).bind(
RLPredictor, checkpoint
)
)
return f"http://localhost:8000/"
# evaluate RL policy
def evaluate_served_policy(endpoint_uri: str, num_episodes: int = 3) -> list:
""" Evaluate a served RL policy on a local environment.
This function will create an RL environment and step through it.
To obtain the actions, it will query the deployed RL model.
"""
env = gym.make("CartPole-v1")
rewards = []
for i in range(num_episodes):
obs = env.reset()
reward = 0.0
done = False
while not done:
action = query_action(endpoint_uri, obs)
obs, r, done, _ = env.step(action)
reward += r
rewards.append(reward)
return rewards
# query API on the RL endpoint
def query_action(endpoint_uri: str, obs: np.ndarray):
""" Perform inference on a served RL model.
This will send an HTTP request to the Ray Serve endpoint of the served
RL policy model and return the result.
"""
action_dict = requests.post(endpoint_uri, json={"array": obs.tolist()}).json()
return action_dict
Step 3: Now train the model, serve it using Ray Serve, evaluate the served model, and finally shut down Ray Serve.
# training in 20 workers using GPU
result = train_rl_ppo_online(num_workers=20, use_gpu=True)
# serving
endpoint_uri = serve_rl_model(result.checkpoint)
# evaluating
rewards = evaluate_served_policy(endpoint_uri=endpoint_uri)
# shutdown
serve.shutdown()
Ray Nostalgia and Trend
Ray was initiated as a research project at RISELab of UCB. RISELab is the successor of AMPLab, where Spark was born.
Professor Ion Stoica is the soul of Spark and Ray. He initiated to found Databricks with Spark and Anyscale with Ray as their core products.
I was privileged to work with RISELab fellows in its early stage and witnessed Ray come into being.

Above is Ray’s project post in 2017. We can see it was elegantly simple but scalably powerful for AI applications.
Ray is a stellar ship, proliferating. It is one of the fastest-growing open sources, as shown by the number of Github stars below.
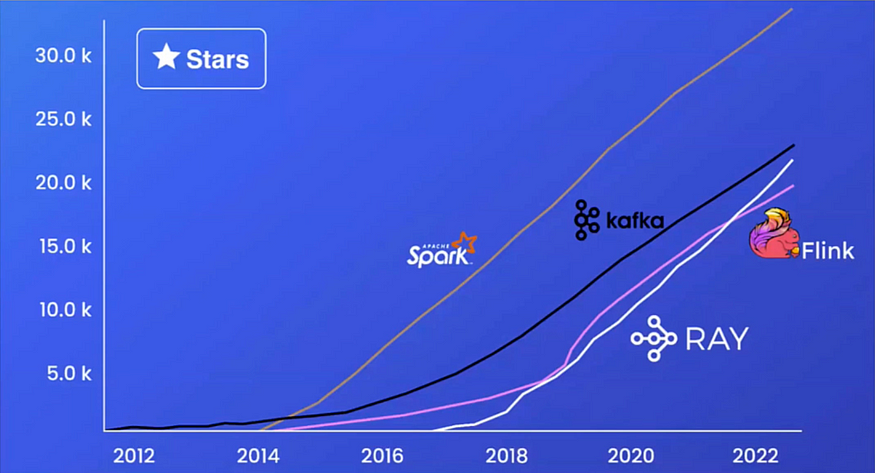
Ray is emerging in AI engineering and is an essential tool to scale LLM and RL. Ray is positioned for the massive AI opportunities ahead.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

