



PySpark process Multi char Delimiter Dataset
Last Updated on July 19, 2023 by Editorial Team
Author(s): Vivek Chaudhary
Originally published on Towards AI.
Programming
The objective of this article is to process multiple delimited files using Apache spark with Python Programming language. This is a real-time scenario where an application can share multiple delimited file,s and the Dev Team has to process the same. We will learn how we can handle the challenge.
The input Data set is as below:
Name@@#Age <--Header
vivek, chaudhary@@#30 <--row1
john, morgan@@#28 <--row2
Approach1: Let’s try to read the file using read.csv() and see the output:
from pyspark.sql import SparkSessionfrom pyspark.sql import SparkSession
spark= SparkSession.builder.appName(‘multiple_delimiter’).getOrCreate()test_df=spark.read.csv(‘D:\python_coding\pyspark_tutorial\multiple_delimiter.csv’)
test_df.show()
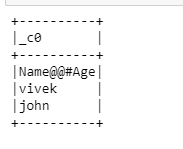
#Note: Output is not the desired one and so the processing will not yield the desired results
Approach2: Next, read the file using read.csv() with option() parameter and pass the delimiter as an argument having the value ‘@@#’ and see the output:
test_df=spark.read.option(‘delimiter’,’@@#’).csv(‘D:\python_coding\pyspark_tutorial\multiple_delimiter.csv’)test_df.show(truncate=0)
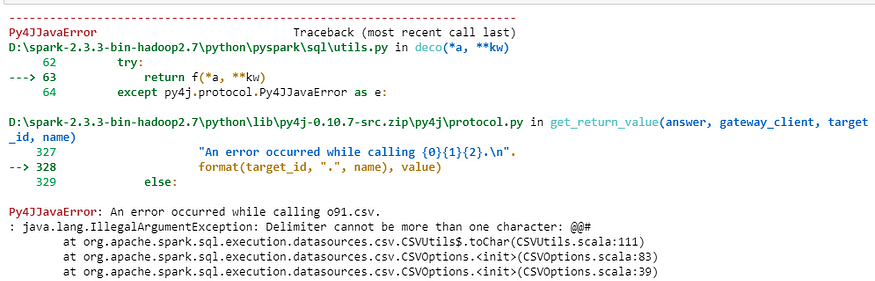
#Note: spark throws error when we try to pass delimiter of more than one character.
Approach3: Next way is to use read.text() method of spark.
mult_df=spark.read.text(‘D:\python_coding\pyspark_tutorial\multiple_delimiter.csv’)
mult_df.show(truncate=0)
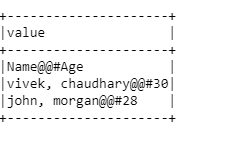
#Note: spark.read.text returns a DataFrame.
Each line in a text file represents a record in DataFrame with just one column “value”. To convert into multiple columns, we will use map transformation and split method to transform and split the column values.
#first() returns the first record of dataset
header=mult_df.first()[0]
print(header)
Output:
Name@@#Age#split('delimiter') the string on basis of the delimiter
#define the schema of the Dataframe to be createdschema=header.split(‘@@#’)
print(schema)Output:
['Name', 'Age']
The next step is to split the row and create separate columns:
#filter operation is removing the header
#map operation is splitting each record as per delimiter
#.rdd converts DF to rdd and toDF converts the rdd back to DFmult_df.filter(mult_df[‘value’]!=header).rdd.map(lambda x:x[0].split(‘@@#’)).toDF(schema).show()

Hurray!! We are able to split the data on the basis of multiple delimiter ‘@@#’.
Summary:
· Read Multiple Delimited Dataset using spark.read.text() method
· use of map(), filter() transformations
Thanks to all for reading my blog, and If you like my content and explanation, please follow me on medium and share your feedback, which will always help all of us to enhance our knowledge.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

