



Paper Review: Multimodal Chain of Thought Reasoning
Last Updated on July 17, 2023 by Editorial Team
Author(s): Building Blocks
Originally published on Towards AI.
Language Models improve with Visual Features
One of the cool emergent features of Large Language Models (LLMs) is their ability to perform better on reasoning tasks such as arithmetic problems, common sense reasoning, etc., when the sentence “Let’s think step by step” is added to a prompt.
Along the same lines, a lot of research has also shown that including a few examples of how a problem can be solved by breaking it down into steps and including the reasoning in the prompt before asking a question that requires similar reasoning helps LLMs better solve the question.
For example, take a look at the image below, where an example and solution to an arithmetic problem are included in the prompt of the LLM.
This idea of using a chain of statements explaining how one can arrive at the answer to a question/problem to “prime” an LLM is called Chain of Thought Reasoning (CoT).
If you’ve ever wondered why responses from ChatGPT can sometimes be overly verbose, especially when asked arithmetic questions, it's because, under the hood, the model is using CoT to arrive at the answer. For example, look at ChatGPT’s response to the question below.

Now there have been some dubious rumors of GPT-4 being multimodal. While these rumors may or may not carry much weight, a team at Amazon has released a paper that shows augmenting Visual Features with Language Models (LMs) can help improve CoT in multimodal tasks such as question answering. Today’s article will cover the findings from the paper Multimodal Chain-of-Thought Reasoning in Language Models linked here.
Learnings from the paper
The authors of Multimodal Chain-of-Thought Reasoning in Language Models show the following:
- How LM’s with less than 1 Billion parameters can effectively leverage CoT.
- How Visual Features can be combined with the text features produced by an LM to help with multimodal reasoning.
- A two-step process of generating the rationale followed by generating the answer is more effective than a one-stage process of producing the rationale and answer together.
CoT and models with fewer than 1 Billion Parameters
It’s been observed that smaller models tend to make up things more often than larger models do. This is often referred to as hallucination.
This paper concluded that CoT-based prompting only helps when models have at least 100 billion parameters!
That is, chain-of-thought prompting does not positively impact performance for small models, and only yields performance gains when used with models of ∼100B parameters.
The authors also observed a very high rate of hallucination when they trained the UnifiedQA (a T5 model trained on a bunch of Question Answering datasets) model to generate the rationales/reasoning. They randomly sample 50 cases (note that this is a very small sample size) where the model predicts the wrong answer to a question and observe that in 64% of the cases, the rationales contained hallucinations.

Dataset
In this paper, the authors focus on creating a model that can help with multimodal question answering as opposed to text-only question answering. The dataset in focus is ScienceQA. The dataset can have images and text as a part of the context and also contain explanations for an answer so that models can be fine-tuned to generate CoT/rationales.
ScienceQA is collected from elementary and high school science curricula, and contains 21,208 multimodal multiple-choice science questions. Out of the questions in ScienceQA, 10,332 (48.7%) have an image context, 10,220 (48.2%) have a text context, and 6,532 (30.8%) have both.
Use of Visual Features
As we’ve seen that smaller LMs are prone to hallucinations when they generate their CoT/rationale, the authors speculate that having a modified architecture where the model can leverage the text features produced by an LM and Visual Features produced by an image model would be more equipped at producing rationales and answering the questions.
The authors make use of visual features generated by the DETR model.
Multimodal CoT
The authors propose having two stages:
- Use text (question + context) and visual features to produce a rationale.
- Use the produced original question + context + rationale produced from step 1+ visual features to produce an answer.
Both steps 1 and 2 go through the same model architecture. This idea is summarized in the image below. Essentially there are two forward passes, each forward pass has a different input and output as explained above.

Architecture
Overall, we need a model that can produce text features and visual features and leverage them to generate a textual response.
However, it is important for there to be some interaction between the textual and visual features, essentially some sort of co-attention mechanism. This helps in encapsulating the information present in both modalities.
To accomplish all of that, the authors choose a T5 model, which has an encoder-decoder architecture and, as stated above, the DETR model to produce visual features.
The encoder of the T5 model takes care of producing textual features. However, instead of leveraging the textual features produced by the encoder, the decoder of the T5 model instead uses the output of a co-attention-styled interaction layer that the authors propose.
Interaction between Visual and Textual Features
Assume that H_language is the output of the T5 encoder. X_vision is the output of DETR. The first step is to ensure that the visual features and the textual features have the same hidden size so that we can use an attention layer.
Note: All code snippets are from the repo:
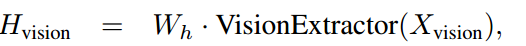
self.image_dense = nn.Linear(self.patch_dim, config.d_model)
W_h is essentially a linear layer, and H_vision corresponds to the final visual features. W_h helps in changing the size of the visual features to match that of the textual features.
Next, we need to add an attention layer so that the visual and textual features can interact with each other. For this, the authors use a single-headed attention layer with H_language as the query vector and H_vision as the key and value vectors.
self.mha_layer = torch.nn.MultiheadAttention(embed_dim=config.hidden_size,
kdim=config.hidden_size, vdim=config.hidden_size,
num_heads=1, batch_first=True)
image_att, _ = self.mha_layer(hidden_states, image_embedding, image_embedding)
Now we have embeddings that contain information from both the textual and visual features. The authors then leverage gated fusion to produce the final set of features that’ll be sent to the decoder.
Gated fusion has two steps:
- Obtain a vector of scores between 0 and 1 to determine the importance of each of the attention features.
- Use the score to fuse the text and attention features.

W_l and W_v are essentially two linear layers.
self.gate_dense = nn.Linear(2*config.hidden_size, config.hidden_size)
self.sigmoid = nn.Sigmoid()
hidden_states = encoder_outputs[0]
merge = torch.cat([hidden_states, image_att], dim=-1)
gate = self.sigmoid(self.gate_dense(merge))
hidden_states = (1 - gate) * hidden_states + gate * image_att
Finally, the fused features are passed to the decoder.
decoder_outputs = self.decoder( input_ids=decoder_input_ids,
attention_mask=decoder_attention_mask,
inputs_embeds=decoder_inputs_embeds,
past_key_values=past_key_values,
encoder_hidden_states=hidden_states,
That’s pretty much the architecture that the authors follow! However, remember that there are two stages. The first stage is to produce the rationale/CoT. The second stage leverages the CoT produced in the first stage to produce the answer, as shown in the image above.
Results
The authors use the UnifiedQA model’s weights as the initialization point for the T5 model and fine-tune it on the ScienceQA dataset. They observe that their Multimodal CoT method outperforms all previous benchmarks, including GPT-3.5.
Interestingly even the base model which has only 223 million parameters, outperforms GPT-3.5 and other Visual QA models! This highlights the power of having a multimodal architecture.

The authors also show that their two-stage approach outperforms a single-staged approach.

Conclusion
The biggest takeaway from this paper is how powerful multimodal features can be in solving problems that have visual and textual features.
The authors show that with visual features, even small LMs can produce meaningful Chains of Thought/reasoning with much less hallucination, which brings to light the role vision models can play in evolving CoT-based learning techniques.
From their experiments, we see that adding visual features that come at the cost of a few million parameters brings much greater value than scaling up a text-only model by billions of parameters.
If you have any thoughts, drop a comment below. Until the next time, take care and be kind.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


