


NLP News Cypher | 09.27.20
Last Updated on July 24, 2023 by Editorial Team
Author(s): Ricky Costa
Originally published on Towards AI.
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
NLP News Cypher U+007C 09.27.20
Legends
Hey…welcome back! Loads of research came out this week! But FYI, we couldn’t fit every story in this newsletter for space-saving reasons, so if you want complete coverage, follow our twitter, and as always, if you enjoy the read, please give it a U+1F44FU+1F44F and share with your enemies.
And….yesterday, another update was made to the Super Duper NLP Repo and the Big Bad NLP Database: we added 10 datasets and 5 new notebooks. Highlights include the DialogRE dataset which may be the first human-annotated dialogue-based relation extraction dataset. And the FarsTail dataset, a Persian language NLI dataset. U+1F60E
U+1F441 Random Tales from the Dark Web U+1F441
Legend has it there’s a bitcoin wallet worth $690 million that hackers have been attempting to crack for the past 2 years according to cybersecurity expert Alon Gal. The wallet’s .dat file contains a very tough encryption and it is all of what stands between hackers and a potential big pay-day. But some say this is all nonsense, and the veracity of this claim is questionable, but who knows…U+1F937U+2642️. Recently there’s been a “thriving market for selling uncracked wallets” on the dark web according to Gal. It may be our lottery ticket out of the matrix!
Oh, I’m not joking… U+1F447
GPT-3 Goes Corporate
Microsoft’s $1B investment in OpenAI paid off. Microsoft announced it will receive an exclusive license for GPT-3 for its own products. U+1F9D0
Microsoft teams up with OpenAI to exclusively license GPT-3 language model – The Official Microsoft…
One of the most gratifying parts of my job at Microsoft is being able to witness and influence the intersection of…
blogs.microsoft.com
Graphs Revisited
Last week we mentioned a knowledge graph paper and showed a graphic showing the difference between a KG triple vs. a hyper-relational graph. And it turns out, Galkin wrote a blog post about it (includes code link). Read about it here:
Representation Learning on RDF* and LPG Knowledge Graphs
Hyper-relational KGs encode more knowledge than triple KGs. We adopt recent advances in Graph ML and propose a GNN…
towardsdatascience.com
An Abstraction of the ML World
Bloomberg’s Data Annotation Guidelines U+1F62C
This Week
BERT is Still a Light Weight
Dynabench
A New Method for NLU in Task-Oriented Chatbots
Wav2vec 2.0
Google Recommends It
X-LXMERT
Honorable Mentions
Dataset of the Week: QED
BERT is Still a Light Weight
pQRNN is a new NLP model released by Google that builds on top of PRADO. This is a super light model holding only 1.4M parameters vs. the 440M BERT we are accustomed to, AND, without losing much accuracy when benchmarked against the civil_comments dataset. Super light models are very important if you are concerned about online inference and edge computing. PRADO is open sourced.
Blog:
Advancing NLP with Efficient Projection-Based Model Architectures
Deep neural networks have radically transformed natural language processing (NLP) in the last decade, primarily through…
ai.googleblog.com
Dynabench
Facebook introduced a new benchmark called Dynabench, which puts humans and models “in the loop” to measure how often models make mistakes when humans attempt to fool them.
Wait, what does this do exactly? (From their homepage)
The basic idea is that we collect data dynamically. Humans are tasked with finding adversarial examples that fool current state-of-the-art models. This offers two benefits: it allows us to gauge how good our current SOTA methods really are; and it yields data that may be used to further train even stronger SOTA models. The process is repeated over multiple rounds: each time a round gets “solved” by the SOTA, we can take those models and adversarially collect a new dataset where they fail. Datasets will be released periodically as new examples are collected.
If you are able to fool the model, that instance is passed on to the next round dataset to put more pressure on the model’s accuracy and ultimately making that dataset/model more robust. Datasets don’t stay static and your model improves over time. U+1F525U+1F525
Dynabench
Dynabench
Dynabenchdynabench.org
A New Method for NLU in Task-Oriented Chatbots
What’s the temperature going to be like when I get coffee with Megan?
If you know how to build task-oriented chatbots, you know the above question can be tricky for your model to answer accurately. And your first instinct may want to jump straight to slot-filling. But what Semantic Machines’ new paper tells us, is that there is a better way… by using a dataflow graph:
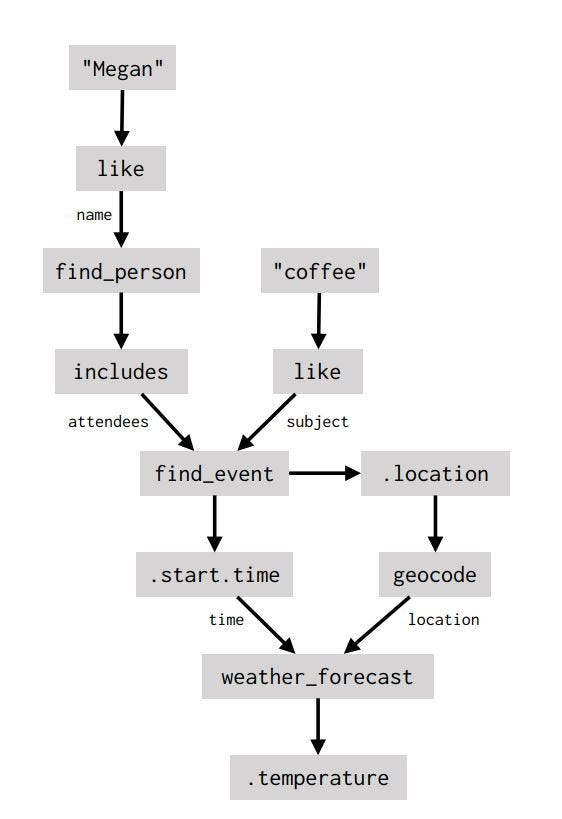
Their model is a new approach to NLU! Traditionally, a task-oriented chatbot would include an NLU module, state tracking, and dialogue policy as separate modules, but their new method predicts agent actions and logs them in a graph inside a single model. This is a new direction in the field and it’s very exciting!
In addition, they also released a new dataset called SMCalFlow, that holds over 41,517 conversations annotated with dataflow programs! This dataset has been added to the Big Bad NLP Database.
Blog:
Enlisting dataflow graphs to improve conversational AI
"Easier said than done." These four words reflect the promise of conversational AI. It takes just seconds to ask When…
www.microsoft.com
Paper: https://www.mitpressjournals.org/doi/pdf/10.1162/tacl_a_00333
Wav2vec 2.0
Facebook released Wav2vec 2.0 this week, a framework built on the trendy self-supervised learning method, and adapted it to raw audio data. It includes pre-trained models, and according to their paper, it’s robust:
“Our experiments show the large potential of pre-training on unlabeled data for speech processing: when using only 10 minutes of labeled training data, or 48 recordings of 12.5 seconds on average, we achieve a WER of 5.2/8.6 on test-clean/other of Librispeech.”
GitHub:
pytorch/fairseq
wav2vec 2.0 learns speech representations on unlabeled data as described in wav2vec 2.0: A Framework for…
github.com
Google Recommends It
!pip install tensorflow_recommenders
Well this is cool, TensorFlow has a new recommender system library: TensorFlow Recommenders (TFRS). Their blog post shows an example on how you can use the library to build a movie recommender system based on the MovieLens dataset. Their example follows a two-tower model where they use two sub-models that learn representations for queries and candidates separately.
Blog:
Introducing TensorFlow Recommenders
September 23, 2020 – Posted by Maciej Kula and James Chen, Google Brain From recommending movies or restaurants to…
blog.tensorflow.org
GitHub:
tensorflow/recommenders
TensorFlow Recommenders is a library for building recommender system models using TensorFlow. It helps with the full…
github.com
X-LXMERT
From AI2, their new text-to-image model is out: X-LXMERT. It generates images based on textual prompts. And their results are sort of surreal and a have a melting clock Dali-like quality to them! Just don’t take any psychedelics prior to engaging with their demo:
Computer Vision Explorer
The AI2 Computer Vision Explorer offers demos of a variety of popular models – try, compare, and evaluate with your own…
vision-explorer.allenai.org
Samples:

Blog:
X-LXMERT: Paint, Caption and Answer Questions with Multi-Modal Transformers
Recent multi-modal transformers have achieved tate of the art performance on a variety of multimodal discriminative…
prior.allenai.org
Paper: https://arxiv.org/pdf/2009.11278.pdf
Honorable Mentions
Long Survey on current visual and language research
COMET— Machine Translation Evaluation Framework
Unbabel/COMET
Note: This is a Pre-Release Version. We are currently working on results for the WMT2020 shared task and will likely…
github.com
Dataset Cartography
Dataset of the Week: QED
What is it?
Given a question and a passage, QED represents an explanation of the answer as a combination of discrete, human-interpretable steps: sentence selection, referential equality, and predicate entailment. Dataset was built as a subset of the Natural Questions dataset.
Sample:

Where is it?
google-research-datasets/QED
This page contains the data and evaluation scripts associated with the paper: https://arxiv.org/abs/2009.06354 QED: A…
github.com
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
For complete coverage, follow our Twitter: @Quantum_Stat
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

