



NLP News Cypher | 09.06.20
Last Updated on July 24, 2023 by Editorial Team
Author(s): Ricky Costa
Originally published on Towards AI.
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
NLP News Cypher U+007C 09.06.20
Revival
Welcome back, and what a week?!?! Time to say goodbye to Summer. U+1F631 Oh, and please don’t forget to give this page a U+1F44FU+1F44F if you enjoy the read! U+1F60E
Update: we added 20+ datasets and 10+ notebooks. (will make these weekly updates from now on). In addition, we optimized the databases’ performance in case you require to review our data from 100K ft. in the air.

Oh, and if you missed Elon’s AI brainchip meetup, here’s the highlight:
<Random hacker stuff>: dark.fail indexes the dark (dank) web. They have a Twitter accountU+1F9D0 . And they give updates on what’s going on in Tor land. And if you don’t frequently travel to the dark web like a good citizen, you may not know that onion sites go down a lot. Often from DDoS attacks. As a result, admins main concern is keeping these sites up as much as possible, well here’s some of the source code used to prevent you from sweating bullets:
P.S. It comes with the scariest Twitter image card of all time…
This Week
Deep Translator
Quantize Your Models
BioMedical NLP
QuestGen Library
Graph Neural Networks
Training Multiple GPUs with AllenNLP Library
AMBERT — ByteDance’s Language Model
Software Updates
Dataset of the Week: Visual Commonsense Graphs
Deep Translator
A neat translator repo that combines some of the most well known API’s for translation! Currently it supports:
- google translate
- Pons translator
- Linguee translator
- Mymemory translator
- Yandex translator (version >= 1.2.1)
- QCRI translator (version >= 1.2.4)
- DeepL translator (version >= 1.2.5)
GitHub:
nidhaloff/deep_translator
A flexible FREE and UNLIMITED tool to translate between different languages in a simple way using multiple translators…
github.com
Quantize Your Models
ONNX runtime support for the Transformers library now can incorporate quantization! In a recent blog post, Yufeng Li discusses this compression technique and how awesome it is to reduce latency on your models in production!! Quantizing your model just requires you to add a new argument to their script found here:
P.S. this will give you both the full precision and the quantized model…
python convert_graph_to_onnx.py --framework pt --model bert-base-uncased --quantize bert-base-uncased.onnx
P.S. models greater than 2GBs are currently not supported for quantization but according to author, they will be soon…U+1F60E
Blog:
Faster and smaller quantized NLP with Hugging Face and ONNX Runtime
Popular Hugging Face Transformer models (BERT, GPT-2, etc) can be shrunk and accelerated with ONNX Runtime quantization…
medium.com
Talking about ONNX…
Suraj Patil created this awesome repo that incorporates the ONNX script with the Hugging Face pipeline framework. So you can just call their models and it already incorporates the onnx graph U+1F525U+1F525U+1F525!!!
from onnx_transformers import pipelinenlp = pipeline("sentiment-analysis", onnx=True)U+1F440
nlp("Transformers and onnx runtime is an awesome combo!")
GitHub:
patil-suraj/onnx_transformers
Accelerated NLP pipelines for fast inference U+1F680 on CPU. Built with U+1F917 Transformers and ONNX runtime. pip install…
github.com
BioMedical NLP
Interested in language models for biomedical NLP? Microsoft created the first leaderboard BLURB which includes their SOTA PubMedBERT models and several biomedical datasets. Check it out here U+1F447
BLURB Leaderboard
The Overall score is calculated as the macro-average performance over tasks. Details can be found within our…
microsoft.github.io
Blog:
Domain-specific language model pretraining for biomedical natural language processing – Microsoft…
COVID-19 highlights a perennial problem facing scientists around the globe: how do we stay up to date with the cutting…
www.microsoft.com
QuestGen Library
If your mission is to generate questions from text, check out QuestGen AI repo.
Possible use-cases:
- Generating questions for a dataset.
- Use it to create online educational material that poses questions to students.
FYI, it uses the T5 model for encoding/decoding.
It currently supports generating these types of questions:
1. Multiple Choice Questions (MCQs)
2. Boolean Questions (Yes/No)
3. General FAQs
4. Paraphrasing any Question
5. Question Answering.
GitHub:
ramsrigouthamg/Questgen.ai
https://questgen.ai/ Questgen AI is an opensource NLP library focused on developing easy to use Question generation…
github.com
Graph Neural Networks
Here’s an awesome introduction to graph neural networks.
Includes colab notebooks in part 2 that goes over message-passing GCN’s. Probably the most used type of graph out there.
Part 1 – Introduction to Graph Neural Networks with GatedGCN
Graph Representation Learning is the task of effectively summarizing the structure of a graph in a low dimensional…
app.wandb.ai
Part 2 – Comparing Message Passing Based GNN Architectures
Before going through this report, I suggest the readers check out Part 1 – Intro to Graph Neural Networks with GatedGCN…
app.wandb.ai
Training Multiple GPUs with AllenNLP Library
Checkout how to implement AllenNLP’s distributed training with torch.distributed (which runs a separate Python process for each GPU, avoiding GIL U+1F601). Their blog post shows how easy it is to convert their config file (for distributed training) by adding:
"distributed": {
"cuda_devices": [0, 1, 2, 3],
}
Blog:
Tutorial: How to train with multiple GPUs in AllenNLP
This is part of a series of mini-tutorials to help you with various aspects of the AllenNLP library.
medium.com
AMBERT — ByteDance’s Language Model
As the lights go out on Broadway, and TikTok (in the US) sunsets due to international beef, ByteDance (TikTok’s parent comp.) came out with its own language model called AMBERT. It comes supported for both fine-grained and coarse-grained tokenizations. A friendly good bye to TikTok. U+1F60F
Software Updates
Hugging Face:
Releases · huggingface/transformers
The Pegasus model from PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization by Jingqing…
github.com
DeepPavlov:
It All Started With A Dream
At DeepPavlov, we have a Dream. Our Dream is to make AI assistants to improve the lives of every human. Whatever we…
deeppavlov.ai
Deep Graph Library (DGL):
https://www.dgl.ai/release/2020/08/26/release.html
Talking about graphs U+1F60E:
Dataset of the Week: Visual Commonsense Graphs
What is it?
Dataset consists of over 1.4 million textual descriptions of visual commonsense inferences carefully annotated over a diverse set of 59,000 images, each paired with short video summaries of before and after.
Sample:
https://homes.cs.washington.edu/~jspark96/visualcomet/
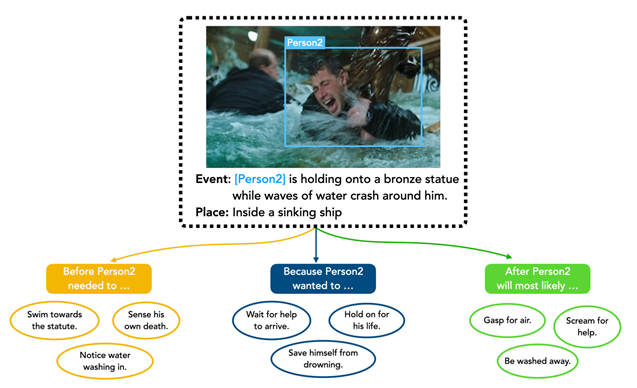
Where is it?
jamespark3922/visual-comet
PyTorch Code and Dataset Release for VisualCOMET: Reasoning about the Dynamic Context of a Still Image. For more info…
github.com
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
If you enjoyed this article, help us out and share with friends!
For complete coverage, follow our Twitter: @Quantum_Stat
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

