


NLP News Cypher | 08.09.20
Last Updated on July 24, 2023 by Editorial Team
Author(s): Ricky Costa
Originally published on Towards AI.
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
NLP News Cypher U+007C 08.09.20
Forge
Where are we? What is the state of NLP? Are we anywhere where we want to be? GPT-3 hype is cool but needs fine-tuning to be anywhere near production-ready. Where are those graphs? How are downstream tasks being used in the enterprise? What about sparse networks? Why do so many AI projects fail? Deep learning and semantic parsing, do we still care about information extraction? Are transformers the holy grail? Where is Lex Fridman (and his dark suit)? Where are those commonsense reasoning demos?
So… where are we….
Elon?
Go big and get into the NSA… start here U+1F447
CryptoHack – Home
A fun platform to learn about cryptography through solving challenges and cracking insecure code. Can you reach the top…
cryptohack.org
An index of NLP indexes:
ivan-bilan/The-NLP-Pandect
This pandect ( πανδέκτης is Ancient Greek for encyclopedia) was created to help you find almost anything related to…
github.com
This Week
DeLighT Transformers
NLP Beyond English
Stanza Update
PyKEEN: Knowledge Graph Embeddings Library
BigBird
ONNXT5
Kite Auto Complete
Dataset of the Week: SPLASH
DeLighT Transformers
DeLighT transformer library gives us a new look at the most popular model in NLP — the transformer. The new architecture helps reduce parameter size in addition to making models deeper. Which means this new architecture can match or achieve better results with the traditional transformer architecture but is much lighter. As of right now, the architecture can help with language modeling and machine translation. According to the authors, more tasks are on the way.
Paper: https://arxiv.org/pdf/2008.00623v1.pdf
GitHub:
sacmehta/delight
This repository contains the source code of our work on building efficient sequence models: DeFINE (ICLR'20) and…
github.com
NLP Beyond English
Sebastian Ruder opines on the state of NLP and specifically, how our limitations with low resource languages are a much bigger problem we should be focusing on. His blog post discusses the different areas of impact from societal to cognitive road-blocks on the lack of these datasets. Below are the bullet-points from the blog on what you can do to help.
What you can do
“Datasets If you create a new dataset, reserve half of your annotation budget for creating the same size dataset in another language.
Evaluation If you are interested in a particular task, consider evaluating your model on the same task in a different language. For an overview of some tasks, see NLP Progress or our XTREME benchmark.
Bender Rule State the language you are working on.
Assumptions Are explicit about the signals your model uses and the assumptions it makes. Consider which are specific to the language you are studying and which might be more general.
Language diversity Estimate the language diversity of the sample of languages you are studying (Ponti et al., 2020).
Research Work on methods that address the challenges of low-resource languages. In the next post, I will outline interesting research directions and opportunities in multilingual NLP.”
Blog:
Why You Should Do NLP Beyond English
Natural language processing (NLP) research predominantly focuses on developing methods that work well for English…
ruder.io
Stanza Update
Stanford’s Stanza updated its library to include support for the medical/clinical domain including:
- Bio pipelines and NER models, which specialize in processing biomedical literature text;
- A clinical pipeline and NER models, which specialize in processing clinical text.
Demo: http://stanza.run/bio
PyKEEN: Knowledge Graph Embeddings Library
This new graph library comes packed with models and datasets. It comes with a handy pipeline API which really simplifies the initialization of models and datasets. At the moment there’s 13 datasets and 23 models to play with.
Here’s a quick example:
from pykeen.pipeline import pipeline
result = pipeline(
model='TransE',
dataset='nations',
)
GitHub:
pykeen/pykeen
PyKEEN ( Python Knowl Edge Embeddi N gs) is a Python package designed to train and evaluate knowledge graph embedding…
github.com
Paper: https://arxiv.org/pdf/2007.14175.pdf
BigBird
We all know of the hard stop of 512 token limitations of BERT. And this annoyance is one of the main reasons why BigBird was created.
This new design helps to scale performance “to much longer sequence lengths (8x) on standard hardware (∼16GB memory) for large size models.” U+1F9D0
The cool thing about BigBird is because it leverages a sparse attention framework, it can do more with less. Meaning, it has less memory overhead (even versus other long context models like the Longformer).
The paper shows how it performs for both encoder only and encoder-decoder scenarios.
Performance-wise it offers SOTA on question answering and long document summarization.
ONNXT5
Someone helped to bridge the T5 model with ONNX (for inference speedup)U+1F60E . You can get up to 4X speed improvement over PyTorch as long as you keep your context length relatively short (around <500 words).
GitHub:
abelriboulot/onnxt5
Summarization, translation, Q&A, text generation and more at blazing speed using a T5 version implemented in ONNX. This…
github.com
Kite Auto Complete
For all the Jupyter notebook fans, Kite code autocomplete is now supported!
Kite brings its AI-powered code completions to Jupyter notebooks
Kite, which suggests code snippets for developers in real time, today debuted integration with JupyterLab and support…
venturebeat.com
Dataset of the Week: SPLASH
What is it?
SPLASH is a dataset for the task of semantic parse correction with natural language feedback.
Task in Action
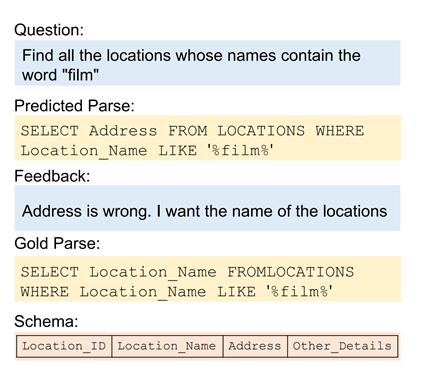
Where is it?
(dataset/code hasn’t dropped yet, be on the lookout)
MSR-LIT/Splash
SPLASH is dataset for the task of semantic parse correction with natural language feedback.The task, dataset along with…
github.com
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
If you enjoyed this article, help us out and share with friends!
For complete coverage, follow our Twitter: @Quantum_Stat
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

