



MLOps 3.3: Data-Centric Approach for Machine learning modelling.
Last Updated on January 21, 2023 by Editorial Team
Author(s): Akhil Theerthala
Originally published on Towards AI.
MLOps 3.3: Data-Centric Approach for Machine Learning Modeling
Hello Everyone! This is Akhil Theerthala, with another installment of my MLOps series. Going back through my old notes, rewriting them, and reading them with fresh eyes has been a fantastic learning experience. Whenever you revisit the notes, I hope you are struck by the same enthusiasm I felt when writing them.
So far in this series, we have seen different phases of a machine learning project and got an overview of deployment and modeling. This is the last article in the series of Modeling, where we expand upon the “Data-centric” approach for modeling and get a high-level overview of what we do differently in this approach.
Let’s first recall what model-centric and data-centric views are. The data-centric approach generally focuses on understanding and optimizing the quality, relevance, and representation of the data used to train the model. In contrast, the model-centric process focuses more on the design and optimization of the model itself rather than the data used for it.
The ultimate goal for both approaches is the same, i.e., to make or model work better on unseen data. However, let’s look into the domains that use the methods. We can quickly identify that academic research is generally done with a model-centric approach, whereas production environments tend to follow a data-centric approach.
One key thing to remember is that we can classify data into two major categories, structured and unstructured. The unstructured data represents images, text, audio, etc., whereas the structured data represents databases, spreadsheets, or similar data. The methods used in the data-centric approach are different for the two types of data. Hence we will look at them separately. First, let us look at the famous method for unstructured data, “Data Augmentation.”
The need for Data augmentation
One way to improve the dataset’s quality is called data augmentation. In this method, we use the existing data, transform it slightly or add some noise to them and use it as an input for the model along with the original data.
To understand this method, let us take an example of a speech recognition system. We can find many types of noise for any speech input. For instance, we can notice,
- Vehicle noise (car/train/plane etc.,)
- Voices of other people
- Background music
- location-specific noise (library/cafe/restaurant)
- Machine noise etc.,
Now, in the list mentioned, there are similar and different kinds of noises. Our original goal was to ensure that the model’s performance was identical to human-level or better.
To evaluate what improves our model, we first need to see where there is a high opportunity for improvement in the model. Consider the following graph for that purpose, where we evaluate the performance of the model on the Y-axis and the X-axis having different kinds of noises based on an assumption of similarity of noises.
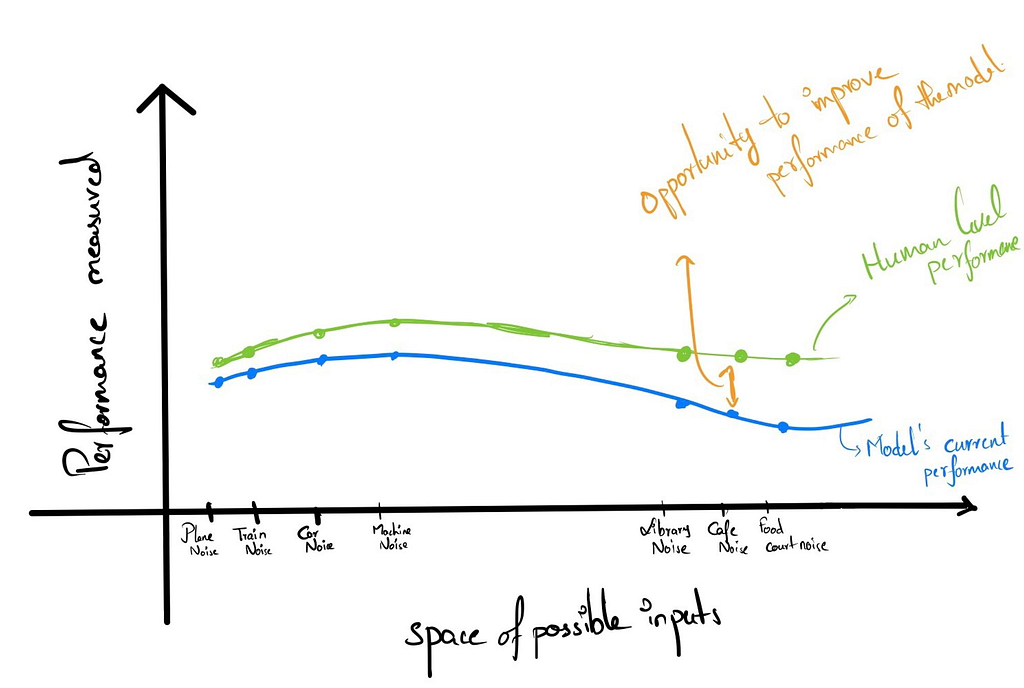
We have assumed that the noises based on the location are more similar to each other than vehicle noises. Hence, we represented them far from each other on the axis. After this, we can see both the HLP and the model performance on these inputs and identify that we can improve the model when we have more inputs at cafes or restaurants.
So, to improve the model’s performance at these inputs, we need more data where there are these kinds of noises. However, taking all the microphone setups and moving to different cafes in your locality is not practical. This is where the role of Data augmentation kicks in.
Note: In unstructured data, when performance in one type of noise improves, there is little chance that performance at other noises will fall, but there is a good chance that performance at relatively close noises will improve.
Data Augmentation
It is one of the efficient ways to get more data for unstructured data. In Data Augmentation, we transform the original data by adding some noise or a few transformations with the goal of (a.) creating realistic examples on which the algorithms perform poorly and (b.) humans do well.
However, there are different parameters that we need to consider before augmenting the data. For speech recognition, one parameter would be the volume of the noise. We cannot select the parameter based on a trial-and-error approach as it would be highly inefficient and time-consuming; hence, we make sure that the data passes through a few checklists before training a model.
The following is an example of a checklist that may be useful:
- Does it sound realistic?
- Is the x→y mapping precise? (labeling and can humans recognize the speech?)
- Is the algorithm currently performing poorly on it?
For images, the augmentation includes steps like,
- Changing the brightness/contrast of the image.
- Random rotation of the subject within a range of angles.
- Artificially edit the images using external tools like photoshop.
- We can also use complex models like GANs to generate desired images, which is overkill in most cases.
Can adding more data hurt the performance?
Can adding more data hurt the performance?
To answer this question, we first need to recall why we add data to the model in the first place. We add data because the model we defined has a high bias, and the model can’t give good results with the existing data. In that case, we add more data to lower the bias.
Now that we have already achieved the low bias and are still adding the data, we should be careful of what data we are adding. For example, in a multi-class task, says the earlier speech recognition, we are trying to add data to one specific class, say cafe noises, such that the existing amount of cafe noise sounds has increased from 10–20% of the data to 40–50% of the data. The rest of the data is not large enough to keep the model from being confused, and adding the data hurts the model. So we have to be more careful when we add the data.
Other than this, there are only case-specific examples where the input-output mappings of 2 different classes are very close to each other, which confuses even humans. Consider small ‘l’ (L) and capital I (i) in some common fonts, like Arial, for reference. This is fine with text models, but it says we are somehow working with images containing text, and we need to help the model distinguish between the two. Another case would be between ambiguous 1s and Is, as shown in the following image.

Data-Centric approach for structured data problems.
For structured data problems, it is often difficult to add new examples. Instead, we try and add new features to the existing data. This can be better illustrated with an example.
Let us define a machine learning model that takes the user data and the nearby restaurant data as inputs, and the goal is to recommend suitable restaurants to the users. Let’s follow a collaborative filtering approach to do that. The recommendations are made based on identifying similar groups of users and recommending the restaurants based on the other’s ratings.
In this approach, we can face difficulties in many areas due to a lack of data. The model we have built mainly recommends based on a person’s neighborhood. However, there are both vegetarians and non-vegetarians in that neighborhood.
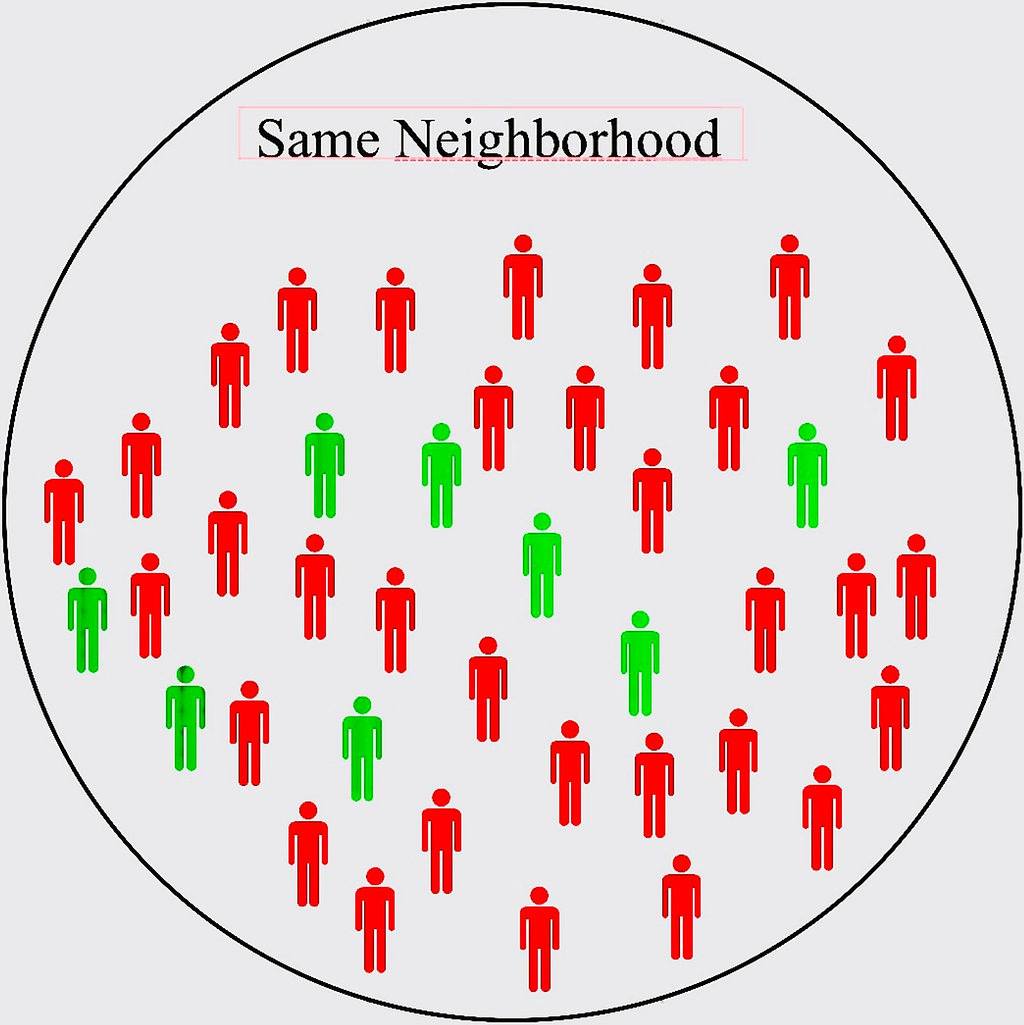
In such a case, we can find that the model predicts the famous non-vegetarian restaurants to vegetarian users just because more people in his locality have highly rated a particular non-vegetarian restaurant. This issue can be tackled in many ways. One way is to synthetically create data about vegetarians similar to the earlier speech recognition model. Another way is to take more data from the existing users and try to find patterns using the new data.
For our problem, it is more practical to use the latter method, as it is easier to collect more data from existing users than to synthetically generate new data for all the neighborhoods in a city. Some of the new data can include a Boolean feature indicating the preference of a person being veg vs non-veg, or it can be a feature about the restaurant and its performance on its vegetarian options.
Now we can use these extra features and train the model to recommend better restaurants to vegetarian users.
⚠️ Over the last few years, we can observe a shift from collaborative filtering to content-based filtering, where we recommend the restaurant based on its menu, description, and other information. This can help even relatively new restaurants that almost no one knows.
Experiment Tracking
When we are running dozens of experiments, it is not easy to remember every experiment that has been done. Hence, it is better to keep track of experiments and their results. There are many aspects of an experiment. However, tracking the essential elements can help us maintain sanity and help us in decision-making. Some of the critical aspects (high level) include,
- Algorithm/code versioning (saving the trained models)
- Dataset used
- Hyperparameters
- Results
These aspects can be tracked in text files, spreadsheets, shared spreadsheets, and other formal experiment tracking systems (Weights and biases, Comet, MLflow, SageMaker studio, etc.). The selection of the tools used depends on the desired features of the project. Some would be,
- Replicability of the experiment results given by the tool
- Tools that help us easily understand the results. (Summary metrics/analysis)
- Resource monitoring, Visualization of the errors, etc.,
It is unnecessary to stress over what tool to use for tracking experiments, but it is better to have some system to track your experiments.
With this, we can conclude our chapter on the Modelling phase of a project. We have seen the standard procedures for developing a machine learning model and finding the defects in the model using error analysis. Finally, we also have looked at the trending Data-centric approach. Through these, we had a lot of time to ponder the implications of different aspects of a model and the dangers of deploying a model without auditing or deploying it.
Next, we will take one more step back and look at the “Data” phase of the Machine learning project lifecycle. I hope you liked the article. If you did, check out the other articles in this series or others!
Thanks for reading till now! Have a nice day!
㊙️If you want to be instantly notified whenever an article is released in this series, you must add your email here.
- MLOps Notes 3.2: Error Analysis for Machine learning models
- MLOps Notes 3.1: An Overview of Modeling for machine learning projects
- MLOps Notes -1: The Machine Learning Lifecycle
MLOps 3.3: Data-Centric Approach for Machine learning modelling. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

