



Introduction to Autoregressive Models
Last Updated on July 25, 2023 by Editorial Team
Author(s): Albert Nguyen
Originally published on Towards AI.
This article is a preparation for the upcoming article about Autoregressive Diffusion Models.
Distribution estimation is a core problem in many Deep Learning applications, including classification, regression, and more. Many estimation methods have been developed, but they quickly become intractable due to the increases in the size of information.
Autoregressive Models are neural network architectures applied to the problem above. It utilizes the probability product rule and a weight-sharing scheme to yield a tractable estimator with good generalization performance. Autoregressive Models have good results in modeling both binary and real-valued observations. It can also be agnostic to ordering input dimensions by the “product rule decomposition”.
Stay with me throughout this article; we will discover how Autoregressive Models (AR) work.
Problem Statement
Not limited to Deep Learning, “distribution estimation” is a problem in many applications. The goal is to estimate the distribution P(x) underlying dataset D. Therefore, the estimated distribution should be close to the actual distribution and tractable. By saying tractable distribution, the distribution has a closed form and is computationally efficient to obtain.
I find this thread and this blog help full to knowing what intractable distribution is. Readers should read through this thread to understand why we want to avoid this.
Why do other methods become intractable?
Before NADE, one of the most popular methods was using directed graphical models or Bayesian networks. The “Bag of words” (BOW) method uses Bayesian networks, a popular NLP tool. It tries to estimate the feature vector x of a sentence s with a vocabulary v. Then we have the estimated x* = [ '#times w in s' for w in v]. The feature vector x has size N = size of the vocabulary v.
This method is quite suitable for text and document classification with small vocabulary sizes. When N increase, x will become too large and requires heavy computations. Also, the assumption on x is that words are independent of position. But they are not just binary and also different in contexts. For example: “Bob likes Alice” and “Alice likes Bob” are entirely different, but they ended up with the same feature vector. General Bayesian Network models like BOW require many assumptions and constraints to be tractable.
Autoregressive Models
Autoregressive Models (ARM) are architectures that rely only on past values to predict current data values. For example, simple ARMs use lagged values p, AR(p) models, to indicate current value based on “p” past values:
Where y_t is the current value of the time series, y_{t-1}, y_{t-2}, …, y_{t-p} are the lagged values of the time series, c is a constant, a_1, a_2, …, a_p are the coefficients of the model, and e_t is the error term. In other words, AR(p) parameterizes the distributions P(y_t U+007C y_{t-1}, …, y_{t-p}). And by that, we have:

These AR models are often used in time-series applications. But they are not just that. Usually, we have to deal with data where we can embed them into a vector x of dimension d. Therefore, we can estimate the distribution of each dimension ‘i’ by the previous dimensions’ values.
In the next section, I will explore the architecture of Neural Autoregressive Models to compute such p(x) in a tractable and efficient way.
Neural Autoregressive Models [1]
NADE is an Autoregressive Model that models the distribution p(x) if the input vector x of dimension D. For any order o (permutation of the integers 1 to D), we have:
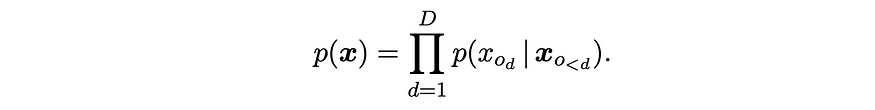
Where o_{<d} is the first d-1 dimensions in o and x_{o{<d}} is the corresponding sub-vector of x. The architecture of simple NADE:
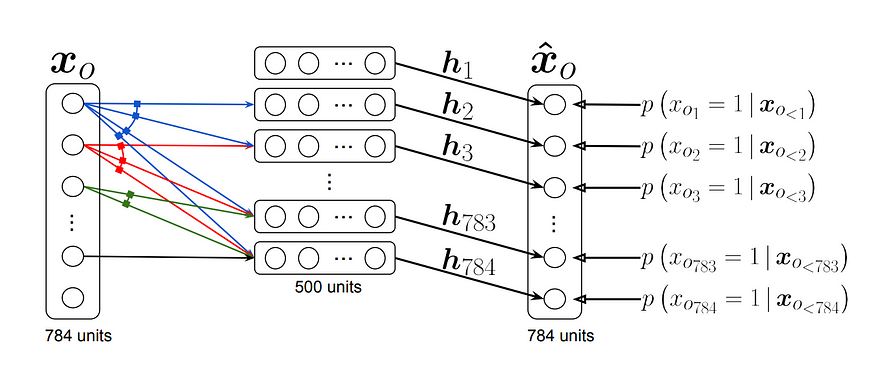
In details, the model parameterises each conditional distribution by a feed-forward neural network. We have:
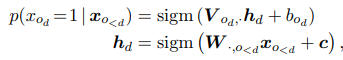
In this figure above, a hidden layer matrix W and bias c are shared by all hidden feature h_d. Then it is used to compute the probability of x_{o_d} via prediction layer V with bias b_{o_d}. The weight sharing scheme for W makes the parameter complexity of the model become O(HD), where H is the hidden vector size and D is the input vector size, rather than O(HD²).
NOTE: The computational complexity for hidden vector h_d is also O(HD) because we can reuse the output of previous computation for h_{d-1}

The model is trained under the following objective:

And usually with SGD optimizer. The log term goes from 0 -> -infinity when P goes from 1 to 0. So, by minimizing this NNL loss, we push P closer to 1. In other words, it increases the accuracy of predicting real value x_{o_d} with x_{o_{<d}}.
Conclusion
Our goal is to have a tractable estimator. Neural Autoregressive models like NADE are more robust to the size of inputs dimension, promising us an efficient computation for distribution estimator. However, we cannot say it is going to guarantee us a tractable estimator and a good estimator as well. AR models work on a strong assumption that the current values rely only on past values. For example, in sentence completion tasks in NLP, we may need to look both backward and forward to get the whole context of the sentences.
Applications and further reading.
Some variants of deep Autoregressive Models:
- PixelCNN
- PixelCNN++
- WaveNet A Generative Model for Raw Audio.
- Transformers: Attention is all you need
These models have been successful in many applications. Especially Transformers have already dominated the AI world for a while. Its success is not just limited to Natural Language Processing (NLP) but also Computer Vision (CV) and more.
The article is only to introduce the concept of the Autoregressive Model. There are also many problems underlying this architecture, such as:
- How does NADE generalize to other data types?
- “Dimension orderless” training procedure for Deep NADE.
- Relation between
I will leave the resources for readers who are interested in diving deeper into AR models.
References
Aaron van den Oord el al. Pixel Recurrent Neural Networks
Aaron van den Oord et al. WaveNet A Generative Model for Raw Audio.
Vaswani et al. Transformers: Attention is all you need
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



