



ICLR 2022 — A Selection of 10 Papers You Shouldn’t Miss
Last Updated on July 26, 2023 by Editorial Team
Author(s): Sergi Castella i Sapé
Originally published on Towards AI.
Hopefully the last big virtual-only AI conference of the year? The International Conference on Learning Representations is here and it’s packed with high-quality R&D: more than a thousand papers, 19 workshops, and 8 invited talks. Where to start? Well, we have some suggestions!
The International Conference in Learning Representations (ICLR) will be held online (for the third year in a row!) from Monday, April 25th through Friday, April 29th. It’s one of the biggest and most beloved conferences in the world of Machine Learning Research, and this year is no exception: it comes packed with more than a thousand papers on topics ranging from ML theory, Reinforcement Learning (RL), Computer Vision (CV), Natural Language Processing (NLP), neuroscience and many more.
Some of them have been around on arxiv.org for a few months and people are already building on them: check out for instance the papers at ICLR that have already been cited when the conference is about to start:
In any case, we wanted to make some sense of this vast lineup of content, we’ve done a deep dive into the conference content to curate this selection of papers that most piqued our interest. Without further ado, here’s our selection!
1. Autoregressive Diffusion Models U+007C U+1F47E Code
By Emiel Hoogeboom, Alexey A. Gritsenko, Jasmijn Bastings, Ben Poole, Rianne van den Berg, Tim Salimans.
Authors’ TL;DR → A new model class for discrete variables encompassing order agnostic autoregressive models and absorbing discrete diffusion.
U+2753 Why → Diffusion Models have been growing in popularity for the past year and they’re gradually being assimilated into the Deep Learning toolbox. This paper proposes a significant conceptual innovation for these models.
U+1F4A1 Key insights → In handwavy terms, Diffusion Models generate images by iteratively adding “differentiable noise” on a pixel grid that eventually becomes a real-looking image. Inference starts by sampling some kind of “white noise” image. This work proposes to do a similar process but instead of applying the diffusion step to iteratively decode all pixels at the same time, they decode a few pixels at a time autoregressively which then remain fixed for the rest of the process (see figure below).

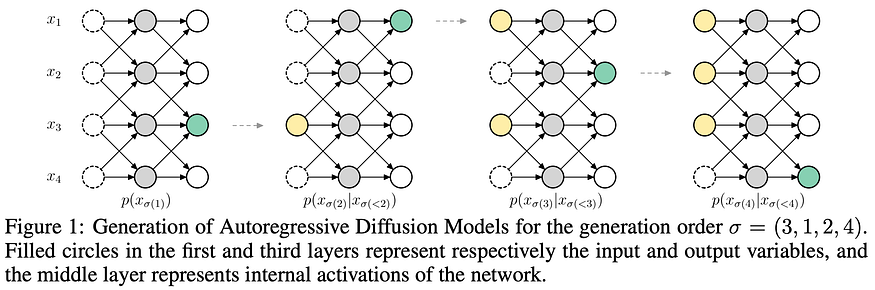
Moreover, in contrast to other autoregressive methods for image generation like DALL·E⁴, this method doesn’t require a particular ordering when decoding the image. Even more, the number of pixels that are decoded at each diffusion step can be dynamically adjusted by the model given a fixed budget of steps for decoding the whole image!
For training, a BERT-like denoising autoencoder self-supervised objective suffices: given an image, masking a portion of the pixels and predicting the value of a few of them. While the results are not earth-shattering, this is conceptually a simple and effective evolution of Diffusion Models that allows them to decode an output autoregressive and be applied to not left-to-right text generation. If you want to dive deeper into this paper, Yannic Kilcher has an excellent explainer video which I highly recommend.
2. Poisoning and Backdooring Contrastive Learning
By Nicholas Carlini, Andreas Terzis.
Authors’ TL;DR → We argue poisoning and backdooring attacks are a serious threat to multimodal contrastive classifiers, because they are explicitly designed to be trained on uncurated datasets from the Internet.
U+2753 Why → Large-scale self-supervised pre-training with data scraped from the web is one of the basic ingredients for training large Neural Networks. For the well-known CLIP² from OpenAI, noisy uncurated image-text pairs from the web are used for training. What could go wrong? Well, this.
U+1F4A1 Key insights → This paper explores how an adversary might poison a small subset of the training data for a model like CLIP — trained using contrastive learning on image-text pairs from the web — such that the model will misclassify test images. They try 2 methods to do so:
- Targeted poisoning: the training dataset is modified by adding poisoned samples with the goal of having the end model misclassify a particular image with a wrong specific label. According to the results, this can be consistently achieved by just poisoning a 0.0001% of the training dataset, e.g. adding 3 image pairs to a dataset of 3 million instances.
- Backdoor attack: instead of having a particular target image, this approach aims to overlay a small patch of pixels on any image such that this will be misclassified with a desired wrong label. This more ambitious attack can be pulled off consistently by poisoning 0.01% of the training dataset, e.g. poisoning 300 images out of a 3 million instances dataset.
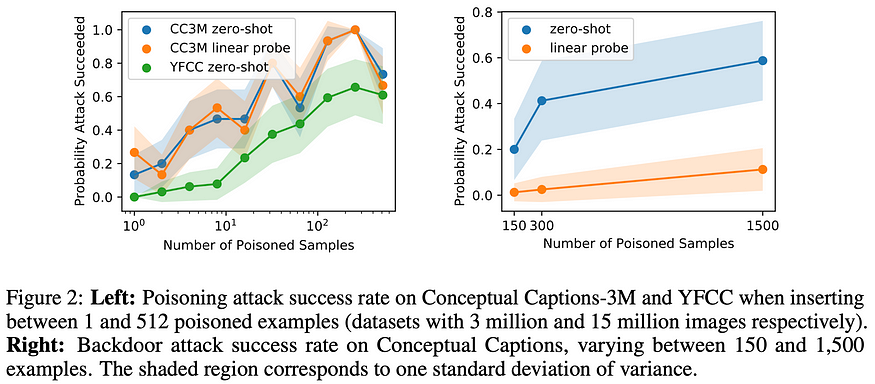
Public internet data can be manipulated by anyone, which makes these attacks feasible. This is yet a new weakness of using uncurated data for training models that should be considered when developing and deploying models.
3. Bootstrapped Meta-Learning
By Sebastian Flennerhag, Yannick Schroecker, Tom Zahavy, Hado van Hasselt, David Silver, Satinder Singh.
Authors’ TL;DR → We propose an algorithm for meta-learning with gradients that bootstraps the meta-learner from itself or another update rule.
U+2753 Why → Many Reinforcement Learning algorithms are notoriously sensitive to hyperparameter choices. Meta-learning is a promising learning paradigm for refining the learning rules of a learner (which include hyperparameters) to make learning faster and more robust.
U+1F4A1 Key insights → In meta-learning, the learner is equipped with an outer loop of optimization that optimizes the “learning rule” of the inner optimization, which directly optimizes a learning objective (e.g. via gradient descent). In terribly oversimplified terms, existing meta-learning algorithms often rely on the performance of the learner to evaluate a learning rule: run the learner for k steps, if the learning improves do more of that, if the learning gets worse, do less of that. The problem with directly using the learner’s objective is that the meta-learning optimization will (1) be constrained to the same geometry of the learning objective function and (2) the optimization will be myopic, given that it will only optimize for a horizon of k steps, whereas the dynamics of learning beyond that might be much more complex.
Frankly, the theoretical details of this process go over my head, but the gist of it is that the meta-learner is first asked to predict the performance of the learner beyond the evaluated k-steps, and then it optimizes following that very prediction; in other words, the meta-learner generates its own target to optimize. This enables the meta-learner to optimize for a longer time horizon without the need to actually evaluate such long time horizons which is computationally expensive.
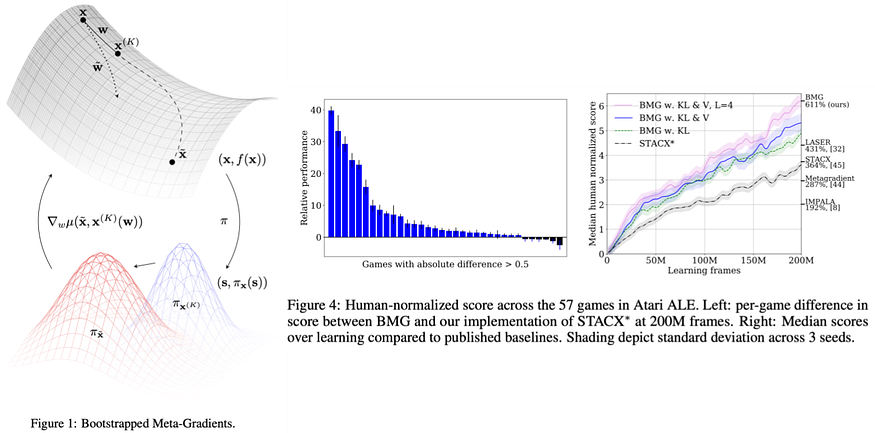
The authors prove some nice theoretical properties of this approach and the empirical results achieve new state-of-the-art (SOTA) on the ATARI ALE benchmark¹ and efficiency improvements in multitask learning.
4. Equivariant Subgraph Aggregation Networks
By Beatrice Bevilacqua, Fabrizio Frasca, Derek Lim, Balasubramaniam Srinivasan, Chen Cai, Gopinath Balamurugan, Michael M. Bronstein, Haggai Maron.
Authors’ TL;DR → We present a provably expressive graph learning framework based on representing graphs as multisets of subgraphs and processing them with an equivariant architecture.
U+2753 Why → The limited expressiveness of Message Passing Neural Networks (MPNNs) on graphs — which fall under the umbrella of Graph Neural Networks (GNNs) — is one of those fundamental problems that prevent GNN researchers from sleeping well at night.
U+1F4A1 Key insights → How do you know if two graphs are the same? You might think just looking at them is enough, but you’d be wrong. The same graph can be represented in different ways by reorganizing or permitting the order of nodes such that given two graphs it can be hard to identify whether they are the same, namely isomorphic.
The Weisfeiler-Leman (WL) test is an algorithm that recursively classifies the nodes of a graph based on its immediate neighborhood. If after all these processes the nodes of the two graphs have “different classifications” this means the test failed, implying the two graphs are different (non-isomorphic). On the other hand, if the two graphs are “still the same” after the WL test, they are probably isomorphic, but it’s not guaranteed! There are certain graph structures the WL test will fail to differentiate.
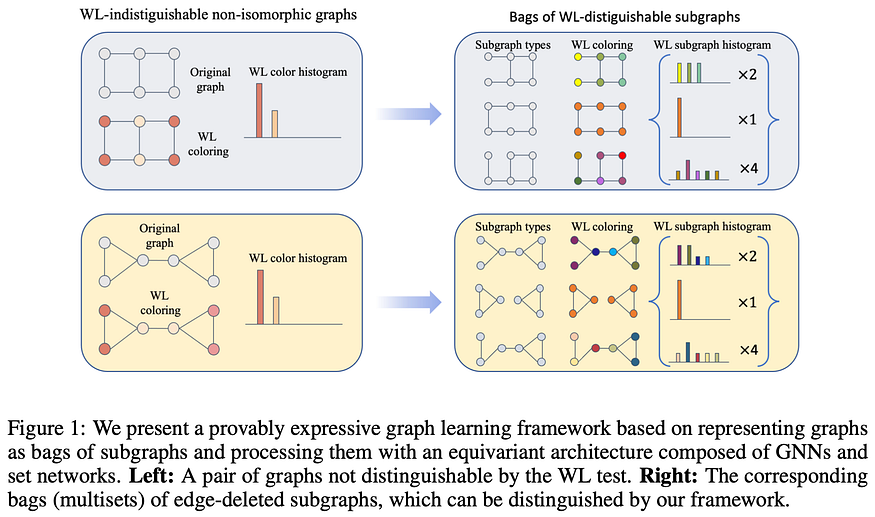
MPNNs GNNs can be understood as a differentiable analog of the WL test, which is why MPNNs inherit the expressiveness limitation of the WL test: they cannot differentiate between certain graph substructures. Even further, depending on how MPNNs aggregate information from their neighbors, they might even have less expressive power than the WL test!
This work establishes all these connections and presents a method for maximizing the expressiveness of MPNNs which consists in decomposing a graph into a bag of subgraphs and applying MPNNs on these bags of subgraphs. The paper is fairly dense, but if you want to get the gist of the paper or are interested in starting to learn about GNNs, I strongly recommend the ML Street Talk episode with Zak Jost where they cover the paper starting on minute 47.
Other GNN works at ICLR: Graph Neural Networks with Learnable Structural and Positional Representations
5. Perceiver IO: A General Architecture for Structured Inputs & Outputs
By Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, Joāo Carreira.
Authors’ TL;DR → We propose Perceiver IO, a general-purpose architecture that handles data from arbitrary settings while scaling linearly with the size of inputs and outputs.
U+2753 Why → Modeling data by making the fewest possible assumptions about it is interesting because it has the potential to transfer well to different modalities.
U+1F4A1 Key insights → This work follows a similar line as the original Perceiver³ by augmenting it with a flexible querying mechanism which lets the model have an output of arbitrary size instead of requiring a task-specific architecture at the end of the model. that enables outputs of various sizes and semantics, doing away with the need for task-specific architecture engineering.
The overview of the model can be understood by looking at the figure below: the input can be an arbitrarily long sequence of embeddings that are mapped into a latent array encoding. This process allows for modeling very long input sequences, given that the latent array size is fixed, there’s no quadratic complexity exploding when the input becomes very long. After this “encoding step” the model applies the common L transformer blocks consisting of a combination of self-attention and feedforward layers. Finally, a decoding step takes in an output query array and combines it with the latent representation of the input to produce an output array of the desired dimension.
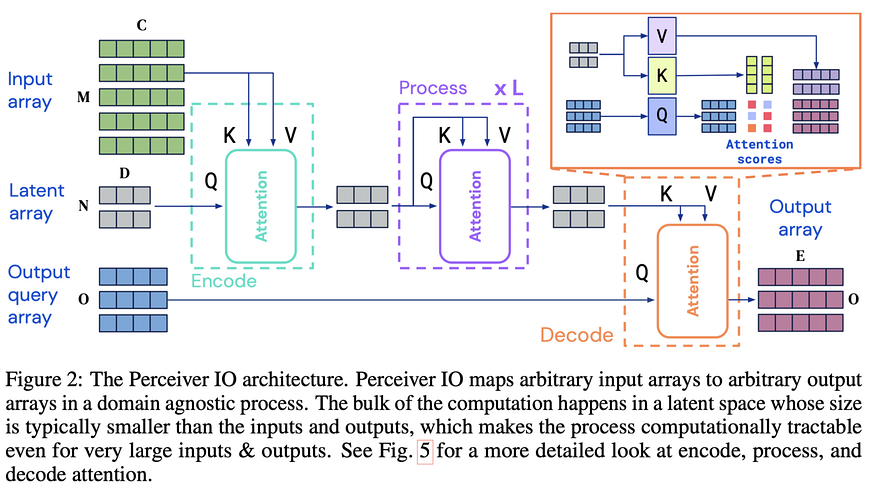
Many of the existing learning techniques such as Masked Language Modeling or contrastive learning can be also applied to this architecture. Following common existing recipes for training on each modality, this model produces strong results in NLP and visual understanding, multi-task and multi-modal reasoning, and Optical Flow. Hell, they even plug it into AlphaStar (replacing the existing Transformer module) achieving strong results in the challenging StarCraft II game!
If you're interested in this research you should check out the more recent version of the Perceiver, the Hierarchical Perceiver⁷.
6. Exploring the Limits of Large Scale Pre-training
By Samira Abnar, Mostafa Dehghani, Behnam Neyshabur, Hanie Sedghi.
Authors’ TL;DR → We perform a systematic investigation of limits of large scale pre-training for few-shot and transfer learning in image recognition with a wide range of downstream tasks.
U+2753 Why → Scale has been a persistent topic of discussion within ML circles. We have been highlighting papers often because it is definitely one of the important questions the field has to grapple with: where will adding parameters and data stop being… useful? Keep reading.
U+1F4A1 Key insights → Sort of pretty much “As we increase the upstream accuracy, the performance of downstream tasks saturates”.
They study how pre-training performance on Upstream (US) tasks (e.g. large-scale ImageNet labels) transfers to Downstream (DS) performance (e.g. whale detection). Then do this experiment for a lot — by a lot mean a lot — of architectures and sizes:
“4800 experiments on Vision Transformers, MLP-Mixers and ResNets with number of parameters ranging from ten million to ten billion, trained on the largest scale of available image data”.
So the interesting plots represent how Upstream performance (US, pretraining) and Downstream performance (DS, end task) correlate. Pretty much across the board, it saturates eventually. Still, it’s super interesting to see the differences across architectures for computer vision!
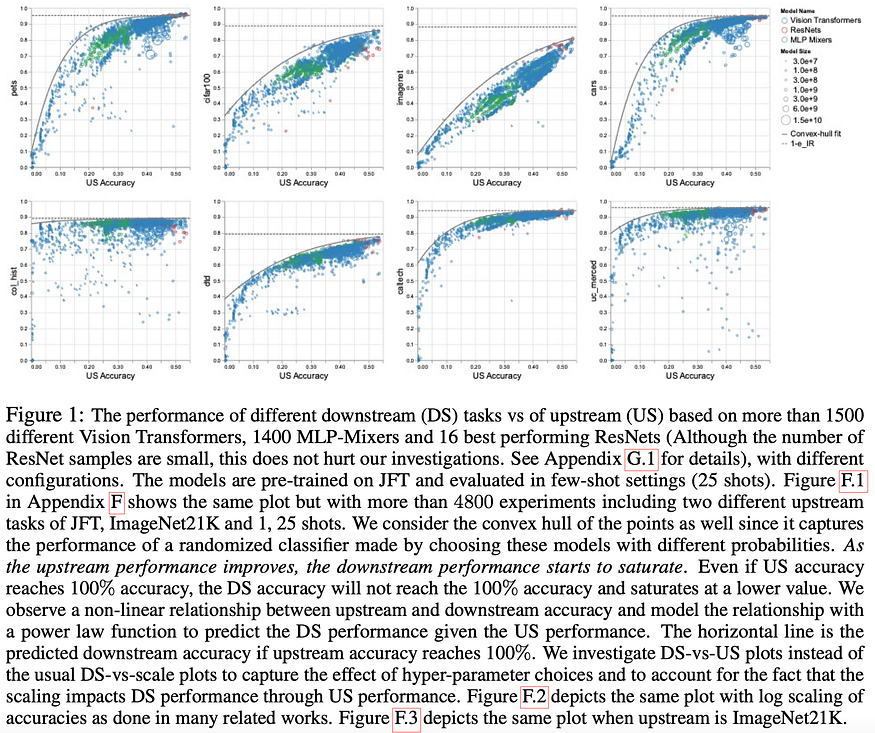
The authors claim that their observations overall seem robust to choices such as the size of the upstream data or number of training shots, and architecture choices. They also explore the influence of hyper-parameter choices: are some hyper-parameters very good for the US but don’t translate well to DS? Yes! They dive deep into this phenomenon in section 4 and find that for instance, weight decay is a particularly salient hyperparameter that influences US and DS performance differently.
In a context where nobody really trains models from scratch but chooses pre-trained models to bootstrap their application, this research is key. There’s much more to the paper than what can be summarized in a few paragraphs, it’s definitely worth a read if you want to dive deeper!
7. Language modeling via stochastic processes
By Rose E Wang, Esin Durmus, Noah Goodman, Tatsunori Hashimoto.
Authors’ TL;DR → We introduce a language model that implicitly plans via a latent stochastic process.
U+2753 Why → Modern large generative Language Models are wickedly good at writing short texts, but when they generate a long text, global coherence is often lost and things stop making sense. This paper proposes a method to mitigate this.
U+1F4A1 Key insights → Typical Language Models (LM) generate text solely at the token level of granularity, which heavily biases models to learn about short-range interactions more heavily than long-range ones, which is precisely the skill required for achieving a coherent global narrative. This work proposes to model language at the coarser level of sentences as a stochastic process that guides the LM generation to be globally coherent.
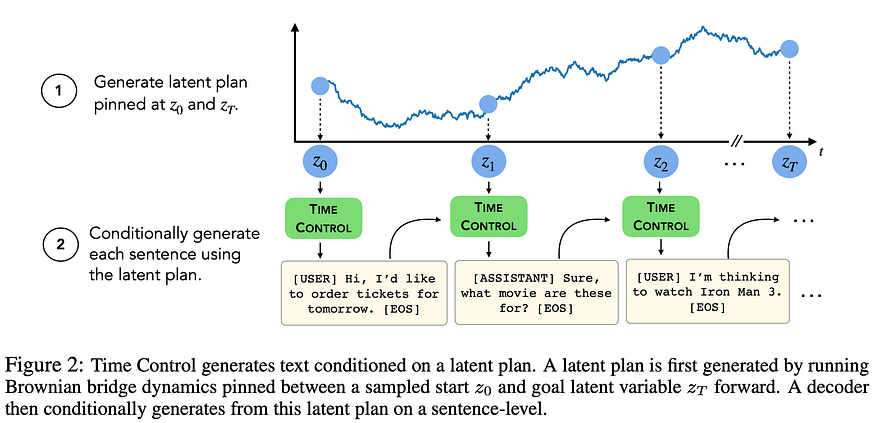
The proposed model is called Time Control and it models sentence representations as Brownian motion in the latent space. For training, given two start and end anchor sentences, a contrastive loss is set up by having a positive sentence that’s within the anchor sentences to fall within the “Brownian bridge” of the anchor sentence representations in the latent space, and then having negative samples be pushed out (Figure 1). I also didn’t know what a Brownian bridge was before: a Brownian (jiggly) trajectory where the start and end positions are fixed.
For inference, a sentence-level plan is generated by sampling from the Brownian process in the latent space, and then language at the token level is generated conditioned by this high-level plan (Figure 2).

The results are very interesting, particularly in Discourse coherence accuracy, where Time Control shines. This work presents a promising direction to get LMs to overcome classical limitations without the need of going to the Trillion parameter scale regime.
Other relevant works on Language models at ICLR are (FLAN) Fine-tuned Language Models are Zero-Shot Learners, Multitask Prompted Training Enables Zero-Shot Task Generalization, Charformer: Fast Character Transformers via Gradient-based Subword Tokenization, GreaseLM: Graph REASoning Enhanced Language Models, HTLM: Hyper-Text Pre-Training and Prompting of Language Models or Fine-Tuning Distorts Pretrained Features and Underperforms Out-of-Distribution.
8. Coordination Among Neural Modules Through a Shared Global Workspace
By Anirudh Goyal, Aniket Didolkar, Alex Lamb, Kartikeya Badola, Nan Rosemary Ke, Nasim Rahaman, Jonathan Binas, Charles Blundell, Michael Mozer, Yoshua Bengio.
Authors TL;DR → Communication among different specialist using a shared workspace allowing higher order interactions.
U+2753 Why → Brain-inspired modular neural architectures are on the rise; despite their lack of success on popular Computer Vision or Natural Language Processing benchmarks, they’re showing promising results in robustness, out-of-domain generalization, and even learning causal mechanisms⁶.
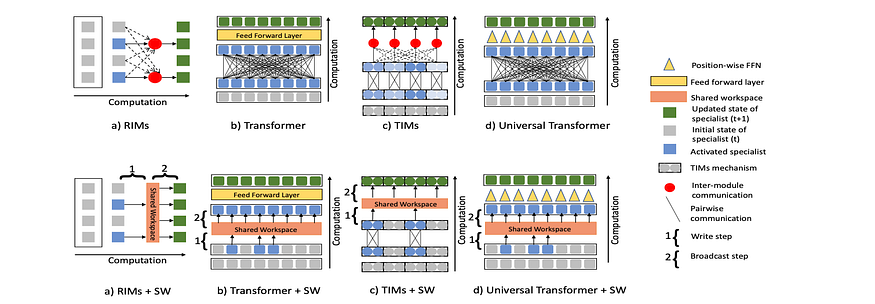
U+1F4A1 Key insights → The Global Workspace Theory (GWT) is a proposed cognitive architecture to account for how conscious and unconscious thought processes manifest in humans. One of its core assumptions is the existence of a shared workspace that all specialist modules have access to, enabling coherence between otherwise isolated modules. This paper conceptualizes a neural network architecture where a set of inputs are processed by expert neural networks, which are then written into a shared workspace — a set of vectors — which are then broadcasted to the experts again.
This might sound fancier than it actually is. For instance, imagine a Transformer that processes an input sequence, you can conceptualize position-wise operations as the experts. The shared workspace imposes a condition on how many of the updated hidden states are allowed to be updated in the shared global workspace, imposing a degree of sparsity, which has been shown to improve robustness and out-of-domain generalization.
As usual with these kinds of works, they perform well on tasks and evaluation modes that are not that popular but won’t outperform monolithic networks on in-domain evaluation, so they won’t make it into many headlines. Still, this is a very interesting line of work worth paying attention to.
Other ICLR work on new architectures for OOD generalization: Compositional Attention: Disentangling Search and Retrieval, Adaptive Control Flow in Transformers Improves Systematic Generalization, Asymmetry Learning for Counterfactually-invariant Classification in OOD Tasks, Sparse Communication via Mixed Distributions.
9. Learning Fast, Learning Slow: A General Continual Learning Method based on Complementary Learning System
By Elahe Arani, Fahad Sarfraz & Bahram Zonooz.
Authors’ TL;DR → A dual memory experience replay method which aims to mimic the interplay between fast learning and slow learning mechanisms for enabling effective CL in DNNs.
U+2753 Why → The dichotomy in human modes of thinking — fast and slow — popularized by Daniel Kahneman is at the core of how humans appear to think. This paper takes inspiration from this idea to build an architecture that leverages fast and slow learning to improve Continual Learning.
U+1F4A1 Key insights → Continual Learning is a method for having a model gradually extend its knowledge by exposing it to new data or interacting with a dynamic environment. As an example, think about a model that initially only learns to classify images with digits from 0 to 7, and is taught to recognize digits 8 and 9, without forgetting about the previous digits. The goal is to be able to leverage existing knowledge to learn more efficiently about new things, just like humans do.
To do so, this paper proposes a memory experience replay system aimed at 2 timescales: long and short. One of the main innovations is the use of semantic memory: two neural networks which represent the plastic and stable model. To enable fast and short learning, the stable model consists of an exponential moving average of the fast model: this makes the two models have coherent weights but the evolution of the stable model is slower and smoother than the plastic one, which is more sensitive to the latest data. This technique has been used in other settings such as contrastive learning like BYOL⁵. The reservoir acts as an episodic memory that retains samples of the data stream which mitigates catastrophic forgetting.
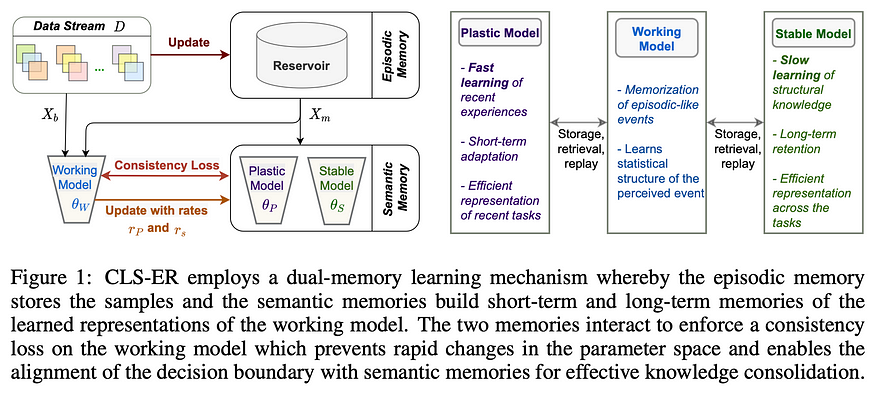
The experiments show strong performance on 3 tasks:
- Class Incremental Learning: gradually adding new classes in a classification setting.
- Domain Incremental Learning: introducing a distribution shift of the data without adding new classes.
- General Incremental Learning: exposing the model to both new class instances and swift distribution shits of the data like rotating digits in an MNIST classification task.
10. Autonomous Reinforcement Learning: Formalism and Benchmarking
By Archit Sharma, Kelvin Xu, Nikhil Sardana, Abhishek Gupta, Karol Hausman, Sergey Levine, Chelsea Finn.
U+2753 Why → Most RL benchmarks are episodic: agents learn by performing a task in an environment that fully restarts every time the agent fails. Humans rarely learn in this setting: the environment doesn’t restart when we re-try to do something! If robots are meant to be in the real world, why do we still evaluate most RL algorithms in episodic benchmarks?
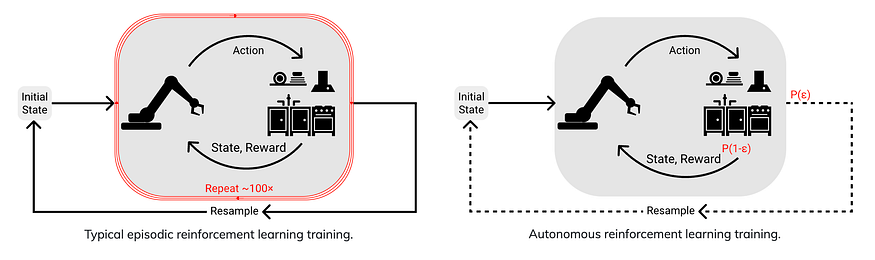
U+1F4A1 Key insights → This work proposes a benchmark that focuses on non-episodic RL which the authors call Environments for Autonomous Reinforcement Learning (EARL) with the hope that it resembles the real world.
Technically, EARL is a subset of the good old RL in which the environment continuously evolves as the agent interacts with it instead of resetting at the end of each episode. However, this is rarely done in practice so this work sets the foundation by establishing the formalisms (e.g. definitions and mathematical formulations of concepts like learning agent, environment, reward, policy evaluations, interventions, etc.).
You can find an overview of this work on their project page and already start using the benchmark to evaluate your algorithms by cloning the benchmark repository from GitHub.
Another popular RL paper at ICLR you might like is Maximum Entropy RL (Provably) Solves Some Robust RL Problems.
Here’s where my selection ends, unfortunately, I couldn’t include many interesting works that were absolutely worthy of highlighting, so you’ll need to dive into the full list of conference papers to find them.
References
[1] “The Arcade Learning Environment: An Evaluation Platform for General Agents” by Marc G. Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling; 2012.
[2] “Learning Transferable Visual Models From Natural Language Supervision” by Alec Radford et al. 2021.
[3] “Perceiver: General Perception with Iterative Attention” by Andrew Jaegle et al. 2021.
[4] “Zero-Shot Text-to-Image Generation” by Aditya Ramesh et al. 2021.
[5] “Bootstrap your own latent: A new approach to self-supervised Learning” by Jean-Bastien Grill et al. 2020.
[6] “Recurrent Independent Mechanisms” by Anirudh Goyal et al. 2021.
[7] “Hierarchical Perceiver” by Joao Carreira et al. 2022.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

