



How To Build an NLP Pipeline On AWS
Last Updated on July 26, 2022 by Editorial Team
Author(s): Yingjie Qu
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Learn how to deploy NLP code on a virtual machine
This summer, I have been working as a Data Science Intern at a local company in the US. An important project I have been working on with four colleagues is about building a Cloud-based pipeline to automatically extract the most relevant discussed topics on a daily basis from 50,000 tweets.
In this article, I will explain the main steps that you will need to follow to create a similar project hosted on AWS.
Why use the Cloud?
If you have not started studying how to use the Cloud yet, you have likely made all your projects local. This is not an issue when you have lightweight software that you want to run at your will, however, if you want something that runs on a daily schedule, it needs to be hosted somewhere else. For this very purpose, we can rent services on the Cloud from one of the main Cloud Providers (in our case, AWS), so our software will not need our personal computer when running.
Project Outline
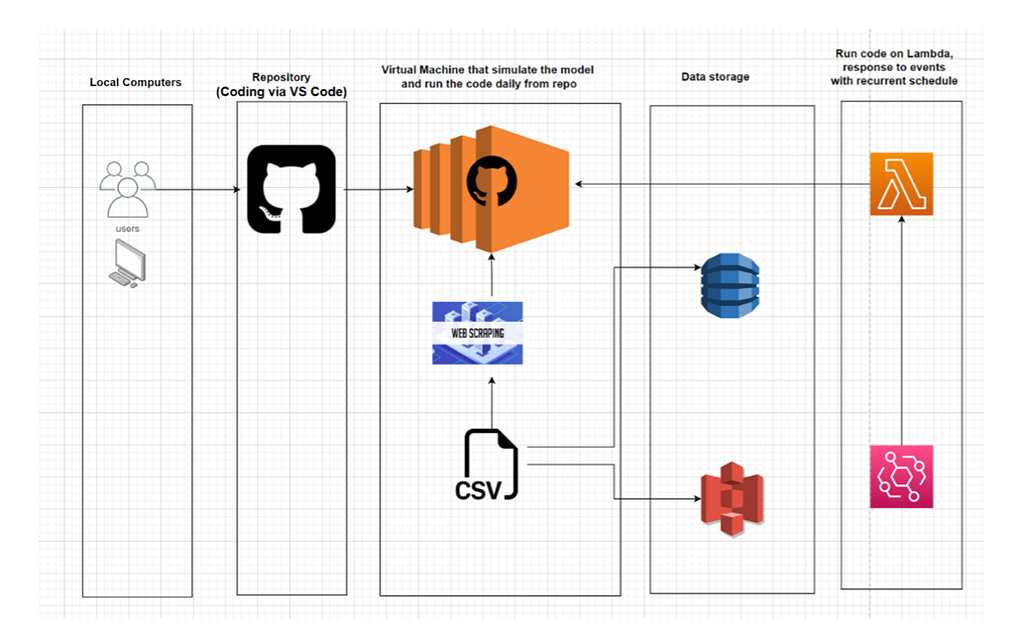
The project we are going to do will follow this architecture and will be organized in the following steps:
- Setting up the virtual machine
- Writing the python code
- Scraping tweets
- Topic modeling
- Clustering
- Data Visualization
3. Scheduling the pipeline to run daily
On Hands!
If you are trying to follow these steps to create a similar project, make sure that you already have an AWS account.
1. Set up a virtual machine
A virtual machine is a simulated computer you can rent from the Cloud (and that you can pay as little as 0,04 USD/h) that enables you to run your code. The AWS service you will need to use to set up a VM is called EC2.
For my experiment, I will be using a t2.small because it is the smallest instance where I can install one of the main libraries I am going to use: sentence-transformers. Depending on your code, you can even rent smaller EC2 instances, like t2.nano or t2.micro, that cost relatively less.
Amazon Web Services, Inc. (AWS) provides individuals, companies, and governments with cloud computing platforms to perform various web services as necessary. The AWS Cloud has many outstanding features, including high scalability, high elasticity, high availability, and so on.
A virtual machine is a type of computer system that is completely virtualized, unlike any physical server. A virtual machine “borrows” its CPU and memory from either a remote server, such as AWS or from a physical computer. Not only is it quite useful in running applications and code that can not run on local computers, it can also back up users’ current operating systems.
2. Write up the python code
a. Web Scraping
The library of snscrape is used for web scraping, where users can download large numbers of tweets from Twitter based on the topic and time range they specify with Python. In our case, we focus on the topic of Covid-19 due to its huge impacts on society as a global pandemic, and we have scraped 50,000 tweets in total.
b. Topic Modelling
Topic Modeling is a statistical modeling method that abstracts “topics” within a set of documents.
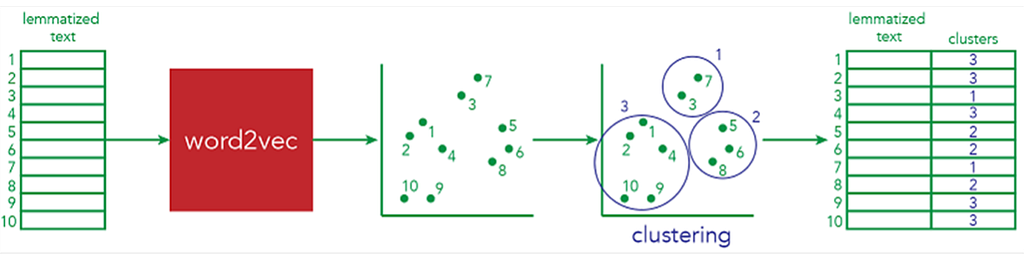
Firstly, data are retrieved and saved in a CSV file so that each sentence falls in one line. Then the methodology of encoding is applied to convert each sentence into a coordinate in space. Next, clustering methods are deployed to label each point in space into a specific group. Finally, all points are visualized in space.
To perform encoding, we are going to use a library called Sentence-Transformers, which takes text as input and outputs a multidimensional vector. After encoding, each sentence has been converted to a coordinate in space with the dimension being 768. By applying clustering to all our vectorized data, we can identify all the groups that share similar content: basically, we are able to extract all trends/topics from our tweets.
Because we want to perform simple clustering, we are using K-Means with a reference number of 200 clusters for all our tweets.
d. Data Visualization
The final step is visualizing data in a clear manner. An important step is dimension reduction from 768 to 2 (using Umap as a dimensionality reduction algorithm), since it is impossible to visualize vectors of dimensions larger than 3, we decide to visualize the result on a X-Y plane with Plotly.
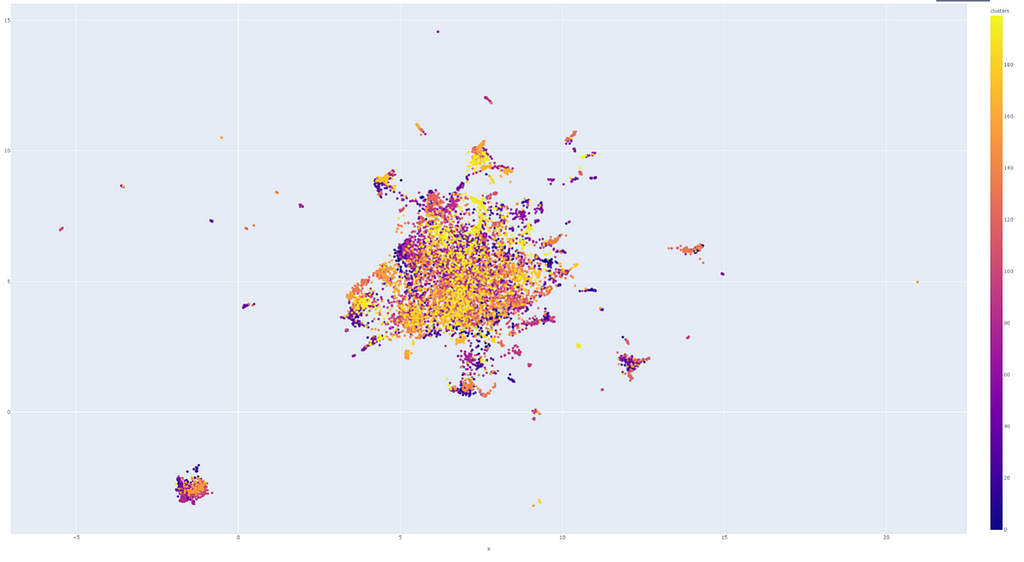
On the resulting graph, each point is labeled with a particular color, indicating their group identities. In this case, there are 200 groups in total.
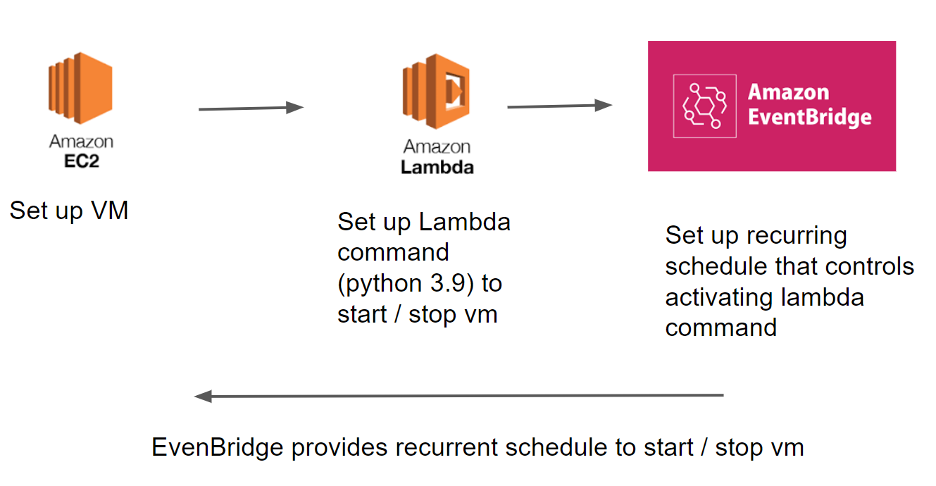
3. Schedule the VM to run daily
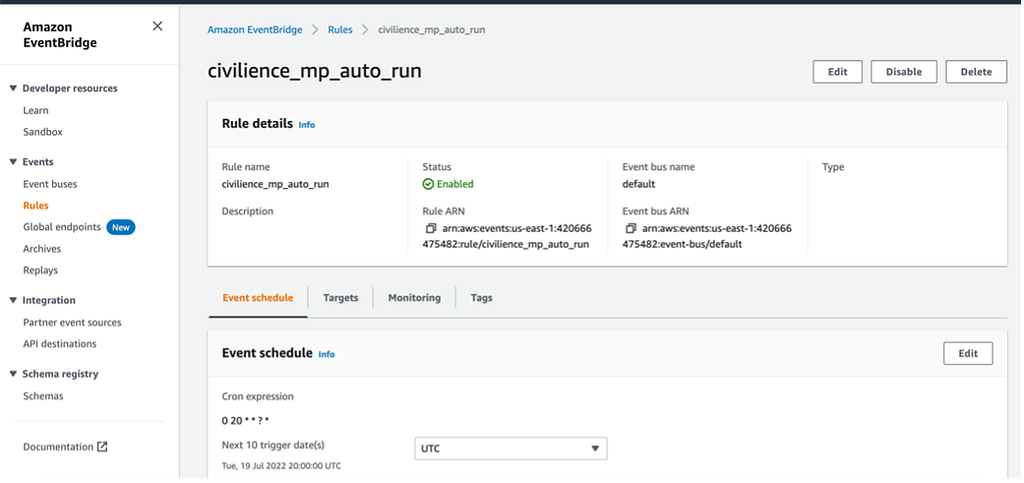
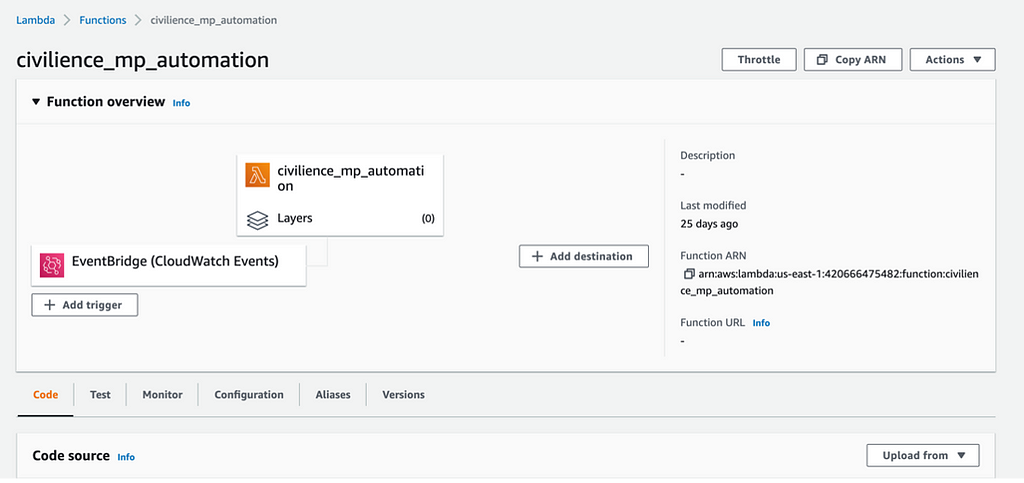
To schedule the virtual machine to run daily, Lambda and EventBridge are two web services on AWS that were deployed to activate and close the Virtual Machine automatically. In particular, Lambda commands are used to start and stop the virtual machine, while EventBridge assists Lambda in setting up a recurring schedule that triggers the lambda command.
How To Build an NLP Pipeline On AWS was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

