



From Classification to Ordinal Regression
Last Updated on September 13, 2022 by Editorial Team
Author(s): Topaz Gilad
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Unlock the Potential of Your Labels
“Is a lion closer to be a giraffe or an elephant?”
It is a question no one asked. Ever. Classifying lions, elephants and giraffes is a straightforward classification task. As such, it can be mostly addressed with a cross-entropy loss. Should the task of classifying someone as a child/adult/elderly be addressed in the same way?
In this blog post, we will overview best practice approaches and papers for:
(1) Addressing ordered classification.
(2) Coarse classification labels into regression continuous predictions.
(3) How to choose.
(4) How to evaluate.
The papers reviewed in this post focus on deep learning models, but the main concepts apply and may be adapted for other ML architectures as well.
Discrete Labels in a Continuous World
“The world is continuous, but the mind is discrete.”
– David Mumford, ICM 2002
We often define categories when breaking down a real-world problem into an ML-based solution. However, real target values may be continuous or at least ordered. This is something to consider and even leverage in the design of your ML model. Are you facing what seems as a classification problem? Take a moment to understand the hidden relations between your “classes”.
Let’s list some classification examples:
– Online ratings: 1–5 stars.
– Medical diagnosis index — stage 1/2/3.
– Face pose estimation [1] — 45/90/180 degrees.
– Age estimation and so on.
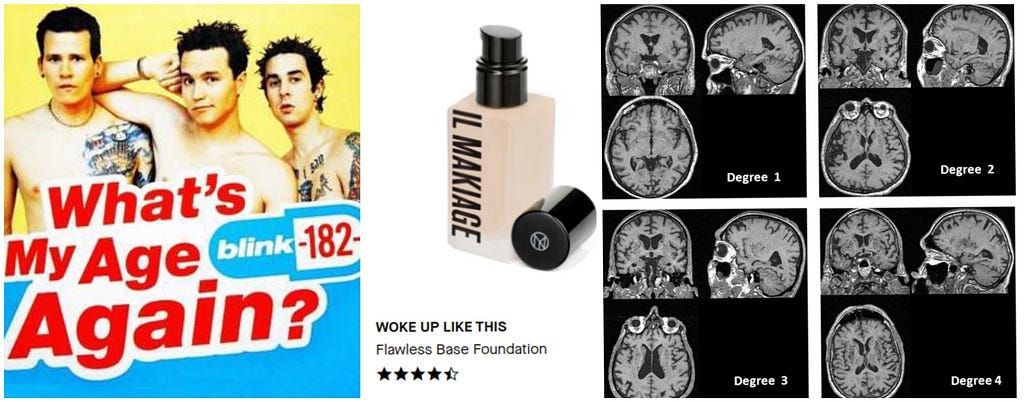
Know Your Data
Approaching the design of an ML solution, some of the first steps are :
(a) Understand what data you currently have / what data you are likely to obtain in a reasonable time. In some cases, you will have continuous measurements associated with your data. For example, blood measurements or information on exact age. More often than not, those will not be available. Manual annotation of fine-grained labels is an extremely difficult and time-consuming task. Therefore, in many cases, all you will have are coarse categorical labels. Especially where an expert human opinion is required.
(b) Explore the domain. Ask your data domain expert to clarify the relations between the target classes. Every bit of prior knowledge or assumptions they assume. Question the format of the output they ask for. For example: Can a smooth real number between 0 to 1 be a better product use than a failed/passed/excellent student score predictor?
If your classes are indeed independent, this is not the blog post for you!
However, if they are dependent, ask yourself:
(1) Do the labels have an order?
(2) Do you only care about the order, or are some labels closer to their nearest labels than others? Are the “steps” of distances between labels uniform?
Regression to the Rescue
Logistic Regression
Most are familiar with logistic regression to discriminate between classes. While the target labels are discrete, the estimated class confidence is continuous.
Let’s consider the following case: The consequences of wrongly classifying class A as class B is not as severe as a mistake between A and C. One approach can be to use a weighted loss with the risk coefficient of each type of mistake [2].
Ordinal Regression
Another approach can be to encode the one-hot vector labels differently, as suggested in the NNRank paper [3]. For a hands-on example, I recommend Gruber’s post and Kotwani’s. Note that if modeling as an aggregation of an ensemble of binary classifiers, inconsistencies in class predictions may occur. Cao et al. 2020 CORAL suggest a solution to achieve consistency of rank [4].
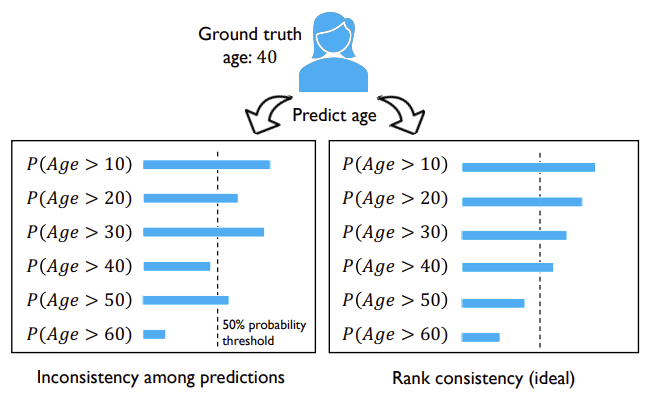
Linear Regression — Seeing Beyond the Available Labels
Netflix launched lately a double thumbs up. By that, they expanded the 3 (dislike/indifferent/like) into 4 categories. This is a better distinction inside what used to be the “liked” category: liked vs. liked a lot. Imagine you have many coarse “liked” votes from the past and only a few new “double thumbs” votes. Estimating a score of user satisfaction (instead of a class) gives you better adaptivity to the new user inputs.
Qin et al BioeNet 2020 showcases a strategy to leverage coarse labels into a fine-grained linear regression [5]. One of the important things to consider when taking that path is to evaluate your inner-class order. We will discuss next how.

Another possible benefit of transforming your discrete integer target labels into real numbers is the positive effect of soft labels. As shown by the Google Brain team (2020), using soft labels not only reduced over-confidence but also improved the calibration even without temperature scaling [6–8].
Make Sure You Are in the Right Direction
Shape and Location of Clusters
I am a big believer in the analysis of your DNN embedded feature space. Create a T-SNE of your test set feature space. Follow the illustrations in the figure below. With a cross-entropy loss, you expect each cluster to condense (minimize inner-class variance) and move away from one another (maximize intra-class variance). However, in ordinal regression, you expect to see the clusters in the right order of proximity in the feature space. For linear regression with an MSE loss, for example, you will not only expect to see the right order but also a continuous order between classes with less margin from one cluster to the next. If you still do see a noticeable margin, this may also indicate your test set is lacking border examples.
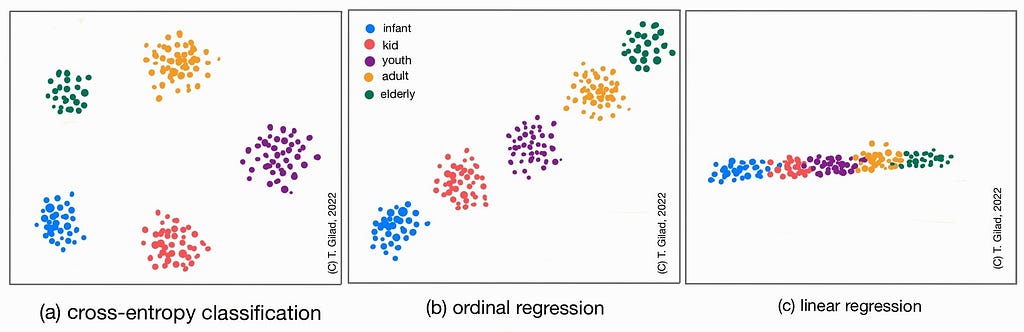
Relations Between Samples from the Same Category
If you can get your hands on a few finer-grained labeled samples, you can use them as a test set to see if your model generalizes well enough in the right inner-class order. For example, imagine you are trying to estimate the age of a person, but the massive amount of labeled data you have are coarse labels (0–3/4–14/teens/20 something/30 something and so on). If you have a few samples of people from the same “age bucket” but with data of exact age label (say age 4, age 8, age 14), check if their locations in the feature space are ordered correctly and that the output predictions are ordered as you expect.
Bottom Line
Think about the relations between your target classes. They may be dependant or ordered.
Consider the different types of regression to gain more from your labels.
Visualize your feature space and test also the inner-class order of predicted outputs.
While when given a set of small possible classes, the classification approach may seem an obvious direction to go, considering the relation between the classes is key to boosting your ML and sometimes may be critical for success!
References
[1] Beyer, L., Hermans, A. and Leibe, B., 2015, October. Biternion nets: Continuous head pose regression from discrete training labels. In German Conference on Pattern Recognition (pp. 157–168). Springer, Cham.
[2] Polat G, Ergenc I, Kani HT, Alahdab YO, Atug O, Temizel A. Class Distance Weighted Cross-Entropy Loss for Ulcerative Colitis Severity Estimation. arXiv preprint arXiv:2202.05167. 2022 Feb 9.
[3] Cheng, J., Wang, Z. and Pollastri, G., 2008, June. A neural network approach to ordinal regression. In 2008 IEEE international joint conference on neural networks (IEEE world congress on computational intelligence) (pp. 1279–1284). IEEE.
[4] Cao, W., Mirjalili, V. and Raschka, S., 2020. Rank consistent ordinal regression for neural networks with application to age estimation. Pattern Recognition Letters, 140, pp.325–331.
[5] Qin, Z., Chen, J., Jiang, Z., Yu, X., Hu, C., Ma, Y., Miao, S. and Zhou, R., 2020. Learning fine-grained estimation of physiological states from coarse-grained labels by distribution restoration. Scientific Reports, 10(1), pp.1–10.
[6] Müller, R., Kornblith, S. and Hinton, G.E., 2019. When does label smoothing help? Advances in neural information processing systems, 32.
[7] Guo, C., Pleiss, G., Sun, Y. and Weinberger, K.Q., 2017, July. On calibration of modern neural networks. In International conference on machine learning (pp. 1321–1330). PMLR.
[8] Minderer, M., Djolonga, J., Romijnders, R., Hubis, F., Zhai, X., Houlsby, N., Tran, D. and Lucic, M., 2021. Revisiting the calibration of modern neural networks. Advances in Neural Information Processing Systems, 34, pp.15682–15694.
[6] Müller, R., Kornblith, S. and Hinton, G.E., 2019. When does label smoothing help? Advances in neural information processing systems, 32.
[7] Guo, C., Pleiss, G., Sun, Y. and Weinberger, K.Q., 2017, July. On calibration of modern neural networks. In International conference on machine learning (pp. 1321–1330). PMLR.
[8] Minderer, M., Djolonga, J., Romijnders, R., Hubis, F., Zhai, X., Houlsby, N., Tran, D. and Lucic, M., 2021. Revisiting the calibration of modern neural networks. Advances in Neural Information Processing Systems, 34, pp.15682–15694.
From Classification to Ordinal Regression was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

